Posting ini adalah bagian dari rangkaian artikel tentang tujuan baris. Anda dapat menemukan bagian pertama di sini:
- Bagian 1:Menetapkan dan Mengidentifikasi Sasaran Baris
Relatif terkenal bahwa menggunakan TOP atau FAST n petunjuk kueri dapat menetapkan sasaran baris dalam rencana eksekusi (lihat Menetapkan dan Mengidentifikasi Sasaran Baris dalam Rencana Eksekusi jika Anda memerlukan penyegaran tentang sasaran baris dan penyebabnya). Agak kurang umum bahwa semi-gabungan (dan anti-gabungan) dapat memperkenalkan tujuan baris juga, meskipun ini agak kurang mungkin daripada kasus TOP , FAST , dan SET ROWCOUNT .
Artikel ini akan membantu Anda memahami kapan, dan mengapa, semi join memanggil logika tujuan baris pengoptimal.
Setengah bergabung
Semi join mengembalikan baris dari satu input join (A) jika ada setidaknya satu baris yang cocok pada input gabungan lainnya (B).
Perbedaan mendasar antara semi join dan regular join adalah:
- Semi join mengembalikan setiap baris dari input A, atau tidak. Tidak ada duplikasi baris yang dapat terjadi.
- Gabungkan baris duplikat secara teratur jika ada beberapa kecocokan pada predikat gabungan.
- Semi join didefinisikan hanya mengembalikan kolom dari input A.
- Penggabungan biasa dapat mengembalikan kolom dari salah satu (atau keduanya) masukan gabungan.
T-SQL saat ini tidak memiliki dukungan untuk sintaks langsung seperti FROM A SEMI JOIN B ON A.x = B.y , jadi kita perlu menggunakan bentuk tidak langsung seperti EXISTS , SOME/ANY (termasuk singkatan yang setara IN untuk perbandingan kesetaraan), dan atur INTERSECT .
Deskripsi semi-gabungan di atas secara alami mengisyaratkan penerapan tujuan baris, karena kami tertarik untuk menemukan setiap baris yang cocok di B, bukan semua baris seperti itu . Namun demikian, semi-join logis yang diekspresikan dalam T-SQL mungkin tidak mengarah ke rencana eksekusi menggunakan tujuan baris karena beberapa alasan, yang akan kami bongkar selanjutnya.
Transformasi dan penyederhanaan
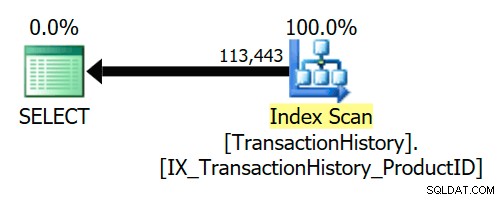
Penggabungan semi logis mungkin disederhanakan atau diganti dengan sesuatu yang lain selama kompilasi dan pengoptimalan kueri. Contoh AdventureWorks di bawah ini menunjukkan semi-gabungan yang dihapus seluruhnya, karena hubungan kunci asing tepercaya:
PILIH TH.ProductID FROM Production.TransactionHistory AS THWHERE TH.ProductID IN( PILIH P.ProductID FROM Production.Product AS P);
Kunci asing memastikan bahwa Product baris akan selalu ada untuk setiap baris Riwayat. Akibatnya, rencana eksekusi hanya mengakses TransactionHistory tabel:
Contoh yang lebih umum terlihat ketika semi join dapat diubah menjadi inner join. Misalnya:
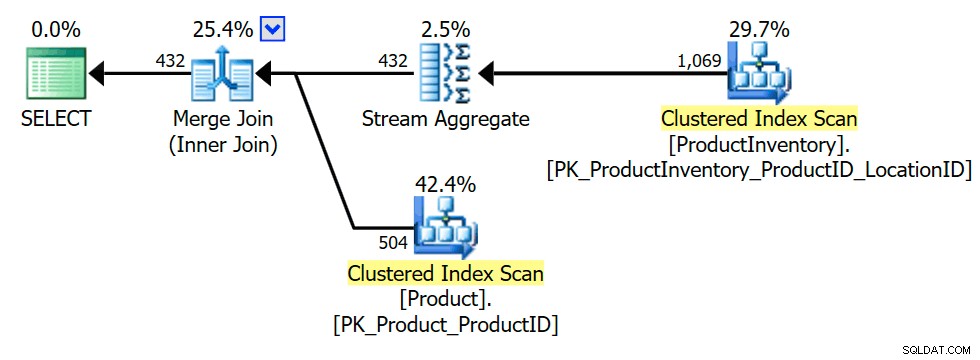
PILIH P.ProductID FROM Production.Product AS P WHERE EXISTS( SELECT * FROM Production.ProductInventory AS INV WHERE INV.ProductID =P.ProductID);
Rencana eksekusi menunjukkan bahwa pengoptimal memperkenalkan agregat (pengelompokan pada INV.ProductID ) untuk memastikan bahwa gabungan dalam hanya dapat mengembalikan Product baris sekali, atau tidak sama sekali (seperti yang diperlukan untuk mempertahankan semantik semi join):
Transformasi ke inner join dieksplorasi lebih awal karena pengoptimal mengetahui lebih banyak trik untuk inner equijoin daripada untuk semi-join, yang berpotensi menghasilkan lebih banyak peluang pengoptimalan. Secara alami, pilihan rencana akhir masih merupakan keputusan berbasis biaya di antara alternatif yang dieksplorasi.
