Pengantar
Ada dua aliran pemikiran tentang melakukan perhitungan di database Anda:orang yang menganggapnya hebat, dan orang yang salah. Ini bukan untuk mengatakan bahwa dunia fungsi, prosedur tersimpan, kolom yang dihasilkan atau dihitung, dan pemicu semuanya adalah sinar matahari dan mawar! Alat-alat ini jauh dari sangat mudah, dan implementasi yang dianggap buruk dapat berkinerja buruk, membuat trauma pengelolanya, dan banyak lagi, yang menjelaskan adanya kontroversi.
Tetapi basis data, menurut definisi, sangat bagus dalam memproses dan memanipulasi informasi, dan kebanyakan dari mereka membuat kontrol dan kekuatan yang sama tersedia untuk penggunanya (SQLite dan MS Access pada tingkat yang lebih rendah). Program pemrosesan data eksternal dimulai dengan langkah mundur karena harus menarik informasi keluar dari database, seringkali melalui jaringan, sebelum mereka dapat melakukan apa pun. Dan di mana program database dapat mengambil keuntungan penuh dari operasi set asli, pengindeksan, tabel sementara, dan buah lain dari setengah abad evolusi database, program eksternal dengan kompleksitas apa pun cenderung melibatkan beberapa tingkat penemuan kembali roda. Jadi mengapa tidak menjalankan database?
Inilah mengapa Anda mungkin tidak ingin memprogram database Anda!
- Fungsi database cenderung menjadi tidak terlihat -- khususnya pemicu. Kelemahan ini berskala kira-kira dengan ukuran tim dan/atau aplikasi yang berinteraksi dengan database, karena lebih sedikit orang yang mengingat atau menyadari pemrograman dalam database. Dokumentasi membantu, tetapi hanya sedikit.
- SQL adalah bahasa yang dibuat khusus untuk memanipulasi kumpulan data. Ini tidak terlalu bagus untuk hal-hal yang tidak memanipulasi kumpulan data, dan itu kurang bagus jika hal-hal lain menjadi lebih rumit.
- Kemampuan RDBMS dan dialek SQL berbeda. Kolom sederhana yang dihasilkan didukung secara luas, tetapi porting logika database yang lebih kompleks ke toko lain membutuhkan waktu dan usaha minimal.
- Upgrade skema database biasanya lebih rumit daripada upgrade aplikasi. Logika yang berubah dengan cepat paling baik dipertahankan di tempat lain, meskipun hal itu dapat dilihat lagi setelah semuanya stabil.
- Mengelola program database tidak semudah yang diharapkan. Banyak alat migrasi skema melakukan sedikit atau tidak sama sekali untuk organisasi, yang mengarah ke perbedaan yang luas dan tinjauan kode yang berat (grafik ketergantungan sqitch dan pengerjaan ulang objek individual menjadikannya pengecualian penting, dan migra berusaha menghindari masalah sepenuhnya). Dalam pengujian, kerangka kerja seperti pgTAP dan utPLSQL meningkatkan pengujian integrasi kotak hitam, tetapi juga menunjukkan dukungan ekstra dan komitmen pemeliharaan.
- Dengan basis kode eksternal yang mapan, setiap perubahan struktural cenderung membutuhkan banyak usaha dan berisiko.
Di sisi lain, untuk tugas-tugas yang sesuai, SQL menawarkan kecepatan, ringkas, daya tahan, dan kesempatan untuk "mengkanonisasi" alur kerja otomatis. Pemodelan data lebih dari sekadar menjepit entitas seperti serangga ke karton, dan perbedaan antara data bergerak dan data diam adalah hal yang rumit. Istirahat adalah gerakan yang benar-benar lebih lambat di tingkat yang lebih baik; informasi selalu mengalir dari sini ke sana, dan programabilitas basis data adalah alat yang ampuh untuk mengelola dan mengarahkan arus tersebut.
