Pertama kali diperkenalkan di SQL Server 2017 Enterprise Edition, gabungan adaptif mengaktifkan transisi waktu proses dari penggabungan hash mode batch ke mode baris loop bersarang yang berkorelasi, gabungan terindeks (berlaku) pada waktu proses. Untuk singkatnya, saya akan merujuk ke “gabungan terindeks loop bersarang berkorelasi” sebagai berlaku sepanjang sisa artikel ini. Jika Anda memerlukan penyegaran tentang perbedaan antara loop bersarang dan penerapan, silakan lihat artikel saya sebelumnya.
Apakah transisi gabungan adaptif dari gabungan hash untuk diterapkan pada waktu proses bergantung pada nilai berlabel Baris Ambang Adaptif di Gabung Adaptif pelaksana rencana eksekusi. Artikel ini menunjukkan cara kerja gabungan adaptif, menyertakan detail penghitungan ambang batas, dan mencakup implikasi dari beberapa pilihan desain yang dibuat.
Pengantar
Satu hal yang saya ingin Anda ingat di seluruh bagian ini adalah penggabungan adaptif selalu mulai dijalankan sebagai gabungan hash mode batch. Ini benar bahkan jika rencana eksekusi menunjukkan gabungan adaptif yang diharapkan berjalan saat mode baris berlaku.
Seperti hash join lainnya, adaptif join membaca semua baris yang tersedia pada input build-nya dan menyalin data yang diperlukan ke dalam tabel hash. Ragam mode batch dari hash join menyimpan baris-baris ini dalam format yang dioptimalkan, dan mempartisinya menggunakan satu atau lebih fungsi hash. Setelah input build digunakan, tabel hash terisi penuh dan dipartisi, siap untuk hash join untuk mulai memeriksa kecocokan baris sisi probe.
Ini adalah titik di mana gabungan adaptif membuat keputusan untuk melanjutkan dengan gabungan mode batch atau beralih ke mode baris berlaku. Jika jumlah baris dalam tabel hash kurang dari ambang nilai, bergabung beralih ke berlaku; jika tidak, join akan berlanjut sebagai hash join dengan mulai membaca baris dari input probe.
Jika transisi ke gabungan penerapan terjadi, rencana eksekusi tidak membaca ulang baris yang digunakan untuk mengisi tabel hash untuk mendorong operasi penerapan. Sebagai gantinya, komponen internal yang dikenal sebagai pembaca buffer adaptif memperluas baris yang sudah disimpan di tabel hash dan membuatnya tersedia sesuai permintaan ke input luar dari operator apply. Ada biaya yang terkait dengan pembaca buffer adaptif, tetapi jauh lebih rendah daripada biaya untuk memutar ulang input build sepenuhnya.
Memilih Gabung Adaptif
Pengoptimalan kueri melibatkan satu atau beberapa tahap eksplorasi logis dan implementasi fisik alternatif. Di setiap tahap, saat pengoptimal menjelajahi opsi fisik untuk logis bergabung, mungkin mempertimbangkan baik mode batch gabungan hash dan mode baris menerapkan alternatif.
Jika salah satu dari opsi gabungan fisik tersebut merupakan bagian dari solusi termurah yang ditemukan selama tahap saat ini—dan jenis gabungan lainnya dapat memberikan properti logis yang sama yang diperlukan—pengoptimal menandai grup gabungan logis sebagai berpotensi cocok untuk gabungan adaptif. Jika tidak, pertimbangan penggabungan adaptif berakhir di sini (dan tidak ada peristiwa perluasan penggabungan adaptif yang diaktifkan).
Pengoperasian normal pengoptimal berarti solusi termurah yang ditemukan hanya akan menyertakan salah satu opsi gabungan fisik—baik hash atau apply, mana saja yang memiliki perkiraan biaya terendah. Hal berikutnya yang dilakukan pengoptimal adalah membangun dan menetapkan biaya implementasi baru dari jenis gabungan yang tidak dipilih sebagai yang termurah.
Karena fase optimasi saat ini telah berakhir dengan solusi termurah yang ditemukan, putaran eksplorasi dan implementasi grup tunggal khusus dilakukan untuk gabungan adaptif. Terakhir, pengoptimal menghitung ambang adaptif .
Jika salah satu pekerjaan sebelumnya tidak berhasil, peristiwa yang diperpanjang adaptive_join_skipped diaktifkan dengan suatu alasan.