Pengoptimalan Awal
Meskipun T-SQL tidak memiliki SEMI JOIN langsung sintaks, pengoptimal tahu semua tentang semi bergabung secara asli, dan dapat memanipulasinya secara langsung. Sintaks semi join solusi umum ditransformasikan menjadi semi join internal "nyata" di awal proses kompilasi kueri (bahkan sebelum rencana sepele dipertimbangkan).
Dua grup sintaks solusi utama adalah EXISTS/INTERSECT , dan ANY/SOME/IN . EXISTS dan INTERSECT kasus hanya berbeda karena yang terakhir dilengkapi dengan DISTINCT implicit implisit (pengelompokan pada semua kolom yang diproyeksikan). Keduanya EXISTS dan INTERSECT diuraikan sebagai EXISTS dengan subquery yang berkorelasi. ANY/SOME/IN representasi semua ditafsirkan sebagai operasi BEBERAPA. Kami dapat menjelajahi lebih awal aktivitas pengoptimalan ini dengan beberapa tanda pelacakan tidak berdokumen, yang mengirimkan informasi tentang aktivitas pengoptimal ke tab pesan SSMS.
Misalnya, semi join yang telah kita gunakan sejauh ini juga dapat ditulis menggunakan IN :
PILIH P.ProductIDFROM Production.Product AS PWHERE P.ProductID IN /* or =ANY/SOME */( SELECT TH.ProductID FROM Production.TransactionHistory AS TH)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);Pohon masukan pengoptimal adalah sebagai berikut:
Operator skalar ScaOp_SomeComp adalah
SOMEperbandingan yang disebutkan di atas. Angka 2 adalah kode untuk uji kesetaraan, karenaINsetara dengan= SOME. Jika Anda tertarik, ada kode dari 1 hingga 6 yang mewakili (<, =, <=,>, !=,>=) masing-masing operator pembanding.Kembali ke
EXISTSsintaks yang paling sering saya gunakan untuk mengekspresikan semi join secara tidak langsung:PILIH P.ProductIDFROM Production.Product AS PWHERE EXISTS( SELECT * FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);Pohon masukan pengoptimal adalah:
Pohon itu adalah terjemahan langsung dari teks kueri; meskipun perhatikan bahwa
SELECT *telah digantikan oleh proyeksi nilai bilangan bulat konstan 1 (lihat baris teks kedua dari belakang).Hal berikutnya yang dilakukan pengoptimal adalah menghapus sarang subkueri dalam pemilihan relasional (=filter) menggunakan aturan RemoveSubqInSel . Pengoptimal selalu melakukan ini, karena ia tidak dapat beroperasi pada subkueri secara langsung. Hasilnya adalah terapkan (alias gabungan yang berkorelasi atau lateral):
(Aturan penghapusan subkueri yang sama menghasilkan keluaran yang sama untuk
SOMEmasukan pohon juga).Langkah selanjutnya adalah menulis ulang apply sebagai join biasa menggunakan ApplyHandler keluarga aturan. Ini adalah sesuatu yang selalu coba dilakukan oleh pengoptimal, karena ia memiliki lebih banyak aturan eksplorasi untuk bergabung daripada untuk diterapkan. Tidak semua lamaran dapat ditulis ulang sebagai gabungan, tetapi contoh saat ini sangat mudah dan berhasil:
Perhatikan jenis gabungan dibiarkan semi. Memang, ini adalah pohon yang persis sama yang akan segera kita dapatkan jika T-SQL mendukung sintaks seperti:
PILIH P.ProductID FROM Production.Product AS P KIRI SEMI GABUNG Production.TransactionHistory AS TH TH.ProductID =P.ProductID;Akan menyenangkan untuk dapat mengungkapkan pertanyaan secara lebih langsung seperti ini. Bagaimanapun, pembaca yang tertarik didorong untuk mengeksplorasi aktivitas penyederhanaan di atas dengan cara lain yang setara secara logis untuk menulis semi join ini di T-SQL.