Beberapa mesin basis data membagi perbedaan antara SQL dan bahasa pemrograman lain dengan mengakomodasi bahasa pemrograman lain itu juga. SQL Server mendukung fungsi yang ditulis dalam bahasa .NET Framework apa pun; Oracle memiliki prosedur tersimpan Java; PostgreSQL memungkinkan ekstensi dengan C dan dapat diprogram oleh pengguna dengan Python, Perl, dan Tcl, dengan plugin yang menambahkan skrip shell, R, JavaScript, dan banyak lagi. Membulatkan tersangka yang biasa, SQL atau tidak sama sekali untuk MySQL dan MariaDB, MS Access hanya dapat diprogram dalam VBA, dan SQLite sama sekali tidak dapat diprogram oleh pengguna.
Menggunakan bahasa non-SQL adalah pilihan jika SQL tidak memadai untuk beberapa tugas atau jika Anda ingin menggunakan kembali kode lain, tetapi itu tidak akan membantu Anda mengatasi masalah lain yang membuat pemrograman database menjadi pedang bermata banyak. Jika ada, beralih ke ini semakin memperumit penerapan dan interoperabilitas. Scriptor peringatan:biarkan penulis berhati-hati.
Fungsi vs Prosedur
Seperti aspek lain dari penerapan standar SQL, detail persisnya sedikit berbeda dari RDBMS ke RDBMS. Secara umum:
- Fungsi tidak dapat mengontrol transaksi.
- Fungsi mengembalikan nilai; prosedur dapat mengubah parameter yang ditunjuk
OUTatauINOUTyang kemudian dapat dibaca dalam konteks panggilan, tetapi tidak pernah mengembalikan hasil (kecuali SQL Server). - Fungsi dipanggil dari dalam pernyataan SQL untuk melakukan beberapa pekerjaan pada catatan yang diambil atau disimpan, sementara prosedur berdiri sendiri.
Lebih khusus lagi, MySQL juga melarang rekursi dan beberapa pernyataan SQL tambahan dalam fungsi. SQL Server melarang fungsi memodifikasi data, menjalankan SQL dinamis, dan menangani kesalahan. PostgreSQL tidak memisahkan prosedur tersimpan dari fungsi sama sekali hingga 2017 dengan versi 11, sehingga fungsi Postgres dapat melakukan hampir semua prosedur yang dapat dilakukan, kecuali kontrol transaksi.
Jadi, yang harus digunakan kapan? Fungsi paling cocok untuk logika yang menerapkan catatan demi catatan saat data disimpan dan diambil. Alur kerja yang lebih kompleks yang dipanggil sendiri dan memindahkan data secara internal lebih baik sebagai prosedur.
Default dan Generasi
Bahkan perhitungan sederhana dapat membuat masalah jika dilakukan cukup sering atau jika ada beberapa implementasi yang bersaing. Operasi pada nilai dalam satu baris -- pikirkan konversi antara satuan metrik dan imperial, mengalikan tarif dengan jam kerja untuk subtotal faktur, menghitung luas poligon geografis -- dapat dideklarasikan dalam definisi tabel untuk mengatasi satu atau masalah lain :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
Sebagian besar RDBMS menawarkan pilihan antara kolom yang dihasilkan "tersimpan" dan "virtual". Dalam kasus sebelumnya, nilai dihitung dan disimpan saat baris dimasukkan atau diperbarui. Ini adalah satu-satunya pilihan dengan PostgreSQL, pada versi 12, dan MS Access. Kolom yang dihasilkan secara virtual dihitung saat dikueri seperti dalam tampilan, sehingga kolom tersebut tidak memakan tempat tetapi akan lebih sering dihitung ulang. Kedua jenis dibatasi dengan ketat:nilai tidak dapat bergantung pada informasi di luar baris tempatnya, nilai tidak dapat diperbarui, dan RDBMS individu dapat memiliki batasan yang lebih spesifik. PostgreSQL, misalnya, melarang mempartisi tabel pada kolom yang dibuat.
Kolom yang dihasilkan adalah alat khusus. Lebih sering, semua yang diperlukan adalah default jika nilai tidak diberikan pada sisipan. Fungsi seperti now() sering muncul sebagai default kolom, tetapi sebagian besar database memungkinkan kustom serta fungsi built-in (kecuali MySQL, di mana hanya current_timestamp mungkin nilai default).