Jika pemrosesan penggabungan adaptif berhasil, Concat operator ditambahkan ke rencana internal di atas hash dan menerapkan alternatif dengan pembaca buffer adaptif dan adaptor mode batch/baris yang diperlukan. Ingat, hanya satu dari alternatif gabungan yang akan dieksekusi saat runtime, bergantung pada jumlah baris yang benar-benar ditemui dibandingkan dengan ambang adaptif.
Concat operator dan alternatif hash/terapkan individu biasanya tidak ditampilkan dalam rencana eksekusi akhir. Sebagai gantinya, kami disajikan dengan satu Gabungan Adaptif operator. Ini hanyalah keputusan presentasi—Concat dan gabungan masih ada dalam kode yang dijalankan oleh mesin eksekusi SQL Server. Anda dapat menemukan detail lebih lanjut tentang ini di bagian Lampiran dan Bacaan Terkait dari artikel ini.
Ambang Adaptif
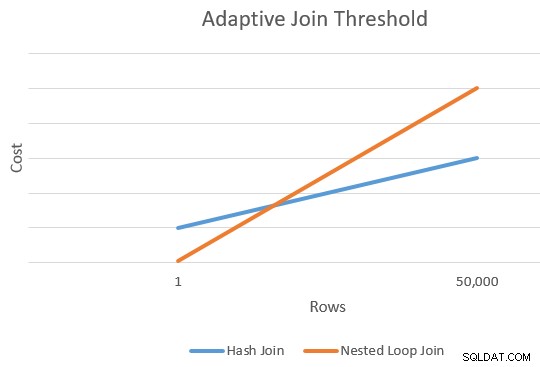
Penerapan umumnya lebih murah daripada gabungan hash untuk jumlah baris mengemudi yang lebih sedikit. Penggabungan hash memiliki biaya permulaan tambahan untuk membuat tabel hashnya tetapi biaya per baris lebih rendah saat mulai memeriksa kecocokan.
Biasanya ada titik di mana perkiraan biaya aplikasi dan hash join akan sama. Ide ini diilustrasikan dengan baik oleh Joe Sack dalam artikelnya, Introducing Batch Mode Adaptive Joins:
Menghitung Ambang Batas
Pada titik ini, pengoptimal memiliki perkiraan tunggal untuk jumlah baris yang memasuki input build dari hash join dan menerapkan alternatif. Ini juga memiliki perkiraan biaya hash dan menerapkan operator secara keseluruhan.
Ini memberi kita satu titik di tepi kanan ekstrem dari garis oranye dan biru pada diagram di atas. Pengoptimal memerlukan titik referensi lain untuk setiap jenis gabungan sehingga dapat "menggambar garis" dan menemukan persimpangan (tidak secara harfiah menggambar garis, tetapi Anda mendapatkan idenya).
Untuk menemukan titik kedua untuk garis, pengoptimal meminta keduanya bergabung untuk menghasilkan perkiraan biaya baru berdasarkan kardinalitas input yang berbeda (dan hipotetis). Jika perkiraan kardinalitas pertama lebih dari 100 baris, ia meminta gabungan untuk memperkirakan biaya baru untuk satu baris. Jika kardinalitas asli kurang dari atau sama dengan 100 baris, poin kedua didasarkan pada kardinalitas input 10.000 baris (jadi ada rentang yang cukup layak untuk diekstrapolasi).
Bagaimanapun, hasilnya adalah dua biaya dan jumlah baris yang berbeda untuk setiap jenis gabungan, memungkinkan garis untuk "digambar".
Rumus Persimpangan
Menemukan persimpangan dua garis berdasarkan dua titik untuk setiap garis adalah masalah dengan beberapa solusi terkenal. SQL Server menggunakan satu berdasarkan penentu seperti yang dijelaskan di Wikipedia:
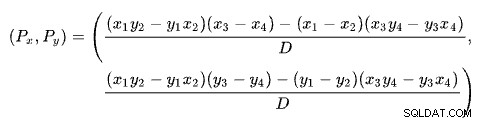
dimana:
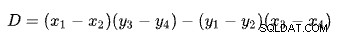
Baris pertama ditentukan oleh titik (x1 , y1 ) dan (x2 , y2 ). Baris kedua diberikan oleh titik (x3 , y3 ) dan (x4 , y4 ). Persimpangan berada di (Px , Py ).