Hal penting yang dapat diambil pada tahap ini adalah pengoptimal selalu menghapus subkueri , menggantinya dengan apply. Kemudian mencoba untuk menulis ulang berlaku sebagai bergabung biasa untuk memaksimalkan peluang menemukan rencana yang baik. Ingatlah bahwa semua hal sebelumnya terjadi bahkan sebelum rencana sepele dipertimbangkan. Selama pengoptimalan berbasis biaya, pengoptimal juga dapat mempertimbangkan transformasi gabungan kembali ke aplikasi.
Hash dan Gabungkan Semi Gabung
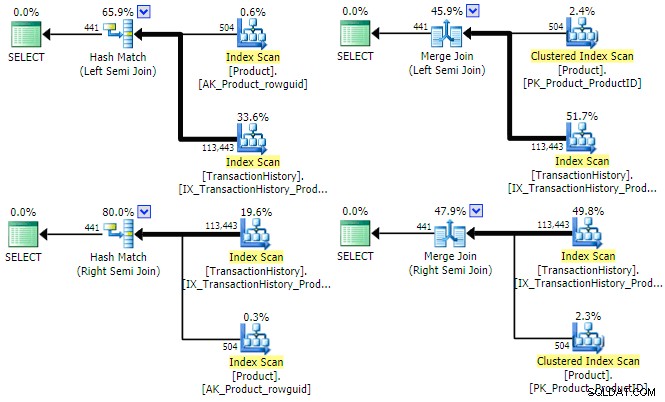
SQL Server memiliki tiga opsi implementasi fisik utama yang tersedia untuk semi logis. Selama predikat equijoin ada, hash dan merge join tersedia; keduanya dapat beroperasi dalam mode semi join kiri dan kanan. Penggabungan loop bersarang hanya mendukung semi join kiri (bukan kanan), tetapi tidak memerlukan predikat equijoin. Mari kita lihat hash dan menggabungkan opsi fisik untuk kueri contoh kita (kali ini ditulis sebagai satu set berpotongan):
PILIH P.ProductID FROM Production.Product AS PINTERSECTPILIH TH.ProductID FROM Production.TransactionHistory AS TH;Pengoptimal dapat menemukan rencana untuk keempat kombinasi (kiri/kanan) dan (hash/gabung) semi gabung untuk kueri ini:
Perlu disebutkan secara singkat mengapa pengoptimal mungkin mempertimbangkan gabungan semi kiri dan kanan untuk setiap jenis gabungan. Untuk hash semi join, pertimbangan biaya utama adalah perkiraan ukuran tabel hash, yang selalu merupakan input kiri (atas) pada awalnya. Untuk penggabungan semi gabung, properti dari setiap input menentukan apakah penggabungan banyak ke banyak satu-ke-banyak atau kurang efisien dengan meja kerja akan digunakan.
Mungkin terlihat dari rencana eksekusi di atas bahwa baik hash maupun penggabungan semi-gabungan tidak akan mendapat manfaat dari menetapkan sasaran baris . Kedua tipe join selalu menguji predikat join pada join itu sendiri, dan bertujuan untuk menggunakan semua baris dari kedua input untuk mengembalikan set hasil lengkap. Itu tidak berarti bahwa optimasi kinerja tidak ada untuk hash dan gabung gabungan secara umum – misalnya, keduanya dapat menggunakan bitmap untuk mengurangi jumlah baris yang mencapai gabungan. Sebaliknya, intinya adalah bahwa tujuan baris pada kedua input tidak akan membuat hash atau penggabungan semi-gabung menjadi lebih efisien.
Loop Bersarang dan Terapkan Semi Join
Jenis gabungan fisik yang tersisa adalah loop bersarang, yang hadir dalam dua rasa:loop bersarang reguler (tidak berkorelasi) dan berlaku loop bersarang (kadang-kadang juga disebut sebagai berkorelasi atau lateral bergabung).
Gabung loop bersarang reguler mirip dengan hash dan gabung gabung di mana predikat gabung dievaluasi pada gabung. Seperti sebelumnya, ini berarti tidak ada nilai dalam menetapkan sasaran baris pada kedua input. Input kiri (atas) akan selalu dikonsumsi sepenuhnya pada akhirnya, dan input dalam tidak memiliki cara untuk menentukan baris mana yang harus diprioritaskan, karena kita tidak dapat mengetahui apakah suatu baris akan bergabung atau tidak sampai predikat diuji saat bergabung .
Sebaliknya, gabungan loop bersarang yang diterapkan memiliki satu atau beberapa referensi luar (parameter berkorelasi) di gabungan, dengan predikat gabungan ditekan ke bawah sisi dalam (bawah) sambungan. Ini menciptakan peluang untuk penerapan tujuan baris yang berguna. Ingat bahwa semi join hanya mengharuskan kita untuk memeriksa keberadaan baris pada input gabungan B yang cocok dengan baris saat ini pada input gabungan A (hanya memikirkan tentang strategi penggabungan loop bersarang sekarang).