Mari kita ambil contoh yang agak kering tapi sederhana dari nomor lot dalam format YYYYXXX, di mana empat digit pertama mewakili tahun berjalan dan tiga digit terakhir merupakan penghitung kenaikan:lot pertama yang diproduksi tahun ini adalah 2020001, kedua 2020002, dan seterusnya . Tidak ada tipe default atau fungsi bawaan yang menghasilkan nilai seperti ini, tetapi fungsi yang ditentukan pengguna dapat memberi nomor pada setiap lot
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
Mereferensikan Data dalam Fungsi
Pendekatan urutan di atas memiliki satu kelemahan penting (dan lot_counter akan tetap memiliki nilai yang sama seperti pada tanggal 31 Desember. Namun, ada lebih dari satu cara untuk melacak berapa banyak yang telah dibuat dalam setahun, dan dengan menanyakan lots sendiri adalah next_lot_number fungsi dapat menjamin nilai yang benar setelah tahun bergulir.
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
Alur kerja
Bahkan fungsi pernyataan tunggal memiliki keunggulan penting dibandingkan kode eksternal:eksekusi tidak pernah meninggalkan keamanan jaminan ACID database. Bandingkan next_lot_number di atas untuk kemungkinan aplikasi klien atau bahkan proses manual, mengeksekusi
Program tersimpan multi-pernyataan membuka ruang kemungkinan yang sangat besar, karena SQL menyertakan semua alat yang Anda butuhkan untuk menulis kode prosedural, dari penanganan pengecualian hingga savepoints (bahkan Turing lengkap dengan fungsi jendela dan ekspresi tabel umum!). Seluruh alur kerja pemrosesan data dapat dilakukan dalam database, meminimalkan paparan ke area lain dari sistem, dan menghilangkan bolak-balik yang memakan waktu antara database dan domain lain.
Begitu banyak arsitektur perangkat lunak secara umum adalah tentang mengelola dan mengisolasi kompleksitas, mencegahnya menyebar melintasi batas antar subsistem. Jika beberapa alur kerja yang kurang lebih rumit melibatkan penarikan data ke backend aplikasi, skrip, atau tugas cron, mencerna dan menambahkannya, dan menyimpan hasilnya -- inilah saatnya untuk menanyakan apa yang sebenarnya perlu dilakukan di luar database.
Seperti disebutkan di atas, ini adalah area di mana perbedaan antara rasa RDBMS dan dialek SQL muncul ke permukaan. Fungsi atau prosedur yang dikembangkan untuk satu database mungkin tidak akan berjalan di database lain tanpa perubahan, baik itu menggantikan TOP SQL Server untuk LIMIT standar klausa atau mengerjakan ulang sepenuhnya bagaimana status sementara disimpan dalam migrasi Oracle ke PostgreSQL perusahaan. Kanonisasi alur kerja Anda dalam SQL juga mengikat Anda ke platform dan dialek Anda saat ini secara lebih menyeluruh daripada hampir semua pilihan lain yang dapat Anda buat.
Komputasi dalam Kueri
Sejauh ini kita telah melihat penggunaan fungsi untuk menyimpan dan memodifikasi data, baik yang terikat pada definisi tabel atau mengelola alur kerja multi-tabel. Di satu sisi, itulah kegunaan yang lebih kuat yang dapat mereka gunakan, tetapi fungsi juga memiliki tempat dalam pengambilan data. Banyak alat yang mungkin sudah Anda gunakan dalam kueri Anda diimplementasikan sebagai fungsi, dari bawaan standar seperti count ke ekstensi seperti jsonb_build_object Postgres , ST_SnapToGrid PostGIS , dan banyak lagi. Tentu saja, karena itu lebih terintegrasi erat dengan database itu sendiri, mereka sebagian besar ditulis dalam bahasa selain SQL (misalnya C dalam kasus PostgreSQL dan PostGIS).
Jika Anda sering menemukan diri Anda (atau berpikir Anda mungkin menemukan diri Anda sendiri) perlu mengambil data dan kemudian melakukan beberapa operasi pada setiap catatan sebelum benar-benar siap, pertimbangkan untuk mengubahnya saat keluar dari database! Memproyeksikan beberapa hari kerja dari tanggal? Menghasilkan perbedaan antara dua JSONB bidang? Hampir semua perhitungan yang hanya bergantung pada informasi yang Anda kueri dapat dilakukan dalam SQL. Dan apa yang dilakukan dalam database -- selama diakses secara konsisten -- adalah kanonik sejauh menyangkut apa pun yang dibangun di atas database.