Skema kami memiliki jumlah baris pada sumbu x dan perkiraan biaya pada sumbu y. Kami tertarik pada jumlah baris tempat garis berpotongan. Ini diberikan oleh rumus untuk Px . Jika kita ingin mengetahui perkiraan biaya pada simpang tersebut, maka akan menjadi Py .
Untuk Px baris, perkiraan biaya penerapan dan solusi hash join akan sama. Ini adalah ambang adaptif yang kita butuhkan.
Contoh yang Berfungsi
Berikut ini contoh penggunaan database contoh AdventureWorks2017 dan trik pengindeksan berikut oleh Itzik Ben-Gan untuk mendapatkan pertimbangan tanpa syarat dari eksekusi mode batch:
-- Itzik's trick
CREATE NONCLUSTERED COLUMNSTORE INDEX BatchMode
ON Sales.SalesOrderHeader (SalesOrderID)
WHERE SalesOrderID = -1
AND SalesOrderID = -2;
-- Test query
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
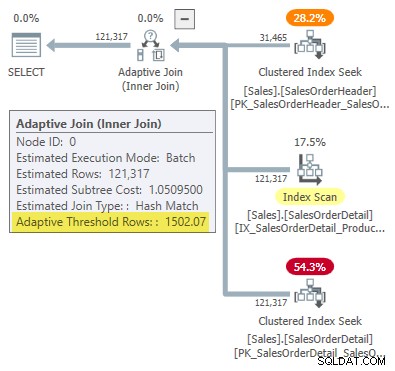
WHERE SOH.SalesOrderID <= 75123; Rencana eksekusi menunjukkan gabungan adaptif dengan ambang 1502,07 baris:
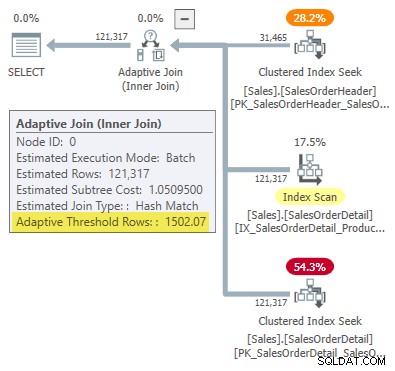
Perkiraan jumlah baris yang mendorong penggabungan adaptif adalah 31.465 .
Biaya Bergabung
Dalam kasus yang disederhanakan ini, kita dapat menemukan perkiraan biaya subpohon untuk hash dan menerapkan alternatif gabungan menggunakan petunjuk:
-- Hash
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (HASH JOIN, MAXDOP 1);

-- Apply
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (LOOP JOIN, MAXDOP 1);
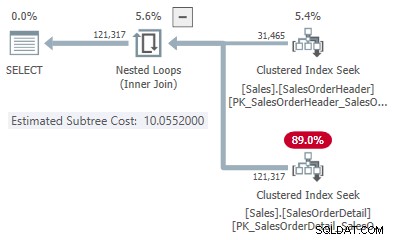
Ini memberi kita satu poin untuk setiap jenis gabungan:
- 31.465 baris
- Biaya hash 1,05083
- Terapkan biaya 10,0552
Titik Kedua di Garis
Karena perkiraan jumlah baris lebih dari 100, titik referensi kedua berasal dari perkiraan internal khusus berdasarkan satu baris input gabungan. Sayangnya, tidak ada cara mudah untuk mendapatkan angka biaya yang tepat untuk perhitungan internal ini (saya akan membicarakannya lebih lanjut segera).
Untuk saat ini, saya hanya akan menunjukkan kepada Anda angka biaya (menggunakan presisi internal penuh daripada enam angka penting yang disajikan dalam rencana eksekusi):
- Satu baris (perhitungan internal)
- Biaya hash 0.999027422729
- Terapkan biaya 0,547927305023
- 31.465 baris
- Biaya hash 1.05082787359
- Terapkan biaya 10.0552890166
Seperti yang diharapkan, apply join lebih murah daripada hash untuk kardinalitas input yang kecil tetapi jauh lebih mahal untuk kardinalitas yang diharapkan dari 31.465 baris.