Dengan kata lain, pada setiap iterasi penerapan, kita dapat berhenti melihat input B segera setelah kecocokan pertama ditemukan, menggunakan predikat gabungan yang didorong ke bawah. Ini adalah jenis tujuan baris yang baik untuk:menghasilkan bagian dari rencana yang dioptimalkan untuk mengembalikan n baris pertama yang cocok dengan cepat (di mana
n = 1di sini).Tentu saja, gol baris bisa menjadi hal yang baik atau tidak, tergantung pada situasinya. Tidak ada yang istimewa tentang gol baris semi join dalam hal itu. Pertimbangkan situasi di mana bagian dalam semi join lebih kompleks daripada akses tabel tunggal sederhana, mungkin gabungan multi-tabel. Menetapkan sasaran baris dapat membantu pengoptimal memilih strategi navigasi yang efisien hanya untuk subpohon tertentu , menemukan baris pertama yang cocok untuk memenuhi semi join melalui nested loop joins dan index seek. Tanpa sasaran baris, pengoptimal mungkin secara alami memilih hash atau gabungan gabungan dengan sortir untuk meminimalkan biaya yang diharapkan untuk mengembalikan semua baris yang mungkin. Perhatikan bahwa ada asumsi di sini, yaitu bahwa orang biasanya menulis semi join dengan harapan bahwa baris yang cocok dengan kondisi pencarian memang ada. Ini tampaknya asumsi yang cukup adil bagi saya.
Terlepas dari itu, poin penting pada tahap ini adalah:Hanya lamar loop bersarang bergabung memiliki tujuan baris diterapkan oleh pengoptimal (ingat, tujuan baris untuk menerapkan loop bersarang bergabung hanya ditambahkan jika tujuan baris kurang dari perkiraan tanpa itu). Kami akan melihat beberapa contoh yang berhasil untuk semoga memperjelas semua ini selanjutnya.
Contoh Semi-Gabung Loop Bersarang
Skrip berikut membuat dua tabel sementara tumpukan. Yang pertama memiliki angka dari 1 hingga 20 inklusif; yang lain memiliki 10 salinan dari setiap nomor di tabel pertama:
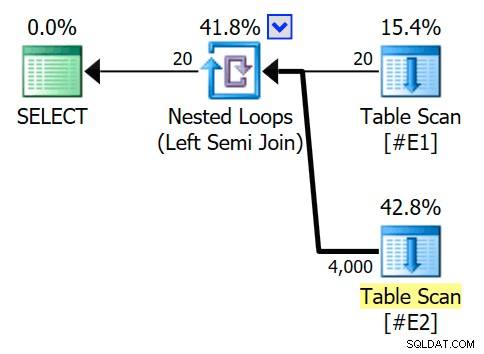
DROP TABLE JIKA ADA #E1, #E2; CREATE TABLE #E1 (c1 integer NULL);CREATE TABLE #E2 (c1 integer NULL); INSERT #E1 (c1)PILIH SV.numberFROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 AND SV.number <=20; INSERT #E2 (c1)SELECT (SV.number % 20) + 1FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 AND SV.number <=200;Tanpa indeks dan jumlah baris yang relatif kecil, pengoptimal memilih implementasi loop bersarang (bukan hash atau penggabungan) untuk kueri semi-gabung berikut). Tanda jejak yang tidak didokumentasikan memungkinkan kita untuk melihat pohon keluaran pengoptimal dan informasi tujuan baris:
PILIH E1.c1 FROM #E1 AS E1WHERE E1.c1 IN (SELECT E2.c1 FROM #E2 AS E2)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Perkiraan rencana eksekusi menampilkan gabungan loop bersarang semi-gabungan, dengan 200 baris per pemindaian penuh tabel
#E2. 20 iterasi dari loop memberikan perkiraan total 4.000 baris:
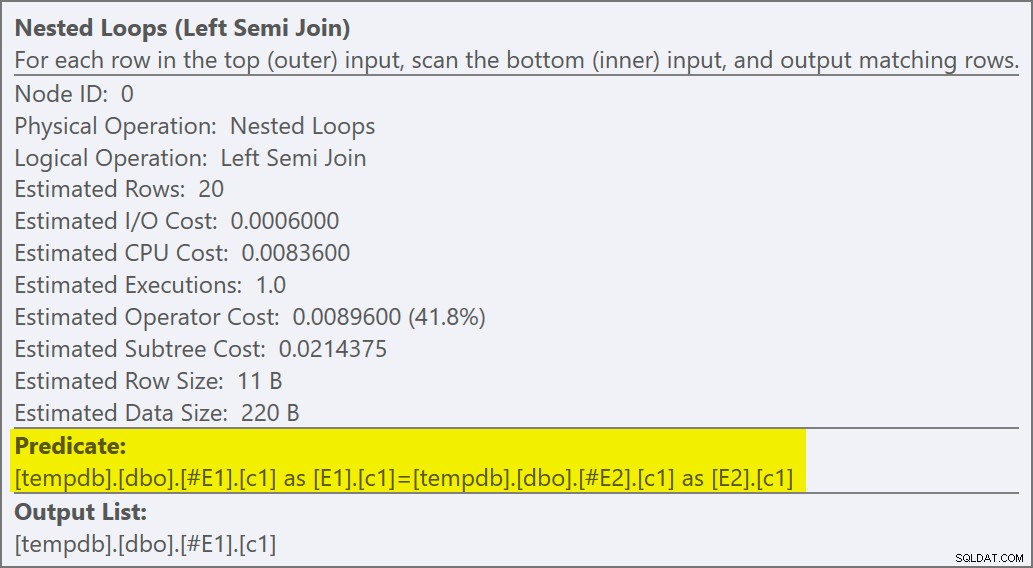
Properti dari operator loop bersarang menunjukkan bahwa predikat diterapkan pada gabungan artinya ini adalah gabungan loop bersarang yang tidak berkorelasi :
Keluaran tanda jejak (pada tab pesan SSMS) menunjukkan loop bersarang semi-gabungan dan tidak ada sasaran baris (RowGoal 0):
Perhatikan bahwa rencana pasca-eksekusi untuk kueri mainan ini tidak akan menampilkan total 4.000 baris yang dibaca dari tabel #E2. Loop bersarang semi join (berkorelasi atau tidak) akan berhenti mencari lebih banyak baris di sisi dalam (per iterasi) segera setelah kecocokan pertama untuk baris luar saat ini ditemukan. Sekarang, urutan baris yang ditemui dari heap scan #E2 pada setiap iterasi adalah non-deterministik (dan mungkin berbeda pada setiap iterasi), jadi pada prinsipnya hampir semua baris dapat diuji pada setiap iterasi, jika baris yang cocok ditemukan selambat mungkin (atau memang, dalam kasus tidak ada baris yang cocok, tidak sama sekali).
Misalnya, jika kita mengasumsikan implementasi runtime di mana baris kebetulan dipindai dalam urutan yang sama (misalnya "urutan penyisipan") setiap kali, jumlah total baris yang dipindai dalam contoh mainan ini akan menjadi 20 baris pada iterasi pertama, 1 baris pada iterasi kedua, 2 baris pada iterasi ketiga, dan seterusnya sehingga total 20 + 1 + 2 + (…) + 19 =210 baris. Memang Anda sangat mungkin untuk mengamati total ini, yang mengatakan lebih banyak tentang batasan kode demonstrasi sederhana daripada tentang hal lain. Seseorang tidak dapat mengandalkan urutan baris yang dikembalikan dari metode akses tidak berurutan seperti halnya seseorang dapat mengandalkan output yang tampaknya dipesan dari kueri tanpa