Harus dikatakan:jika Anda bekerja dengan backend aplikasi, perangkat akses datanya dapat membatasi berapa banyak jarak tempuh yang Anda dapatkan dari menambah hasil kueri dengan fungsi. Sebagian besar pustaka tersebut dapat mengeksekusi SQL arbitrer, tetapi pustaka yang menghasilkan pernyataan SQL umum berdasarkan kelas model mungkin atau mungkin tidak mengizinkan penyesuaian kueri SELECT daftar. Kolom atau tampilan yang dihasilkan dapat menjadi jawaban di sini.
Pemicu dan Konsekuensi
Fungsi dan prosedur cukup kontroversial di antara perancang dan pengguna basis data, tetapi hal-hal benar-benar lepas landas dengan pemicu. Pemicu mendefinisikan tindakan otomatis, biasanya prosedur (SQLite hanya mengizinkan satu pernyataan), untuk dieksekusi sebelum, sesudah, atau sebagai ganti tindakan lain.
Tindakan memulai umumnya menyisipkan, memperbarui, atau menghapus ke tabel, dan prosedur pemicu biasanya dapat diatur untuk mengeksekusi baik untuk setiap catatan atau untuk pernyataan secara keseluruhan. SQL Server juga memungkinkan pemicu pada tampilan yang dapat diperbarui, sebagian besar sebagai cara untuk menerapkan langkah-langkah keamanan yang lebih rinci; dan itu, PostgreSQL, dan Oracle semuanya menawarkan beberapa bentuk acara atau
Penggunaan berisiko rendah yang umum untuk pemicu adalah sebagai batasan ekstra kuat yang mencegah penyimpanan data yang tidak valid. Di semua database relasional utama, hanya kunci utama dan kunci asing dan UNIQUE kendala dapat mengevaluasi informasi di luar catatan kandidat. Tidak mungkin untuk mendeklarasikan dalam definisi tabel bahwa, misalnya, hanya dua lot yang dapat dibuat dalam sebulan -- dan solusi database-dan-kode yang paling sederhana rentan terhadap kondisi balapan yang serupa dengan pendekatan count-then-set ke lot_number di atas. Untuk menerapkan batasan lain yang melibatkan seluruh tabel, atau tabel lainnya, Anda memerlukan
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
Setelah Anda mulai menjalankan lots itu sendiri mungkin merupakan operasi terakhir dari pemicu yang diprakarsai oleh penyisipan ke orders , tanpa pengguna manusia atau backend aplikasi yang diberdayakan untuk menulis ke lots secara langsung. Atau sebagai items ditambahkan ke banyak, pemicu di sana mungkin menangani pembaruan current_quantity , dan mulai beberapa proses lain saat mencapai target_quantity .
Pemicu dan fungsi dapat berjalan pada tingkat akses dari penentunya (di PostgreSQL, SECURITY DEFINER deklarasi di sebelah LANGUAGE suatu fungsi ), yang memberi pengguna yang terbatas kekuatan untuk memulai proses yang lebih luas -- dan menjadikan validasi dan pengujian proses tersebut menjadi lebih penting.
