Banyak kode T-SQL produksi ditulis dengan asumsi implisit bahwa data yang mendasarinya tidak akan berubah selama eksekusi. Seperti yang kita lihat di artikel sebelumnya dalam seri ini, ini adalah asumsi yang tidak aman karena entri data dan indeks dapat berpindah-pindah di bawah kita, bahkan selama eksekusi satu pernyataan.
Jika programmer T-SQL menyadari jenis kebenaran dan masalah integritas data yang dapat muncul karena modifikasi data secara bersamaan oleh proses lain, solusi yang paling umum ditawarkan adalah membungkus pernyataan yang rentan dalam suatu transaksi. Tidak jelas bagaimana alasan yang sama akan diterapkan pada kasus pernyataan tunggal, yang sudah dibungkus dengan transaksi komit otomatis secara default.
Mengesampingkan itu sejenak, gagasan melindungi area penting kode T-SQL dengan transaksi tampaknya didasarkan pada kesalahpahaman tentang perlindungan yang ditawarkan oleh properti transaksi ACID. Elemen penting dari akronim untuk diskusi ini adalah Isolasi Properti. Idenya adalah bahwa menggunakan transaksi secara otomatis memberikan isolasi lengkap dari efek aktivitas bersamaan lainnya.
Faktanya adalah bahwa transaksi di bawah SERIALIZABLE hanya memberikan gelar isolasi, yang bergantung pada tingkat isolasi transaksi yang efektif saat ini. Untuk memahami apa artinya semua ini bagi T kita sehari-hari Untuk praktik pengkodean SQL, pertama-tama kita akan melihat secara mendetail pada tingkat isolasi serial.
Isolasi Serializable
Serializable adalah yang paling terisolasi dari tingkat isolasi transaksi standar. Ini juga merupakan default tingkat isolasi yang ditentukan oleh standar SQL, meskipun SQL Server (seperti kebanyakan sistem database komersial) berbeda dari standar dalam hal ini. Tingkat isolasi default di SQL Server adalah read-commit, tingkat isolasi yang lebih rendah yang akan kita jelajahi nanti di seri ini.
Definisi tingkat isolasi serial dalam standar SQL-92 berisi teks berikut (penekanan milik saya):
Eksekusi serial didefinisikan sebagai eksekusi operasi eksekusi SQL-transactions secara bersamaan yang menghasilkan efek yang sama seperti beberapa eksekusi serial dari transaksi SQL yang sama. Eksekusi serial adalah eksekusi di mana setiap transaksi SQL dijalankan hingga selesai sebelum transaksi SQL berikutnya dimulai.
Ada perbedaan penting yang harus dibuat di sini antara yang benar-benar berseri eksekusi (di mana setiap transaksi benar-benar berjalan secara eksklusif hingga selesai sebelum transaksi berikutnya dimulai) dan dapat dibuat serial isolasi, di mana transaksi hanya diperlukan untuk memiliki efek yang sama seolah-olah mereka dieksekusi secara berurutan (dalam urutan yang tidak ditentukan).
Dengan kata lain, sistem basis data yang sebenarnya diizinkan untuk secara fisik tumpang tindih eksekusi transaksi serial dalam waktu (sehingga meningkatkan konkurensi) selama efek dari transaksi tersebut masih sesuai dengan beberapa kemungkinan urutan eksekusi serial. Dengan kata lain, transaksi yang dapat diserialisasikan berpotensi dapat dibuat bersambung bukannya sebenarnya diserialisasikan .
Transaksi yang Dapat Diurutkan Secara Logis
Kesampingkan semua pertimbangan fisik (seperti penguncian) sejenak, dan pikirkan hanya pemrosesan logis dari dua transaksi bersambung bersamaan.
Pertimbangkan sebuah tabel yang berisi sejumlah besar baris, lima di antaranya kebetulan memenuhi beberapa predikat kueri yang menarik. Transaksi serial T1 mulai menghitung jumlah baris dalam tabel yang cocok dengan predikat ini. Beberapa saat setelah T1 dimulai, tetapi sebelum dijalankan, transaksi serial kedua T2 dimulai. Transaksi T2 menambahkan empat baris baru yang juga memenuhi predikat kueri ke tabel, dan melakukan. Diagram di bawah menunjukkan urutan waktu peristiwa:

Pertanyaannya adalah, berapa banyak baris yang harus dikueri dalam transaksi serial T1 hitung? Ingat kita hanya memikirkan persyaratan logis di sini, jadi hindari memikirkan kunci mana yang mungkin diambil dan seterusnya.