ORDER BYtingkat atas klausa.Daftar Semi-Gabung
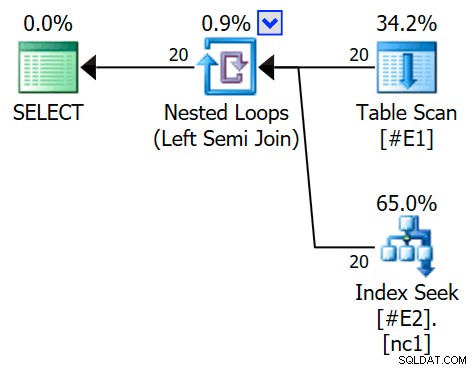
Kami sekarang membuat indeks nonclustered pada tabel yang lebih besar (untuk mendorong pengoptimal memilih menerapkan semi join) dan menjalankan kueri lagi:
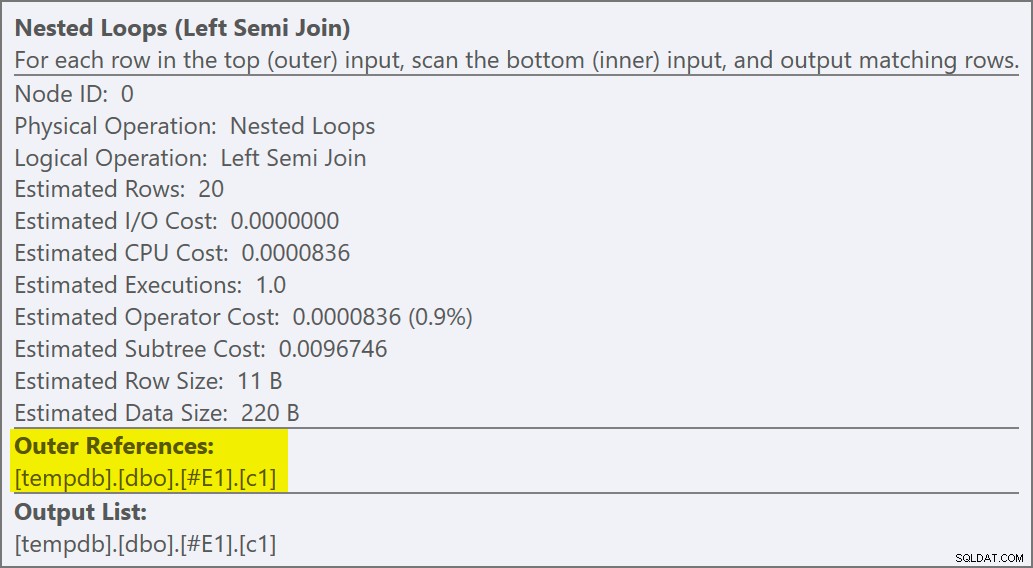
BUAT INDEKS NONCLUSTERED nc1 PADA #E2 (c1); PILIH E1.c1 FROM #E1 AS E1WHERE E1.c1 IN (SELECT E2.c1 FROM #E2 AS E2)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Rencana eksekusi sekarang memiliki fitur semi join yang berlaku, dengan 1 baris per pencarian indeks (dan 20 iterasi seperti sebelumnya):
Kami dapat mengatakan bahwa ini adalah terapkan semi gabung karena properti gabungan menunjukkan referensi luar daripada predikat bergabung:
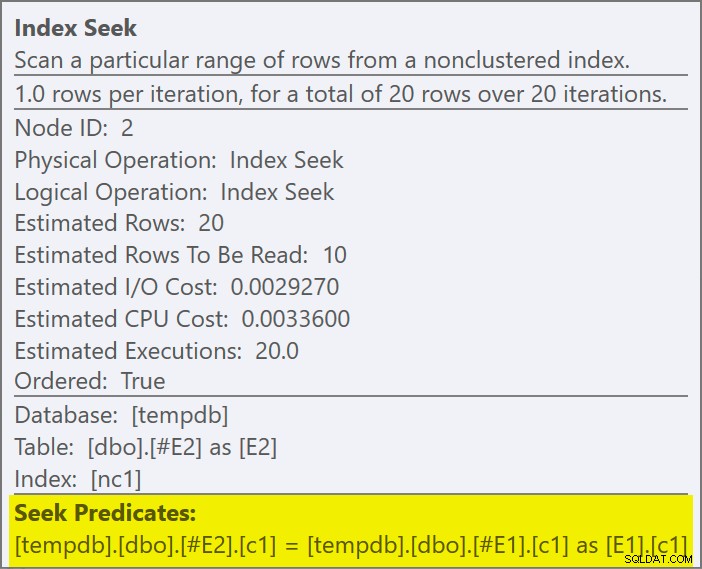
Predikat bergabung telah ditekan sisi dalam aplikasi, dan dicocokkan dengan indeks baru:
Setiap pencarian diharapkan mengembalikan 1 baris, meskipun faktanya setiap nilai diduplikasi 10 kali dalam tabel itu; ini adalah efek dari gol baris . Sasaran baris akan lebih mudah diidentifikasi pada build SQL Server yang mengekspos EstimateRowsWithoutRowGoal atribut plan (SQL Server 2017 CU3 pada saat penulisan). Dalam versi Plan Explorer yang akan datang, hal ini juga akan ditampilkan pada tooltips untuk operator yang relevan:
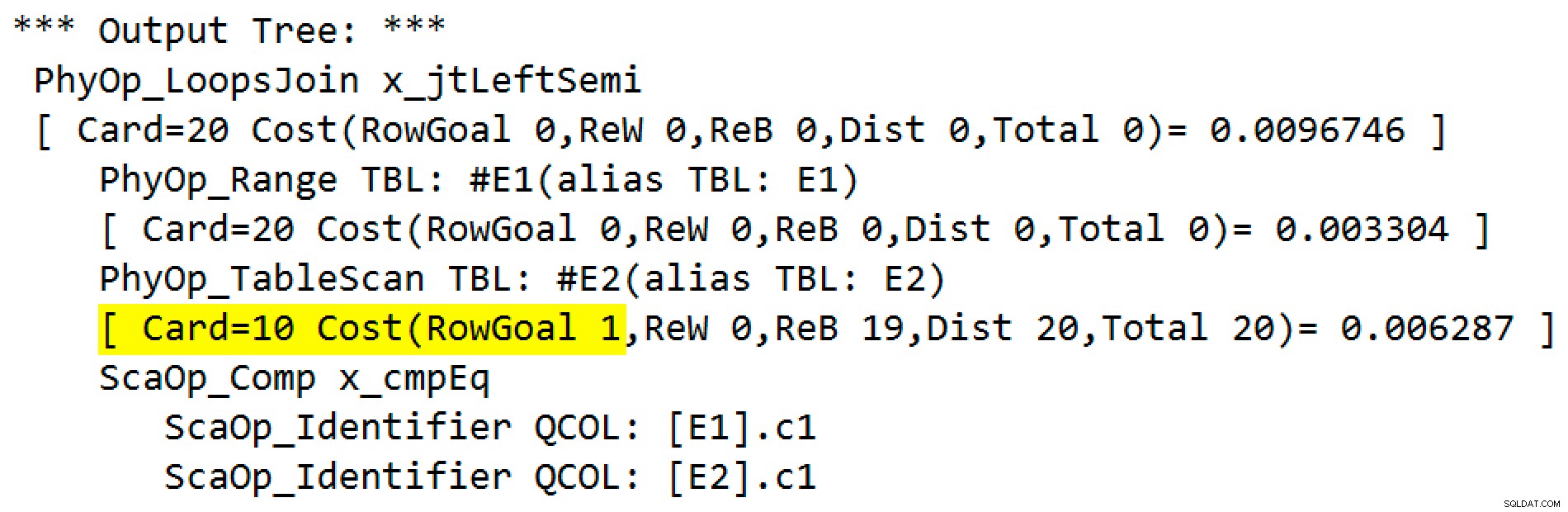
Keluaran tanda jejak adalah:
Operator fisik telah berubah dari loop join menjadi apply yang berjalan dalam mode semi join kiri. Akses ke tabel
#E2telah memperoleh tujuan baris 1 (kardinalitas tanpa tujuan baris ditunjukkan sebagai 10). Sasaran baris bukanlah masalah besar dalam hal ini karena biaya untuk mengambil sekitar sepuluh baris per pencarian tidak lebih dari satu baris. Menonaktifkan sasaran baris untuk kueri ini (menggunakan tanda pelacakan 4138 atauDISABLE_OPTIMIZER_ROWGOALpetunjuk kueri) tidak akan mengubah bentuk rencana.Namun demikian, dalam kueri yang lebih realistis, pengurangan biaya karena sasaran baris sisi dalam dapat membuat perbedaan antara opsi penerapan yang bersaing. Misalnya, menonaktifkan sasaran baris dapat menyebabkan pengoptimal memilih hash atau gabungan semi gabung, atau salah satu dari banyak opsi lain yang dipertimbangkan untuk kueri. Jika tidak ada yang lain, tujuan baris di sini secara akurat mencerminkan fakta bahwa penerapan semi gabung akan berhenti mencari sisi dalam segera setelah kecocokan pertama ditemukan, dan beralih ke baris sisi luar berikutnya.