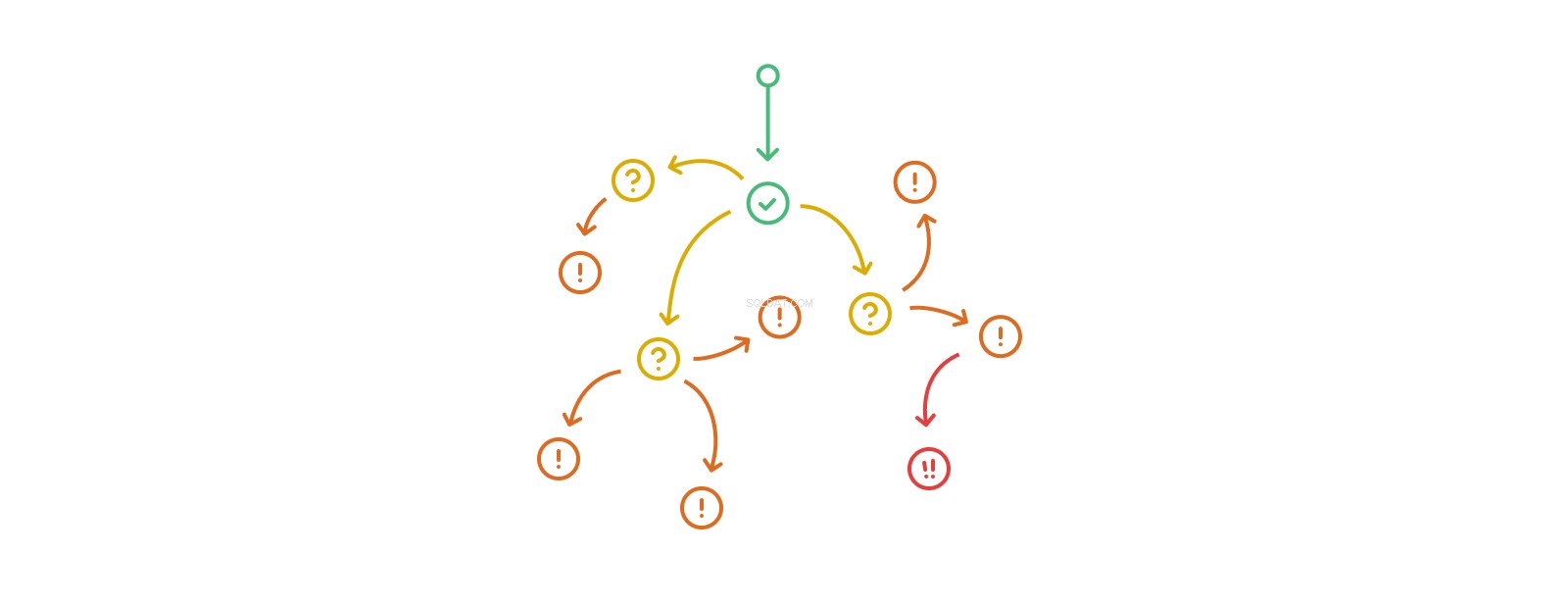
Tumpukan panggilan pemicu-aksi-pemicu-aksi dapat menjadi panjang sewenang-wenang, meskipun rekursi sejati dalam bentuk memodifikasi tabel atau catatan yang sama beberapa kali dalam aliran semacam itu adalah ilegal di beberapa platform dan secara umum merupakan ide yang buruk di hampir semua keadaan. Pemicu bersarang dengan cepat melampaui kemampuan kita untuk memahami luas dan efeknya. Basis data yang banyak menggunakan pemicu bersarang mulai beralih dari ranah rumit ke ranah kompleks, menjadi sulit atau tidak mungkin untuk dianalisis, di-debug, dan diprediksi.
Programmability Praktis
Komputasi dalam database tidak hanya lebih cepat dan lebih ringkas diungkapkan:mereka menghilangkan ambiguitas dan menetapkan standar. Contoh-contoh di atas membebaskan pengguna database dari keharusan menghitung sendiri nomor lot, atau dari kekhawatiran tentang tidak sengaja membuat lebih banyak lot daripada yang dapat mereka tangani. Pengembang aplikasi khususnya sering dilatih untuk menganggap basis data sebagai "penyimpanan bodoh", hanya menyediakan struktur dan ketekunan, dan dengan demikian dapat menemukan diri mereka sendiri -- atau lebih buruk lagi, tidak menyadari bahwa mereka -- dengan kikuk mengartikulasikan di luar basis data apa yang dapat mereka lakukan lebih efektif dalam SQL.
Programabilitas adalah fitur database relasional yang diabaikan secara tidak adil. Ada alasan untuk menghindarinya dan lebih banyak lagi untuk membatasi penggunaannya, tetapi fungsi, prosedur, dan pemicu semuanya merupakan alat yang ampuh untuk membatasi kerumitan yang diterapkan model data Anda pada sistem di mana ia disematkan.