Perhitungan Persimpangan
Dengan memasukkan angka kardinalitas dan biaya ini ke dalam rumus perpotongan garis, Anda akan mendapatkan hal berikut:
-- Hash points (x = cardinality; y = cost)
DECLARE
@x1 float = 1,
@y1 float = 0.999027422729,
@x2 float = 31465,
@y2 float = 1.05082787359;
-- Apply points (x = cardinality; y = cost)
DECLARE
@x3 float = 1,
@y3 float = 0.547927305023,
@x4 float = 31465,
@y4 float = 10.0552890166;
-- Formula:
SELECT Threshold =
(
(@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) -
(@x1 - @x2) * (@x3 * @y4 - @y3 * @x4)
)
/
(
(@x1 - @x2) * (@y3 - @y4) -
(@y1 - @y2) * (@x3 - @x4)
);
-- Returns 1502.06521571273 Dibulatkan menjadi enam angka penting, hasil ini cocok dengan 1502,07 baris yang ditampilkan dalam rencana eksekusi gabungan adaptif:
Cacat atau Desain?
Ingat, SQL Server membutuhkan empat poin untuk "menggambar" jumlah baris versus garis biaya untuk menemukan ambang batas gabungan adaptif. Dalam kasus ini, ini berarti menemukan estimasi biaya untuk kardinalitas satu baris dan 31.465 baris untuk implementasi apply dan hash join.
Pengoptimal memanggil rutin bernama sqllang!CuNewJoinEstimate untuk menghitung empat biaya ini untuk gabungan adaptif. Sayangnya, tidak ada tanda jejak atau acara yang diperluas untuk memberikan gambaran umum yang berguna tentang aktivitas ini. Tanda pelacakan normal yang digunakan untuk menyelidiki perilaku pengoptimal dan biaya tampilan tidak berfungsi di sini (lihat Lampiran jika Anda tertarik dengan detail selengkapnya).
Satu-satunya cara untuk mendapatkan perkiraan biaya satu baris adalah dengan melampirkan debugger dan menyetel breakpoint setelah panggilan keempat ke CuNewJoinEstimate dalam kode untuk sqllang!CardSolveForSwitch . Saya menggunakan WinDbg untuk mendapatkan tumpukan panggilan ini di SQL Server 2019 CU12:

Pada titik ini dalam kode, biaya floating point presisi ganda disimpan di empat lokasi memori yang ditunjuk oleh alamat di rsp+b0 , rsp+d0 , rsp+30 , dan rsp+28 (di mana rsp adalah register CPU dan offset dalam heksadesimal):

Nomor biaya subpohon operator yang ditampilkan cocok dengan yang digunakan dalam rumus penghitungan ambang batas gabungan adaptif.
Tentang Perkiraan Biaya Satu Baris
Anda mungkin telah memperhatikan perkiraan biaya subpohon untuk gabungan satu baris tampaknya cukup tinggi untuk jumlah pekerjaan yang terlibat dalam menggabungkan satu baris:
- Satu baris
- Biaya hash 0.999027422729
- Terapkan biaya 0,547927305023
Jika Anda mencoba membuat rencana eksekusi input satu baris untuk hash join dan menerapkan contoh, Anda akan melihat banyak perkiraan biaya subpohon yang lebih rendah pada saat bergabung daripada yang ditunjukkan di atas. Demikian juga, menjalankan kueri asli dengan sasaran baris satu (atau jumlah baris keluaran gabungan yang diharapkan untuk masukan satu baris) juga akan menghasilkan perkiraan biaya cara lebih rendah dari yang ditampilkan.
Alasannya adalah CuNewJoinEstimate rutin memperkirakan satu baris kasus dengan cara yang saya pikir kebanyakan orang tidak akan menemukan intuitif.
Biaya akhir terdiri dari tiga komponen utama:
- Biaya subpohon input build
- Biaya lokal untuk bergabung
- Biaya subpohon masukan probe
Item 2 dan 3 tergantung pada jenis join. Untuk hash join, mereka memperhitungkan biaya membaca semua baris dari input probe, mencocokkannya (atau tidak) dengan satu baris di tabel hash, dan meneruskan hasilnya ke operator berikutnya. Untuk permohonan, biaya mencakup satu pencarian pada input yang lebih rendah untuk bergabung, biaya internal dari gabungan itu sendiri, dan mengembalikan baris yang cocok ke operator induk.
Semua ini tidak biasa atau mengejutkan.
