Ini adalah masalah yang cukup umum.
B-Tree biasa indeks tidak baik untuk kueri seperti ini:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
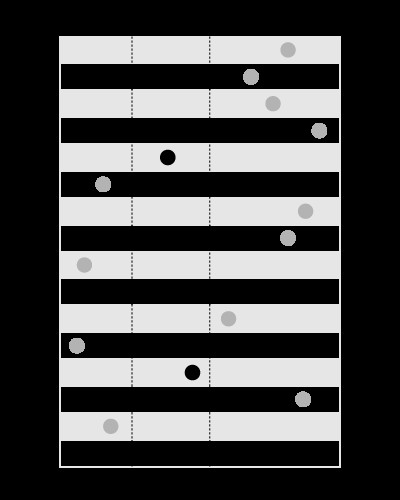
Indeks bagus untuk mencari nilai dalam batas yang diberikan, seperti ini:
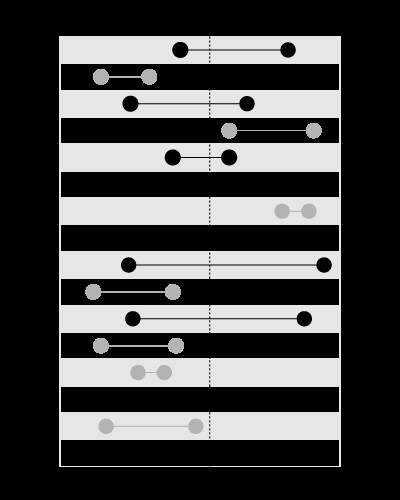
, tetapi tidak untuk mencari batas yang berisi nilai yang diberikan, seperti ini:
Artikel di blog saya ini menjelaskan masalahnya secara lebih rinci:
(model kumpulan bersarang berhubungan dengan jenis predikat yang serupa).
Anda dapat membuat indeks pada time , dengan cara ini intervals akan memimpin dalam bergabung, waktu berkisar akan digunakan di dalam loop bersarang. Ini akan membutuhkan penyortiran pada time .
Anda dapat membuat indeks spasial pada intervals (tersedia di MySQL menggunakan MyISAM penyimpanan) yang akan menyertakan start dan end dalam satu kolom geometri. Dengan cara ini, measures dapat memimpin dalam bergabung dan tidak diperlukan penyortiran.
Namun, indeks spasial lebih lambat, jadi ini hanya akan efisien jika Anda memiliki sedikit ukuran tetapi banyak interval.
Karena Anda memiliki sedikit interval tetapi banyak pengukuran, pastikan Anda memiliki indeks pada measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Pembaruan:
Berikut contoh skrip untuk diuji:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Kueri ini:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
menggunakan NESTED LOOPS dan kembali dalam 1.7 detik.
Kueri ini:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
menggunakan MERGE JOIN dan saya harus menghentikannya setelah 5 menit.
Pembaruan 2:
Anda kemungkinan besar perlu memaksa mesin untuk menggunakan urutan tabel yang benar dalam penggabungan menggunakan petunjuk seperti ini:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle pengoptimal tidak cukup pintar untuk melihat bahwa interval tidak berpotongan. Itu sebabnya kemungkinan besar akan menggunakan measures sebagai tabel terdepan (yang akan menjadi keputusan yang bijaksana jika intervalnya berpotongan).
Pembaruan 3
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Kueri ini membagi sumbu waktu ke dalam rentang dan menggunakan HASH JOIN untuk menggabungkan pengukuran dan stempel waktu pada nilai rentang, dengan pemfilteran halus nanti.
Lihat artikel ini di blog saya untuk penjelasan lebih rinci tentang cara kerjanya: