Ringkasan
Oracle Data Mining (ODM) adalah komponen dari Oracle Advanced Analytics Database Option. ODM berisi rangkaian algoritme penambangan data tingkat lanjut yang tertanam dalam database yang memungkinkan Anda melakukan analitik tingkat lanjut pada data Anda.
Oracle Data Miner adalah perpanjangan dari Oracle SQL Developer, lingkungan pengembangan grafis untuk Oracle SQL. Oracle Data Miner menggunakan teknologi data mining yang tertanam di Oracle Database untuk membuat, mengeksekusi, dan mengelola alur kerja yang merangkum operasi data mining. Arsitektur ODM diilustrasikan pada gambar 1.
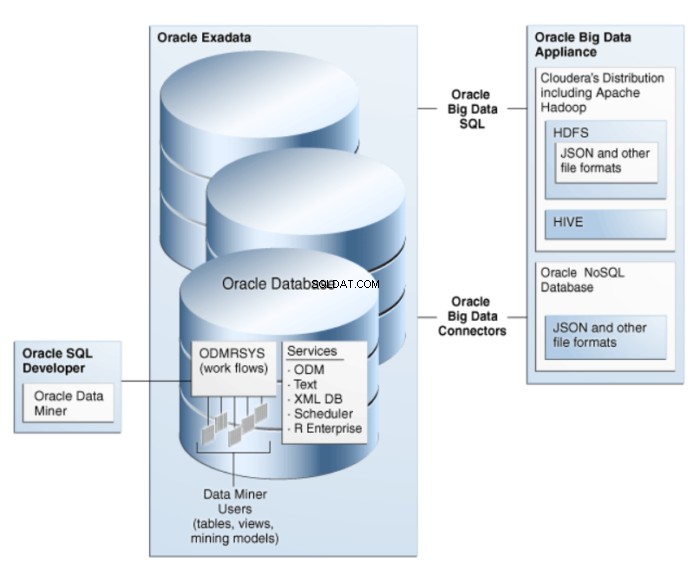
Gambar 1:Arsitektur Oracle Data Mining untuk Big Data
Algoritma diimplementasikan sebagai fungsi SQL dan memanfaatkan kekuatan Oracle Database. Fungsi data mining SQL dapat menambang data transaksional, agregasi, data tidak terstruktur yaitu tipe data CLOB (menggunakan Oracle Text) dan data spasial.
Setiap fungsi data mining menentukan kelas masalah yang dapat dimodelkan dan dipecahkan. Fungsi penambangan data umumnya terbagi dalam dua kategori:diawasi dan tidak diawasi.
Gagasan pembelajaran yang diawasi dan tidak diawasi berasal dari ilmu pembelajaran mesin, yang disebut sebagai sub-bidang kecerdasan buatan.
Pembelajaran yang diawasi juga dikenal sebagai pembelajaran terarah. Proses pembelajaran diarahkan oleh atribut atau target dependen yang diketahui sebelumnya. Penambangan data terarah mencoba menjelaskan perilaku target sebagai fungsi dari sekumpulan atribut atau prediktor independen.
Pembelajaran tanpa pengawasan tidak terarah. Tidak ada perbedaan antara atribut dependen dan independen. Tidak ada hasil yang diketahui sebelumnya untuk memandu algoritma dalam membangun model. Pembelajaran tanpa pengawasan dapat digunakan untuk tujuan deskriptif.