Kejutan Biaya
Kejutan datang di sisi pembuatan dari gabungan (item 1 dalam daftar). Orang mungkin mengharapkan pengoptimal untuk melakukan beberapa perhitungan mewah untuk menskalakan biaya subpohon yang sudah dihitung untuk 31.465 baris menjadi satu baris rata-rata, atau sesuatu seperti itu.
Faktanya, hash dan menerapkan estimasi gabungan satu baris cukup menggunakan seluruh biaya subpohon untuk asli perkiraan kardinalitas 31.465 baris. Dalam contoh yang sedang berjalan, “subpohon” ini adalah 0.54456 biaya pencarian indeks berkerumun mode batch di tabel header:
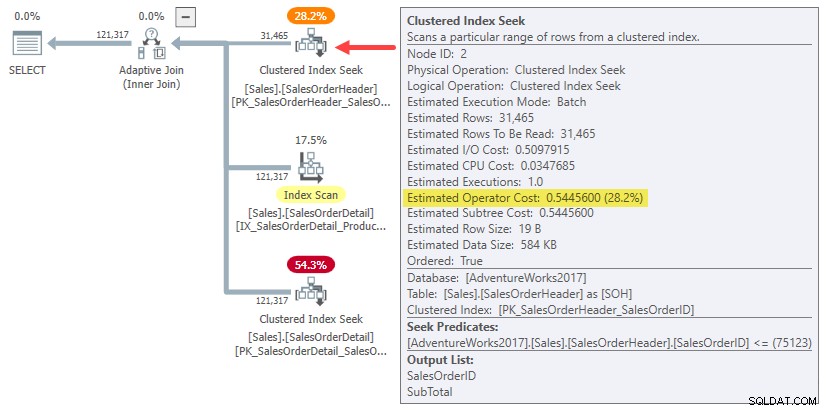
Untuk lebih jelasnya:perkiraan biaya sisi build untuk alternatif sambungan satu baris menggunakan biaya input yang dihitung untuk 31.465 baris. Itu menurut Anda agak aneh.
Sebagai pengingat, biaya satu baris dihitung dengan CuNewJoinEstimate adalah sebagai berikut:
- Satu baris
- Biaya hash 0.999027422729
- Terapkan biaya 0,547927305023
Anda dapat melihat total biaya penerapan (~0.54793) didominasi oleh 0.54456 biaya subpohon sisi-bangun, dengan jumlah ekstra kecil untuk pencarian sisi-dalam tunggal, memproses sejumlah kecil baris yang dihasilkan dalam gabungan, dan meneruskannya ke operator induk.
Perkiraan biaya gabungan hash satu baris lebih tinggi karena sisi probe dari rencana terdiri dari pemindaian indeks penuh, di mana semua baris yang dihasilkan harus melewati gabungan. Biaya total gabungan hash satu baris sedikit lebih rendah daripada biaya awal 1,05095 untuk contoh 31.465 baris karena sekarang hanya ada satu baris di tabel hash.
Implikasi
Seseorang akan mengharapkan perkiraan gabungan satu baris didasarkan, sebagian, pada biaya pengiriman satu baris ke input gabungan penggerak. Seperti yang telah kita lihat, ini bukan kasus untuk gabungan adaptif:alternatif penerapan dan hash dibebani dengan perkiraan biaya penuh untuk 31.465 baris. Penggabungan lainnya dikenai biaya cukup banyak seperti yang diharapkan untuk input build satu baris.
Pengaturan yang aneh secara intuitif ini adalah mengapa sulit (mungkin tidak mungkin) untuk menunjukkan rencana eksekusi yang mencerminkan biaya yang dihitung. Kami perlu membuat rencana yang mengirimkan 31.465 baris ke input gabungan atas tetapi membebani gabungan itu sendiri dan input dalamnya seolah-olah hanya satu baris yang ada. Pertanyaan yang sulit.
Efek dari semua ini adalah menaikkan titik paling kiri pada diagram garis berpotongan kita ke atas sumbu y. Hal ini mempengaruhi kemiringan garis dan titik potong.
Efek praktis lainnya adalah ambang batas gabungan adaptif yang dihitung sekarang bergantung pada perkiraan kardinalitas asli pada input pembuatan hash, seperti yang dicatat oleh Joe Obbish dalam postingan blognya tahun 2017. Misalnya, jika kita mengubah WHERE klausa dalam kueri pengujian ke SOH.SalesOrderID <= 55000 , ambang adaptif berkurang dari 1502,07 ke 1259,8 tanpa mengubah hash paket kueri. Paket sama, ambang batas berbeda.
