Terlalu sering saya melihat orang-orang mengeluh tentang bagaimana log transaksi mereka mengambil alih hard disk mereka. Sering kali ternyata mereka melakukan operasi penghapusan besar, seperti pembersihan atau pengarsipan data, dalam satu transaksi besar.
Saya ingin menjalankan beberapa tes untuk menunjukkan dampak, pada durasi dan log transaksi, dari melakukan operasi data yang sama dalam potongan versus satu transaksi. Saya membuat database dan mengisinya dengan tabel besar SalesOrderDetailEnlarged ,
Setelah mengisi tabel, saya mencadangkan database, mencadangkan log, dan menjalankan DBCC SHRINKFILE (jangan tembak saya) sehingga dampak pada file log dapat ditetapkan dari awal (mengetahui sepenuhnya bahwa operasi ini *akan* menyebabkan log transaksi bertambah).
Saya sengaja menggunakan disk mekanis sebagai lawan dari SSD. Meskipun kita mungkin mulai melihat tren yang lebih populer untuk pindah ke SSD, itu belum terjadi dalam skala yang cukup besar; dalam banyak kasus masih terlalu mahal untuk melakukannya di perangkat penyimpanan besar.
Ujian
Jadi selanjutnya saya harus menentukan apa yang ingin saya uji untuk dampak terbesar. Karena saya baru saja terlibat dalam diskusi dengan rekan kerja kemarin tentang menghapus data dalam potongan, saya memilih hapus. Dan karena indeks berkerumun pada tabel ini ada di SalesOrderID , saya tidak ingin menggunakannya – itu akan terlalu mudah (dan sangat jarang cocok dengan cara penanganan penghapusan di kehidupan nyata). Jadi saya memutuskan untuk mengikuti serangkaian ProductID nilai, yang akan memastikan saya akan mencapai banyak halaman dan membutuhkan banyak pencatatan. Saya menentukan produk mana yang akan dihapus dengan kueri berikut:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Ini menghasilkan hasil berikut:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Ini akan menghapus 456.960 baris (sekitar 10% dari tabel), tersebar di banyak pesanan. Ini bukan modifikasi realistis dalam konteks ini, karena akan mengacaukan total pesanan yang telah dihitung sebelumnya, dan Anda tidak dapat benar-benar menghapus produk dari pesanan yang telah dikirimkan. Tetapi menggunakan basis data yang kita semua kenal dan sukai, ini serupa dengan, katakanlah, menghapus pengguna dari situs forum, dan juga menghapus semua pesan mereka – skenario nyata yang pernah saya lihat di alam liar.
Jadi satu tes adalah melakukan yang berikut, penghapusan satu kali:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Saya tahu ini akan membutuhkan pemindaian besar-besaran dan sangat membebani log transaksi. Itu intinya. :-)
Saat itu sedang berjalan, saya menyusun skrip berbeda yang akan melakukan penghapusan ini dalam potongan:25.000, 50.000, 75.000 dan 100.000 baris sekaligus. Setiap potongan akan dikomit dalam transaksinya sendiri (sehingga jika Anda perlu menghentikan skrip, Anda bisa, dan semua potongan sebelumnya sudah dikomit, alih-alih harus memulai dari awal), dan tergantung pada model pemulihan, akan diikuti dengan salah satu CHECKPOINT atau BACKUP LOG untuk meminimalkan dampak berkelanjutan pada log transaksi. (Saya juga akan menguji tanpa operasi ini.) Ini akan terlihat seperti ini (Saya tidak akan repot-repot dengan penanganan kesalahan dan basa-basi lainnya untuk tes ini, tetapi Anda tidak boleh terlalu angkuh):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Tentu saja, setelah setiap pengujian, saya akan mengembalikan cadangan asli database WITH REPLACE, RECOVERY , atur model pemulihan yang sesuai, dan jalankan pengujian berikutnya.
Hasil
Hasil tes pertama tidak terlalu mengejutkan sama sekali. Untuk melakukan penghapusan dalam satu pernyataan, butuh 42 detik secara penuh, dan 43 detik secara sederhana. Dalam kedua kasus ini, log bertambah menjadi 579 MB.
