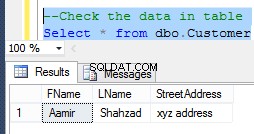
Barisnya identik kecuali untuk ID dan stempel waktu pembuatannya. Untuk menemukan duplikat, Anda harus membandingkan semua kolom lainnya:
Kueri, menemukan kedua baris dengan mencari duplikat dengan ID lain (t2.id <> t1.id ):
select *
from hourly_report_table t1
where exists
(
select *
from hourly_report_table t2
where t2.id <> t1.id
and t2.application = t1.application
and t2.api_date = t1.api_date
and t2.api_hour = t1.api_hour
and ...
);
Pernyataan delete hanya menyimpan satu baris dari sekelompok duplikat dengan membandingkan t2.id < t1.id :
delete
from hourly_report_table t1
where exists
(
select *
from hourly_report_table t2
where t2.id < t1.id
and t2.application = t1.application
and t2.api_date = t1.api_date
and t2.api_hour = t1.api_hour
and ...
);
Jika Anda ingin membatasi ini pada tanggal dan jam tertentu, lakukanlah.
where exists (...) and api_date = date '2020-09-27' and api_hour = 17
Jadi Anda hanya berurusan dengan bagian dari tabel, tetapi Anda harus memastikan bahwa DBMS dapat menemukan data ini dengan cepat (dan tidak harus membaca tabel hole lagi dan lagi). Berikan indeks untuk ini:
create index idx1 on hourly_report_table (api_date, api_hour);