Hal ini muncul karena, seperti yang telah kita lihat, perkiraan biaya satu baris internal bergantung pada biaya masukan pembuatan untuk perkiraan kardinalitas asli. Ini berarti estimasi sisi build awal yang berbeda akan memberikan “peningkatan” sumbu y yang berbeda pada estimasi satu baris. Pada gilirannya, garis tersebut akan memiliki kemiringan yang berbeda dan titik perpotongan yang berbeda.
Intuisi akan menyarankan perkiraan satu baris untuk gabungan yang sama harus selalu memberikan nilai yang sama terlepas dari perkiraan kardinalitas lain pada baris (mengingat gabungan yang sama persis dengan properti yang sama dan ukuran baris memiliki hubungan yang dekat-ke-linear antara mengemudi baris dan biaya). Ini tidak berlaku untuk gabungan adaptif.
Sesuai Desain?
Saya dapat memberi tahu Anda dengan yakin apa yang dilakukan SQL Server saat menghitung ambang batas gabungan adaptif. Saya tidak memiliki wawasan khusus tentang mengapa melakukannya dengan cara ini.
Namun, ada beberapa alasan untuk menganggap pengaturan ini disengaja dan terjadi setelah pertimbangan dan umpan balik dari pengujian. Sisa bagian ini mencakup beberapa pemikiran saya tentang aspek ini.
Penggabungan adaptif bukanlah pilihan langsung antara penerapan normal dan gabungan hash mode batch. Gabung adaptif selalu dimulai dengan mengisi tabel hash sepenuhnya. Hanya setelah pekerjaan ini selesai, keputusan dibuat untuk beralih ke penerapan penerapan atau tidak.
Pada saat ini, kami telah mengeluarkan biaya yang berpotensi signifikan dengan mengisi dan mempartisi hash join di memori. Ini mungkin tidak terlalu menjadi masalah untuk kasus satu baris, tetapi ini menjadi semakin penting seiring dengan meningkatnya kardinalitas. “Peningkatan” yang tidak terduga mungkin merupakan cara untuk memasukkan kenyataan ini ke dalam perhitungan sambil tetap mempertahankan biaya komputasi yang wajar.
Model biaya SQL Server telah lama sedikit bias terhadap loop bersarang bergabung, bisa dibilang dengan beberapa pembenaran. Bahkan kasus penerapan terindeks yang ideal dapat menjadi lambat dalam praktiknya jika data yang dibutuhkan belum ada di memori, dan subsistem I/O tidak berkedip, terutama dengan pola akses yang agak acak. Jumlah memori yang terbatas dan I/O yang lamban tentu tidak asing lagi bagi pengguna mesin database berbasis cloud kelas bawah, misalnya.
Kemungkinan pengujian praktis dalam lingkungan seperti itu mengungkapkan bahwa penggabungan adaptif dengan biaya intuitif terlalu cepat untuk beralih ke aplikasi. Teori terkadang hanya hebat dalam teori.
Namun, situasi saat ini tidak ideal; menyimpan rencana berdasarkan perkiraan kardinalitas yang sangat rendah akan menghasilkan gabungan adaptif yang jauh lebih enggan untuk beralih ke aplikasi daripada dengan perkiraan awal yang lebih besar. Ini adalah berbagai masalah sensitivitas parameter, tetapi ini akan menjadi pertimbangan baru untuk jenis ini bagi banyak dari kita.
Sekarang, ini juga mungkin menggunakan biaya subpohon input build penuh untuk titik paling kiri dari garis biaya yang berpotongan hanyalah kesalahan atau kelalaian yang tidak dikoreksi. Perasaan saya adalah implementasi saat ini mungkin merupakan kompromi praktis yang disengaja, tetapi Anda memerlukan seseorang yang memiliki akses ke dokumen desain dan kode sumber untuk mengetahui dengan pasti.
Ringkasan
Gabung adaptif memungkinkan SQL Server untuk bertransisi dari gabungan mode batch ke penerapan setelah tabel hash terisi penuh. Itu membuat keputusan ini dengan membandingkan jumlah baris dalam tabel hash dengan ambang adaptif yang telah dihitung sebelumnya.