Kedua transaksi secara fisik tumpang tindih dalam waktu, yang baik-baik saja. Isolasi serializable hanya mensyaratkan bahwa hasil dari dua transaksi ini sesuai dengan beberapa kemungkinan eksekusi serial. Jelas ada dua kemungkinan untuk jadwal serial logis transaksi T1 dan T2 :
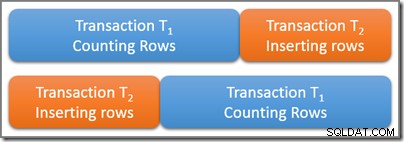
Menggunakan jadwal serial pertama yang mungkin (T1 lalu T2 ) T1 menghitung kueri akan melihat lima baris , karena transaksi kedua tidak dimulai sampai transaksi pertama selesai. Menggunakan kemungkinan jadwal logis kedua, T1 kueri akan menghitung sembilan baris , karena penyisipan empat baris diselesaikan secara logis sebelum transaksi penghitungan dimulai.
Kedua jawaban secara logis benar di bawah isolasi serial. Selain itu, tidak ada jawaban lain yang memungkinkan (jadi transaksi T1 tidak bisa menghitung tujuh baris, misalnya). Manakah dari dua kemungkinan hasil yang benar-benar diamati bergantung pada waktu yang tepat dan sejumlah detail implementasi khusus untuk mesin database yang digunakan.
Perhatikan bahwa kami tidak menyimpulkan bahwa transaksi sebenarnya entah bagaimana disusun ulang pada waktunya. Eksekusi fisik bebas untuk tumpang tindih seperti yang ditunjukkan pada diagram pertama, selama mesin database memastikan hasil mencerminkan apa yang akan terjadi jika dieksekusi di salah satu dari dua kemungkinan urutan serial.
Serializable dan Fenomena Concurrency
Selain serialisasi logis, standar SQL juga menyebutkan bahwa transaksi yang beroperasi pada tingkat isolasi serial tidak boleh mengalami fenomena konkurensi tertentu. Itu tidak boleh membaca data yang tidak dikomit (tidak ada bacaan kotor ); dan setelah data dibaca, pengulangan dari operasi yang sama harus mengembalikan kumpulan data yang sama persis (pembacaan berulang tanpa hantu ).
Standar tersebut menyatakan bahwa fenomena konkurensi tersebut dikecualikan pada tingkat isolasi yang dapat diserialkan sebagai konsekuensi langsung mengharuskan transaksi menjadi serial secara logis. Dengan kata lain, persyaratan serializability cukup dengan sendirinya untuk menghindari pembacaan kotor, pembacaan yang tidak dapat diulang, dan fenomena phantom concurrency. Sebaliknya, menghindari tiga fenomena konkurensi saja tidak cukup untuk menjamin serializability, seperti yang akan kita lihat segera.
Secara intuitif, transaksi bersambung menghindari semua fenomena terkait konkurensi karena mereka diharuskan untuk bertindak seolah-olah mereka telah dieksekusi dalam isolasi lengkap. Dalam hal ini, tingkat isolasi transaksi yang dapat diserialisasi sangat cocok dengan harapan umum programmer T-SQL.
Implementasi Serializable
SQL Server kebetulan menggunakan implementasi penguncian tingkat isolasi serial, di mana kunci fisik diperoleh dan dipegang ke akhir transaksi (karenanya petunjuk tabel yang tidak digunakan lagi HOLDLOCK sebagai sinonim untuk SERIALIZABLE ).
Strategi ini tidak cukup untuk memberikan jaminan teknis serializability penuh, karena data baru atau yang diubah dapat muncul dalam rentang baris yang sebelumnya diproses oleh transaksi. Fenomena konkurensi ini dikenal sebagai phantom, dan dapat mengakibatkan efek yang tidak mungkin terjadi dalam jadwal serial mana pun.
Untuk memastikan perlindungan terhadap fenomena phantom concurrency, kunci yang diambil oleh SQL Server pada tingkat isolasi serial juga dapat menggabungkan penguncian rentang kunci untuk mencegah baris baru atau yang diubah muncul di antara nilai kunci indeks yang diperiksa sebelumnya. Kunci rentang tidak selalu diperoleh di bawah tingkat isolasi serial; semua yang dapat kita katakan secara umum adalah bahwa SQL Server selalu memperoleh kunci yang cukup untuk memenuhi persyaratan logis dari tingkat isolasi serial. Faktanya, implementasi penguncian cukup sering memperoleh lebih banyak, dan lebih ketat, kunci daripada yang benar-benar dibutuhkan untuk menjamin serializability, tapi saya ngelantur.
Penguncian hanyalah salah satu kemungkinan implementasi fisik dari tingkat isolasi serial. Kita harus berhati-hati untuk memisahkan secara mental perilaku spesifik implementasi penguncian SQL Server dari definisi logis serializable.
Sebagai contoh strategi fisik alternatif, lihat implementasi PostgreSQL dari isolasi snapshot serial, meskipun ini hanyalah salah satu alternatif. Setiap pelaksanaan fisik yang berbeda tentunya memiliki kelebihan dan kelemahan tersendiri. Sebagai tambahan, perhatikan bahwa Oracle masih belum menyediakan implementasi tingkat isolasi serial yang sepenuhnya sesuai. Ini memiliki tingkat isolasi bernama serializable, tetapi tidak benar-benar menjamin bahwa transaksi akan dijalankan sesuai dengan beberapa kemungkinan jadwal serial. Oracle malah menyediakan isolasi snapshot ketika serializable diminta, dengan cara yang sama seperti yang dilakukan PostgreSQL sebelum isolasi snapshot serializable (SSI ) diimplementasikan.
Isolasi snapshot tidak mencegah anomali konkurensi seperti write skew, yang tidak mungkin dilakukan di bawah isolasi yang benar-benar serial. Jika Anda tertarik, Anda dapat menemukan contoh kemiringan penulisan dan efek konkurensi lainnya yang diizinkan oleh isolasi snapshot di tautan SSI di atas. Kami juga akan membahas implementasi SQL Server dari tingkat isolasi snapshot nanti di seri ini.
Tampilan tepat waktu?
Salah satu alasan saya menghabiskan waktu berbicara tentang perbedaan antara serializability logis dan eksekusi serial fisik adalah bahwa sebaliknya mudah untuk menyimpulkan jaminan yang mungkin tidak benar-benar ada. Misalnya, jika Anda menganggap transaksi yang dapat diurutkan sebagai sebenarnya mengeksekusi satu demi satu, Anda mungkin menyimpulkan bahwa transaksi serializable akan selalu melihat database seperti yang ada pada awal transaksi, memberikan tampilan point-in-time.
Sebenarnya, ini adalah detail khusus implementasi. Ingat contoh sebelumnya, di mana transaksi serial T1 mungkin sah menghitung lima atau sembilan baris. Jika hitungan sembilan dikembalikan, transaksi pertama dengan jelas melihat baris yang tidak ada pada saat transaksi dimulai. Hasil ini dimungkinkan di SQL Server tetapi tidak di PostgreSQL SSI, meskipun kedua implementasi mematuhi perilaku logis yang ditentukan untuk tingkat isolasi serial.
Di SQL Server, transaksi serializable tidak selalu melihat data seperti yang ada pada awal transaksi. Sebaliknya, rincian implementasi SQL Server berarti bahwa transaksi serial melihat data berkomitmen terbaru, pada saat data pertama kali dikunci untuk akses. Selain itu, kumpulan data commit terakhir yang akhirnya dibaca dijamin tidak akan berubah keanggotaannya sebelum transaksi berakhir.
Lain kali
Bagian berikutnya dalam seri ini memeriksa tingkat isolasi baca berulang, yang memberikan jaminan isolasi transaksi yang lebih lemah daripada yang dapat dibuat serial.
[ Lihat indeks untuk keseluruhan seri ]