Algoritma yang Diawasi Penambangan Data Oracle
| Teknik | Penerapan | Algoritma (Deskripsi singkat) |
|---|---|---|
Klasifikasi | Teknik yang paling umum digunakan untuk memprediksi hasil spesifik misalnya identifikasi sel tumor kanker, analisis sentimen, klasifikasi obat, deteksi spam. | Regresi Logistik Model Linier Umum - teknik statistik klasik yang tersedia di dalam Oracle Database dalam implementasi parallized yang berkinerja tinggi, skalabel, (berlaku untuk semua algoritme ML OAA). Mendukung teks dan data transaksional (berlaku untuk hampir semua algoritme ML OAA) Naive Bayes - Cepat, sederhana, dapat diterapkan secara umum. Support Vector Machine - Algoritme pembelajaran mesin, mendukung teks dan data yang luas. Pohon Keputusan - Algoritma ML populer untuk interpretasi. Memberikan "aturan" yang dapat dibaca manusia. |
Regresi | Teknik untuk memprediksi hasil numerik berkelanjutan seperti analisis data Astronomi, Menghasilkan wawasan tentang perilaku konsumen, profitabilitas, dan faktor bisnis lainnya, Menghitung hubungan sebab akibat antara parameter dalam sistem biologis. | Generalized Linear Models Multiple Regression - teknik statistik klasik tetapi sekarang tersedia di dalam Oracle Database sebagai implementasi yang berkinerja tinggi, dapat diskalakan, dan diparalelkan. Mendukung regresi ridge, pembuatan fitur, dan pemilihan fitur. Mendukung teks dan data transaksional. Mendukung Mesin Vektor - Algoritme pembelajaran mesin, mendukung teks dan data lebar. |
Kepentingan Atribut | Memperingkat atribut menurut kekuatan hubungan dengan atribut target. Kasus penggunaan termasuk menemukan faktor yang paling terkait dengan pelanggan yang menanggapi tawaran, faktor yang paling terkait dengan pasien sehat. | Panjang Deskripsi Minimum - Mempertimbangkan setiap atribut sebagai model prediktif sederhana dari kelas target dan memberikan pengaruh relatif. |
Algoritma Tanpa Pengawasan Oracle Data Mining
| Teknik | Penerapan | Algoritma |
|---|---|---|
Pengelompokan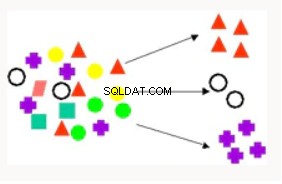 | Clustering digunakan untuk mempartisi record database ke dalam subset atau cluster di mana elemen dalam cluster berbagi satu set properti umum. Contohnya termasuk menemukan segmen pelanggan baru, dan rekomendasi Film. | K-Means - Mendukung penambangan teks, pengelompokan hierarkis, berbasis jarak. Pengelompokan Partisi Ortogonal - Pengelompokan hierarkis, berbasis kepadatan. Ekspektasi Maksimalisasi - Teknik pengelompokan yang berkinerja baik dalam masalah data mining campuran (padat dan jarang). |
Deteksi Anomali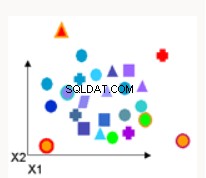 | Deteksi anomali mengidentifikasi titik data, peristiwa, dan/atau pengamatan yang menyimpang dari perilaku normal kumpulan data. Contoh umum termasuk penipuan bank, cacat struktural, masalah medis, atau kesalahan dalam teks | Mesin Vektor Dukungan Satu Kelas - melatih data yang tidak diberi tag dan mencoba menentukan apakah titik uji termasuk dalam distribusi data pelatihan. |
Seleksi dan Ekstraksi Fitur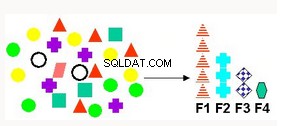 | Menghasilkan atribut baru sebagai kombinasi linier dari atribut yang ada. Berlaku untuk data teks, analisis semantik laten (LSA), kompresi data, dekomposisi dan proyeksi data, serta pengenalan pola. | Faktorisasi Matriks Non-negatif - Memetakan data asli ke dalam set atribut baru Analisis Komponen Utama (PCA) - membuat lebih sedikit atribut komposit baru yang mewakili semua atribut. Singular Vector Decomposition - metode ekstraksi fitur mapan yang memiliki cakupan aplikasi yang luas. |
Asosiasi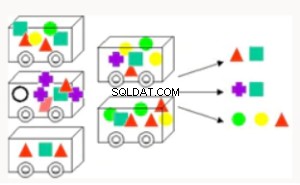 | Menemukan aturan yang terkait dengan item yang sering terjadi bersama, digunakan untuk analisis keranjang pasar, penjualan silang, analisis akar penyebab. Berguna untuk bundling produk dan analisis cacat. | Apriori - Hash pohon untuk mengumpulkan informasi dalam database |
Mengaktifkan Opsi Penambangan Data Oracle
Dari Rilis 12c 2 Oracle Advanced Analytics Opsi ini mencakup fungsionalitas Data Mining dan Oracle R.