Ambang dihitung dengan memprediksi di mana berlaku dan biaya bergabung hash adalah sama. Untuk menemukan titik ini, SQL Server menghasilkan estimasi biaya gabungan internal kedua untuk kardinalitas input build yang berbeda—biasanya, satu baris.
Anehnya, perkiraan biaya untuk perkiraan satu baris mencakup biaya subpohon sisi bangunan penuh untuk perkiraan kardinalitas asli (tidak diskalakan ke satu baris). Ini berarti nilai ambang bergantung pada perkiraan kardinalitas asli pada input build.
Akibatnya, gabungan adaptif mungkin memiliki nilai ambang batas rendah yang tidak terduga, yang berarti gabungan adaptif jauh lebih kecil kemungkinannya untuk beralih dari gabungan hash. Tidak jelas apakah perilaku ini memang disengaja.
Bacaan Terkait
- Memperkenalkan Penggabungan Adaptif Mode Batch oleh Joe Sack
- Memahami Adaptive Joins dalam dokumentasi produk
- Adaptive Join Internals oleh Dima Pilugin
- Bagaimana cara kerja Penggabungan Adaptif Mode Batch? di Database Administrator Stack Exchange oleh Erik Darling
- Regresi Gabung Adaptif oleh Joe Obbish
- Jika Anda Ingin Adaptive Joins, Anda Membutuhkan Indeks yang Lebih Luas dan Apakah Lebih Besar Lebih Baik? oleh Erik Darling
- Pengendus Parameter:Adaptive Joins oleh Brent Ozar
- Tanya Jawab Pemrosesan Kueri Cerdas oleh Joe Sack
Lampiran
Bagian ini mencakup beberapa aspek gabungan adaptif yang sulit untuk dimasukkan ke dalam teks utama secara alami.
Rencana Adaptif yang Diperluas
Anda dapat mencoba melihat representasi visual dari rencana internal menggunakan bendera jejak tidak berdokumen 9415, seperti yang disediakan oleh Dima Pilugin dalam artikel gabungan adaptif yang sangat baik yang ditautkan di atas. Dengan flag ini aktif, rencana penggabungan adaptif untuk contoh lari kami menjadi sebagai berikut:
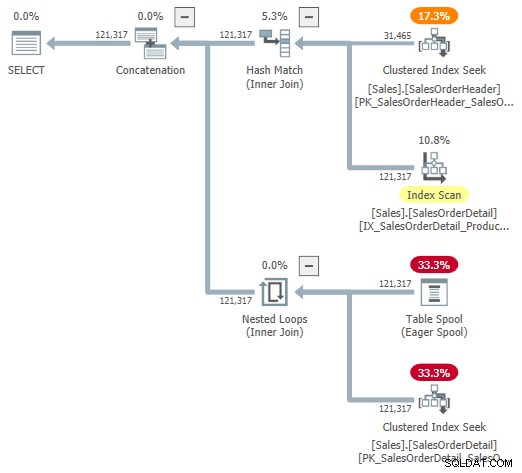
Ini adalah representasi yang berguna untuk membantu pemahaman, tetapi tidak sepenuhnya akurat, lengkap, atau konsisten. Misalnya, Table Spool tidak ada—ini adalah representasi default untuk pembaca buffer adaptif membaca baris langsung dari tabel hash mode batch.
Properti operator dan perkiraan kardinalitas juga sedikit di mana-mana. Output dari pembaca buffer adaptif (“spool”) harus 31.465 baris, bukan 121.317. Biaya subpohon penerapan salah dibatasi oleh biaya operator induk. Ini normal untuk showplan, tetapi tidak masuk akal dalam konteks gabungan adaptif.
Ada juga ketidakkonsistenan lain—terlalu banyak untuk dicantumkan secara berguna— tetapi itu bisa terjadi dengan tanda jejak yang tidak didokumentasikan. Paket yang diperluas yang ditunjukkan di atas tidak dimaksudkan untuk digunakan oleh pengguna akhir, jadi mungkin itu tidak sepenuhnya mengejutkan. Pesan di sini adalah untuk tidak terlalu bergantung pada angka dan properti yang ditampilkan dalam formulir tidak berdokumen ini.
Saya juga harus menyebutkan bahwa operator paket gabungan adaptif standar yang telah selesai tidak sepenuhnya tanpa masalah konsistensinya sendiri. Ini berasal cukup banyak secara eksklusif dari detail tersembunyi.