Serangkaian tes berikutnya memiliki beberapa kejutan bagi saya. Salah satunya adalah, meskipun metode chunking ini secara signifikan mengurangi dampak pada file log, hanya beberapa kombinasi yang mendekati durasi, dan tidak ada yang benar-benar lebih cepat. Lain adalah bahwa, secara umum, chunking dalam pemulihan penuh (tanpa melakukan pencadangan log di antara langkah-langkah) dilakukan lebih baik daripada operasi yang setara dalam pemulihan sederhana. Berikut adalah hasil untuk durasi dan dampak log:
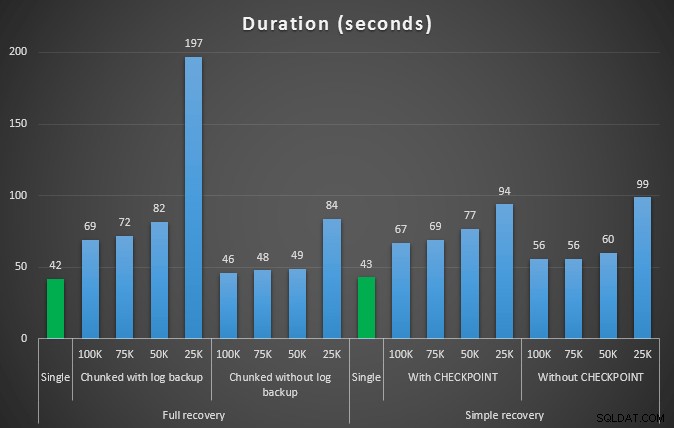
Durasi, dalam detik, dari berbagai operasi penghapusan menghapus 457 ribu baris
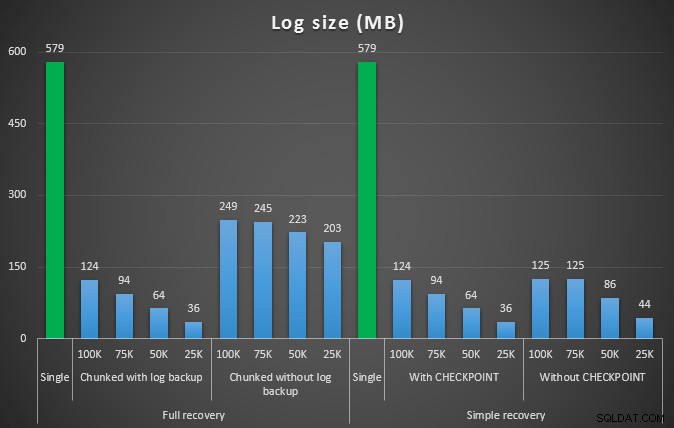
Ukuran log, dalam MB, setelah berbagai operasi penghapusan menghapus 457 ribu baris
Sekali lagi, secara umum, sementara ukuran log berkurang secara signifikan, durasinya meningkat. Anda dapat menggunakan jenis skala ini untuk menentukan apakah lebih penting untuk mengurangi dampak pada ruang disk atau meminimalkan jumlah waktu yang dihabiskan. Untuk durasi yang kecil (dan lagi pula, sebagian besar proses ini dijalankan di latar belakang), Anda dapat menghemat secara signifikan (hingga 94%, dalam pengujian ini) dalam penggunaan ruang log.
Perhatikan bahwa saya tidak mencoba salah satu dari tes ini dengan kompresi diaktifkan (mungkin tes di masa mendatang!), Dan saya meninggalkan pengaturan autogrow log pada default yang mengerikan (10%) – sebagian karena kemalasan dan sebagian karena banyak lingkungan di luar sana telah dipertahankan pengaturan yang mengerikan ini.
Tetapi bagaimana jika saya memiliki lebih banyak data?
Selanjutnya saya pikir saya harus menguji ini pada database yang sedikit lebih besar. Jadi saya membuat database lain dan membuat salinan baru yang lebih besar dari dbo.SalesOrderDetailEnlarged . Kira-kira sepuluh kali lebih besar, sebenarnya. Kali ini bukan kunci utama pada SalesOrderID, SalesorderDetailID , saya baru saja menjadikannya indeks berkerumun (untuk memungkinkan duplikat), dan mengisinya dengan cara ini:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); Karena keterbatasan ruang disk, saya harus pindah dari VM laptop saya untuk pengujian ini (dan memilih kotak 40-inti, dengan 128 GB RAM, yang kebetulan duduk di sekitar kuasi-idle :-)), dan masih itu bukan proses yang cepat dengan cara apapun. Populasi tabel dan pembuatan indeks membutuhkan waktu ~24 menit.
Tabel memiliki 48,5 juta baris dan menggunakan disk 7,9 GB (data 4,9 GB, dan indeks 2,9 GB).
Kali ini, pertanyaan saya untuk menentukan satu set kandidat ProductID yang baik nilai yang akan dihapus:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Menghasilkan hasil berikut:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Jadi kita akan menghapus 4.455.360 baris, sedikit di bawah 10% dari tabel. Mengikuti pola yang mirip dengan pengujian di atas, kita akan menghapus semua dalam satu bidikan, lalu dalam potongan 500.000, 250.000, dan 100.000 baris.
