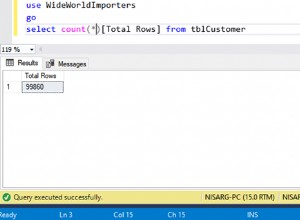
Poin utama dari pengumpulan database adalah menentukan bagaimana data diurutkan dan dibandingkan.
Sensitivitas kasus perbandingan string
SELECT "New York" = "NEW YORK";`
akan mengembalikan true untuk pemeriksaan case-sensitive; false untuk kasus yang peka huruf besar/kecil.
Pengumpulan mana yang dapat diceritakan oleh _ci dan _cs akhiran dalam nama collation ini. _bin collations melakukan perbandingan biner (string harus 100% identik).
Perbandingan karakter umlaut/aksen
susunan juga menentukan apakah karakter beraksen diperlakukan sebagai rekan dasar latin mereka dalam perbandingan string.
SELECT "Düsseldorf" = "Dusseldorf";
SELECT "Èclair" = "Eclair";
akan mengembalikan true dalam kasus sebelumnya; palsu pada yang terakhir. Anda perlu membaca deskripsi setiap koleksi untuk mengetahui yang mana.
Penyortiran string
Susunan memengaruhi cara string diurutkan.
Misalnya,
-
Umlauts
Ä Ö Überada di akhir alfabet dalam alfabet Finlandia/Swedialatin1_swedish_ci -
mereka diperlakukan sebagai
A O Udalam penyortiran DIN-1 Jerman (latin_german1_ci) -
dan sebagai
AE OE UEdalam penyortiran DIN-2 Jerman (latin_german2_ci). (penyortiran "buku telepon") -
Dalam
latin1_spanish_ci, "ñ" (n-tilde) adalah huruf terpisah antara "n" dan "o".
Aturan ini akan menghasilkan urutan pengurutan yang berbeda saat karakter non-latin digunakan.
Menggunakan susunan saat runtime
Anda harus memilih susunan untuk tabel dan kolom Anda, tetapi jika Anda tidak keberatan dengan kinerja yang dicapai, Anda dapat memaksa operasi basis data ke dalam susunan tertentu saat runtime menggunakan COLLATE kata kunci.
Ini akan mengurutkan table dengan name kolom menggunakan aturan penyortiran DIN-2 Jerman:
SELECT name
FROM table
ORDER BY name COLLATE latin1_german2_ci;
Menggunakan COLLATE saat runtime akan memiliki implikasi kinerja, karena setiap kolom harus dikonversi selama kueri. Jadi pikirkan dua kali sebelum menerapkan ini, lakukan set data besar.
Referensi MySQL:
- Set Karakter dan Kumpulan yang Didukung MySQL
- Contoh Efek Collation
- Masalah pengumpulan