Misalnya, properti gabungan adaptif yang ditampilkan berasal dari campuran Concat . yang mendasarinya , Hash Gabung , dan Terapkan operator. Anda dapat melihat eksekusi mode batch pelaporan gabungan adaptif untuk penggabungan loop bersarang (yang tidak mungkin dilakukan), dan waktu berlalu yang ditampilkan sebenarnya disalin dari Concat tersembunyi , bukan gabungan tertentu yang dieksekusi saat runtime.
Tersangka Biasa
Kami bisa dapatkan beberapa informasi berguna dari jenis tanda jejak tidak berdokumen yang biasanya digunakan untuk melihat keluaran pengoptimal. Misalnya:
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (
QUERYTRACEON 3604,
QUERYTRACEON 8607,
QUERYTRACEON 8612); Output (banyak diedit agar mudah dibaca):
*** Pohon Keluaran:***PhyOp_ExecutionModeAdapter(BatchToRow) Kartu=121317 Biaya=1.05095
- Kartu PhyOp_Concat (batch)=121317 Biaya=1.05325
- Kartu PhyOp_HashJoinx_jtInner (batch)=121317 Biaya=1.05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Biaya=0,54456
- Kartu PhyOp_Filter(batch)=121317 Biaya=0,397185
- Penjualan PhyOp_Range.SalesOrderDetail Card=121317 Biaya=0,338953
- Kartu PhyOp_ExecutionModeAdapter(RowToBatch)=121317 Biaya=10,0798
- PhyOp_Apply Card=121317 Biaya=10.0553
- Kartu PhyOp_ExecutionModeAdapter(BatchToRow)=31465 Biaya=0,544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Biaya=0,54456 [** 3 **]
- Kartu PhyOp_Filter=3.85562 Biaya=9.00356
- Penjualan PhyOp_Range.SalesOrderDetail Card=3.85562 Biaya=8.94533
- Kartu PhyOp_ExecutionModeAdapter(BatchToRow)=31465 Biaya=0,544623
- PhyOp_Apply Card=121317 Biaya=10.0553
Ini memberikan beberapa wawasan tentang perkiraan biaya untuk kasus kardinalitas penuh dengan hash dan menerapkan alternatif tanpa menulis kueri terpisah dan menggunakan petunjuk. Seperti yang disebutkan dalam teks utama, tanda pelacakan ini tidak efektif dalam CuNewJoinEstimate , jadi kami tidak dapat langsung melihat penghitungan berulang untuk kasus 31.465 baris atau detail apa pun untuk taksiran satu baris dengan cara ini.
Merge Join dan Row Mode Hash Join
Gabungan adaptif hanya menawarkan transisi dari gabungan mode batch ke mode baris yang berlaku. Untuk alasan mengapa gabungan hash mode baris tidak didukung, lihat Tanya Jawab Pemrosesan Kueri Cerdas di bagian Bacaan Terkait. Singkatnya, penggabungan hash mode baris akan terlalu rentan terhadap regresi kinerja.
Beralih ke mode baris merge join akan menjadi opsi lain, tetapi pengoptimal saat ini tidak mempertimbangkannya. Seperti yang saya pahami, itu tidak mungkin diperluas ke arah ini di masa depan.
Beberapa pertimbangannya sama seperti untuk hash join mode baris. Selain itu, rencana penggabungan gabungan cenderung kurang mudah dipertukarkan dengan hash join, bahkan jika kita membatasi diri pada gabungan gabungan yang diindeks (tidak ada pengurutan eksplisit).
Ada juga perbedaan yang jauh lebih besar antara hash dan apply daripada antara hash dan merge. Baik hash maupun penggabungan cocok untuk input yang lebih besar, dan apply lebih cocok untuk input penggerak yang lebih kecil. Penggabungan gabungan tidak semudah diparalelkan seperti penggabungan hash dan tidak dapat diskalakan juga dengan meningkatnya jumlah utas.
Mengingat motivasi untuk bergabung secara adaptif adalah untuk mengatasi secara signifikan . dengan lebih baik berbagai ukuran input—dan hanya hash join yang mendukung pemrosesan mode batch—pilihan batch hash versus penerapan baris adalah pilihan yang lebih alami. Terakhir, memiliki tiga pilihan gabungan adaptif akan secara signifikan memperumit penghitungan ambang batas untuk potensi keuntungan yang kecil.