Perhatikan bahwa duplikat dibuat di tabel
#E2sehingga tujuan baris semi gabung yang diterapkan (1) akan lebih rendah dari perkiraan normal (10, dari informasi kepadatan statistik). Jika tidak ada duplikat, estimasi baris untuk setiap pencarian ke#E2juga akan menjadi 1 baris, jadi sasaran baris 1 tidak akan diterapkan (ingat aturan umum tentang ini!)Gol Baris versus Teratas
Mengingat bahwa rencana eksekusi tidak menunjukkan adanya tujuan baris sama sekali sebelum SQL Server 2017 CU3, orang mungkin berpikir akan lebih jelas untuk menerapkan pengoptimalan ini menggunakan operator Top eksplisit, daripada properti tersembunyi seperti tujuan baris. Idenya adalah menempatkan operator Top (1) di sisi dalam dari gabungan semi/anti yang berlaku alih-alih menetapkan tujuan baris pada gabungan itu sendiri.
Menggunakan operator Top dengan cara ini tidak akan sepenuhnya tanpa preseden. Misalnya, sudah ada versi khusus Top yang dikenal sebagai jumlah baris atas yang terlihat dalam rencana eksekusi modifikasi data ketika
SET ROWCOUNTbukan nol berlaku (perhatikan bahwa penggunaan khusus ini telah ditinggalkan sejak 2005 meskipun masih diperbolehkan di SQL Server 2017). Implementasi jumlah baris teratas sedikit kikuk karena operator teratas selalu ditampilkan sebagai Top (0) dalam rencana eksekusi, terlepas dari batas jumlah baris aktual yang berlaku.Tidak ada alasan kuat mengapa tujuan baris semi gabung yang diterapkan tidak dapat diganti dengan operator Top (1) yang eksplisit. Meskipun demikian, ada beberapa alasan untuk memilih untuk tidak melakukan itu:






- Menambahkan Top (1) yang eksplisit memerlukan upaya dan pengujian pengkodean yang lebih pengoptimal daripada menambahkan tujuan baris (yang sudah digunakan untuk hal lain).
- Top bukan operator relasional; pengoptimal memiliki sedikit dukungan untuk alasan tentang hal itu. Ini dapat berdampak negatif pada kualitas paket dengan membatasi kemampuan pengoptimal untuk mengubah bagian dari paket kueri, mis. dengan memindahkan agregat, serikat pekerja, filter, dan bergabung.
- Ini akan memperkenalkan kopling ketat antara penerapan penerapan semi join dan atas. Kasus khusus dan kopling ketat adalah cara yang bagus untuk memperkenalkan bug dan membuat perubahan di masa mendatang lebih sulit dan rawan kesalahan.
- Top (1) akan redundan secara logis, dan hanya ada untuk efek samping sasaran barisnya.
Poin terakhir ini layak untuk dikembangkan dengan sebuah contoh:
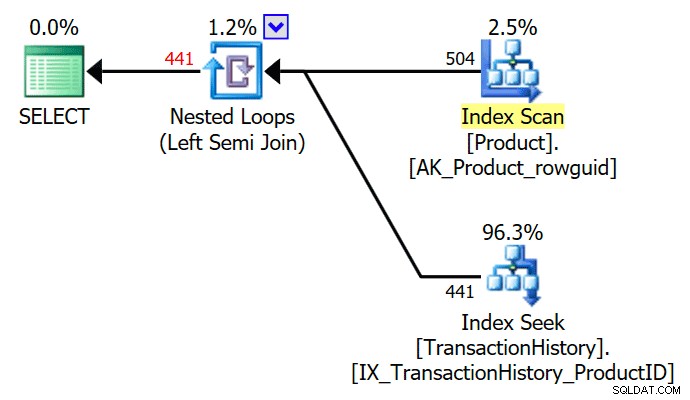
PILIH P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
TOP (1) di subquery yang ada disederhanakan oleh pengoptimal, memberikan rencana eksekusi semi-gabungan sederhana:
Pengoptimal juga dapat menghapus DISTINCT yang berlebihan atau GROUP BY dalam subquery. Berikut ini semua menghasilkan rencana yang sama seperti di atas:
-- Redundant DISTINCTSELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT DISTINCT TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID ); -- Redundant GROUP BYSELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( PILIH TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID GROUP BY TH.ProductID ); -- Redundant DISTINCT TOP (1)PILIH P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT DISTINCT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
Ringkasan dan Pemikiran Akhir
Hanya lamar loop bersarang semi join dapat memiliki tujuan baris yang ditetapkan oleh pengoptimal. Ini adalah satu-satunya jenis gabungan yang mendorong predikat gabungan turun dari gabungan, memungkinkan pengujian keberadaan kecocokan dilakukan awal . Loop bersarang yang tidak berkorelasi semi gabung hampir tidak pernah* menetapkan tujuan baris, dan hash atau gabungan juga tidak digabungkan. Terapkan loop bersarang dapat dibedakan dari loop bersarang yang tidak berkorelasi bergabung dengan adanya referensi luar (bukan predikat) pada loop bersarang, bergabunglah dengan operator untuk penerapan.
Peluang untuk melihat penerapan semi gabung dalam rencana eksekusi akhir agak bergantung pada aktivitas pengoptimalan awal. Karena kekurangan sintaks T-SQL langsung, kita harus mengekspresikan semi join dalam istilah tidak langsung. Ini diuraikan menjadi pohon logis yang berisi subkueri, yang diubah oleh aktivitas pengoptimal awal menjadi penerapan, dan kemudian menjadi semi-gabungan yang tidak berkorelasi jika memungkinkan.
Aktivitas penyederhanaan ini menentukan apakah semi join logis disajikan ke pengoptimal berbasis biaya sebagai semi join yang berlaku atau reguler. Saat disajikan sebagai berlaku yang logis semi join, CBO hampir pasti akan menghasilkan rencana eksekusi akhir yang menampilkan loop bersarang yang diterapkan secara fisik (dan dengan demikian menetapkan tujuan baris). Ketika disajikan dengan semi-join yang tidak berkorelasi, CBO mungkin pertimbangkan transformasi ke aplikasi (atau mungkin tidak). Pilihan terakhir dari rencana adalah serangkaian keputusan berbasis biaya seperti biasa.
Seperti semua sasaran baris, sasaran baris semi gabung bisa menjadi hal yang baik atau buruk untuk kinerja. Mengetahui bahwa penerapan semi join menetapkan tujuan baris setidaknya akan membantu orang mengenali dan mengatasi penyebabnya jika masalah harus terjadi. Solusinya tidak akan selalu (atau bahkan biasanya) menonaktifkan sasaran baris untuk kueri. Peningkatan dalam pengindeksan (dan/atau kueri) sering kali dapat dilakukan untuk menyediakan cara yang efisien untuk menemukan baris pertama yang cocok.
Saya akan membahas anti semi join di artikel terpisah, melanjutkan rangkaian tujuan baris.
* Pengecualian adalah loop bersarang yang tidak berkorelasi semi join tanpa predikat join (pemandangan yang tidak biasa). Ini menetapkan sasaran baris.