Hasil:
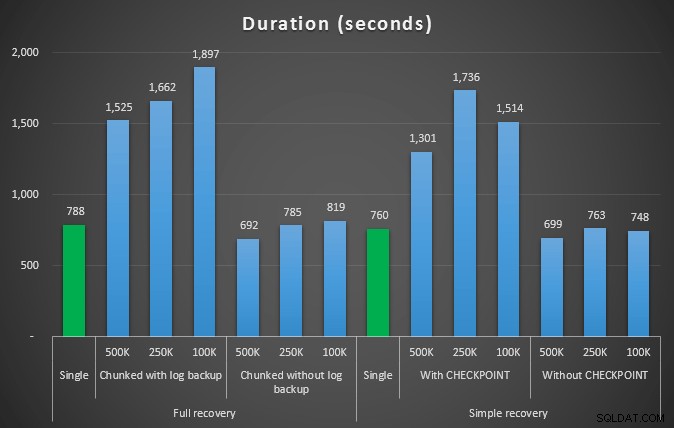 Durasi, dalam detik, dari berbagai operasi penghapusan menghapus 4,5 MM baris
Durasi, dalam detik, dari berbagai operasi penghapusan menghapus 4,5 MM baris
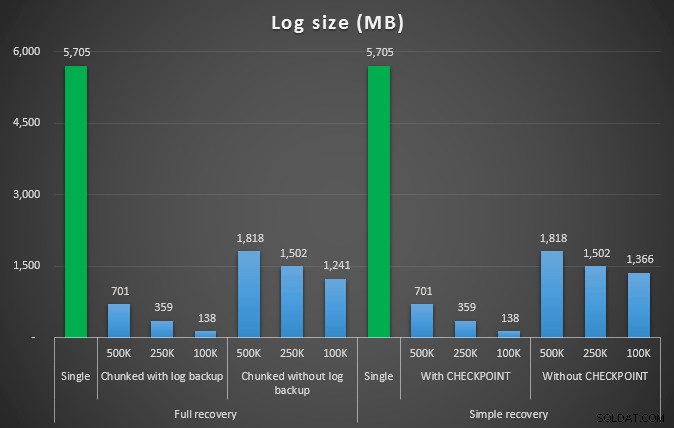 Ukuran log, dalam MB, setelah berbagai operasi penghapusan menghapus 4,5 MM baris
Ukuran log, dalam MB, setelah berbagai operasi penghapusan menghapus 4,5 MM baris
Jadi sekali lagi, kami melihat pengurangan yang signifikan dalam ukuran file log (lebih dari 97% dalam kasus dengan ukuran potongan terkecil 100K); namun, pada skala ini, kami melihat beberapa kasus di mana kami juga menyelesaikan penghapusan dalam waktu yang lebih singkat, bahkan dengan semua peristiwa autogrow yang pasti telah terjadi. Kedengarannya seperti win-win bagi saya!
Kali ini dengan log yang lebih besar
Sekarang, saya ingin tahu bagaimana penghapusan yang berbeda ini akan dibandingkan dengan file log yang berukuran sebelumnya untuk mengakomodasi operasi besar seperti itu. Berpegang pada basis data kami yang lebih besar, saya memperluas file log ke 6 GB, mencadangkannya, lalu menjalankan pengujian lagi:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Hasil, membandingkan durasi dengan file log tetap dengan kasus di mana file harus terus berkembang secara otomatis:
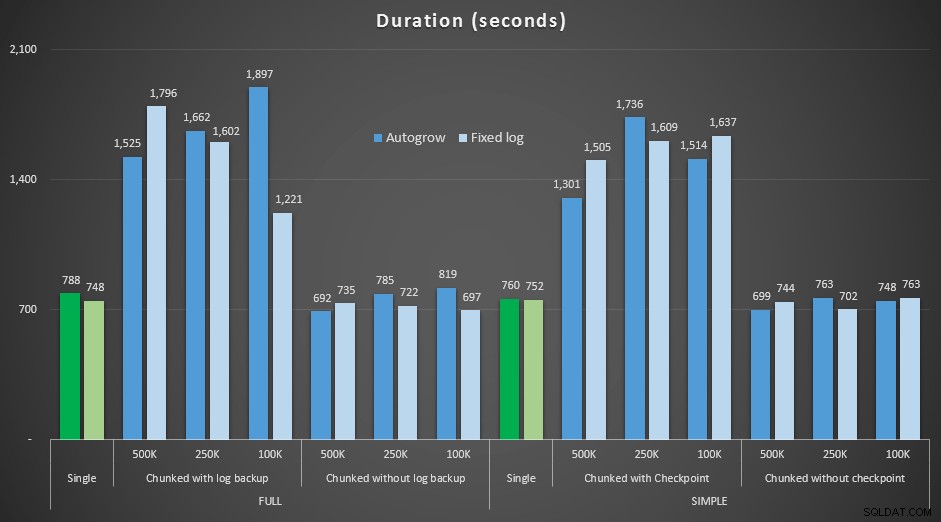
Durasi, dalam detik, dari berbagai operasi penghapusan menghapus 4,5 MM baris , membandingkan ukuran log tetap dan pertumbuhan otomatis
Sekali lagi kita melihat bahwa metode yang dihapus chunk menjadi batch, dan *tidak* melakukan pencadangan log atau pos pemeriksaan setelah setiap langkah, menyaingi operasi tunggal yang setara dalam hal durasi. Faktanya, lihat bahwa sebagian besar benar-benar tampil dalam waktu keseluruhan yang lebih sedikit, dengan bonus tambahan bahwa transaksi lain dapat masuk dan keluar di antara langkah-langkah. Yang merupakan hal yang baik kecuali jika Anda ingin operasi penghapusan ini memblokir semua transaksi yang tidak terkait.
Kesimpulan
Jelas bahwa tidak ada jawaban tunggal yang benar untuk masalah ini – ada banyak variabel "tergantung" yang melekat. Mungkin perlu beberapa percobaan untuk menemukan nomor ajaib Anda, karena akan ada keseimbangan antara overhead yang diperlukan untuk membuat cadangan log dan berapa banyak pekerjaan dan waktu yang Anda hemat pada ukuran potongan yang berbeda. Tetapi jika Anda berencana untuk menghapus atau mengarsipkan sejumlah besar baris, kemungkinan besar Anda akan lebih baik, secara keseluruhan, melakukan perubahan dalam potongan, daripada dalam satu, transaksi besar – meskipun nomor durasi tampaknya membuat bahwa operasi yang kurang menarik. Ini tidak semua tentang durasi – jika Anda tidak memiliki cukup file log yang dialokasikan sebelumnya, dan tidak memiliki ruang untuk mengakomodasi transaksi besar seperti itu, mungkin jauh lebih baik untuk meminimalkan pertumbuhan file log dengan mengorbankan durasi, dalam hal ini Anda sebaiknya mengabaikan grafik durasi di atas dan memperhatikan grafik ukuran log.
Jika Anda mampu membeli ruang, Anda mungkin masih ingin atau mungkin tidak ingin menyesuaikan ukuran log transaksi Anda sebelumnya. Bergantung pada skenario, terkadang menggunakan pengaturan autogrow default berakhir sedikit lebih cepat dalam pengujian saya daripada menggunakan file log tetap dengan banyak ruang. Selain itu, mungkin sulit untuk menebak dengan tepat berapa banyak yang Anda perlukan untuk mengakomodasi transaksi besar yang belum Anda jalankan. Jika Anda tidak dapat menguji skenario yang realistis, cobalah yang terbaik untuk menggambarkan skenario terburuk Anda – kemudian, demi keamanan, gandakan. Kimberly Tripp (blog | @KimberlyLTripp) memiliki beberapa saran bagus dalam posting ini:8 Langkah untuk throughput Log Transaksi yang lebih baik – dalam konteks ini, khususnya, lihat poin #6. Terlepas dari bagaimana Anda memutuskan untuk menghitung kebutuhan ruang log Anda, jika Anda pada akhirnya akan membutuhkan ruang, lebih baik untuk mengambilnya dengan cara yang terkontrol jauh sebelumnya, daripada menghentikan proses bisnis Anda sementara mereka menunggu pertumbuhan otomatis ( apalagi banyak!).
Aspek lain yang sangat penting dari hal ini yang tidak saya ukur secara eksplisit adalah dampak terhadap konkurensi – sekelompok transaksi yang lebih pendek, secara teori, akan berdampak lebih kecil pada operasi konkuren. Sementara satu penghapusan memakan waktu sedikit lebih sedikit daripada operasi batch yang lebih lama, itu menahan semua kuncinya untuk seluruh durasi itu, sementara operasi chunked akan memungkinkan transaksi antrian lainnya menyelinap di antara setiap transaksi. Dalam posting mendatang saya akan mencoba untuk melihat lebih dekat pada dampak ini (dan saya juga memiliki rencana untuk analisis lebih dalam lainnya).