Opsi Oracle Advanced Analytics diaktifkan secara default selama instalasi Oracle Database Enterprise Edition. Jika Anda ingin mengaktifkan atau menonaktifkan opsi basis data, Anda dapat menggunakan utilitas baris perintah chopt .
chopt [ enable | disable ] oaa
Untuk mengaktifkan opsi Oracle Advanced Analytics:
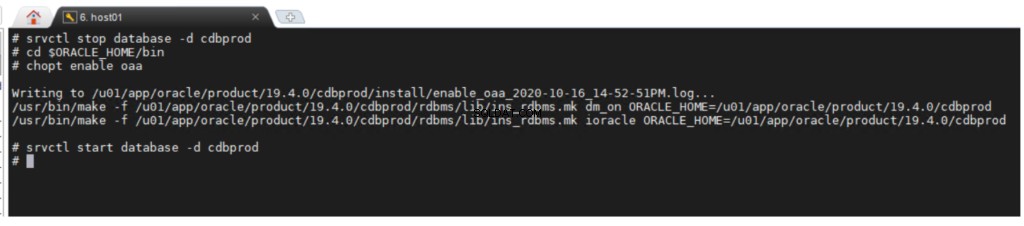
Membuat Tablespace dan Skema ODM
Semua pengguna memerlukan tablespace permanen dan tablespace sementara untuk melakukan pekerjaan mereka, akan sangat berguna untuk memiliki area terpisah di database Anda di mana Anda dapat membuat semua objek data mining Anda.
usr_dm_01 skema akan berisi semua pekerjaan Data Mining Anda.
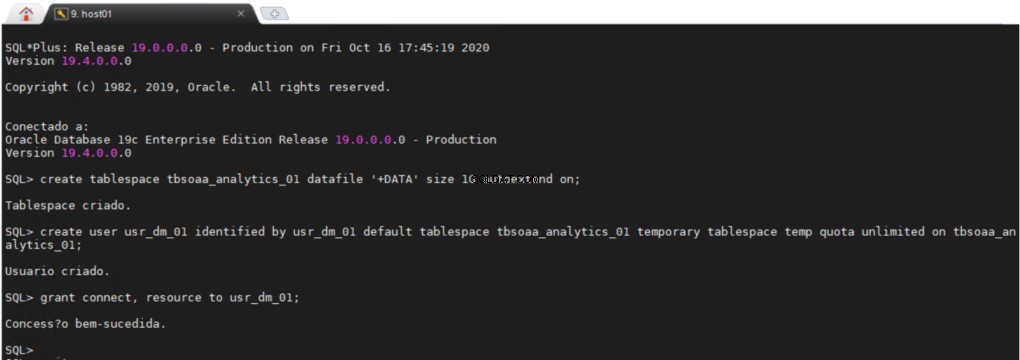
Membuat Repositori ODM
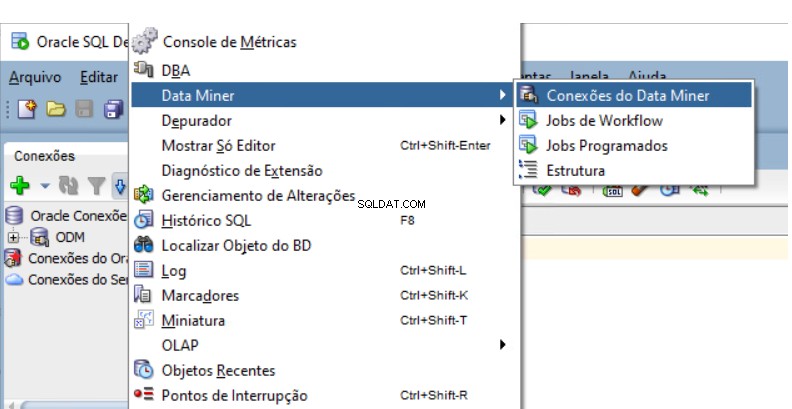
Anda perlu membuat Repositori Penambangan Data Oracle dalam database. Buka Navigator Penambang Data di Pengembang SQL.
Pilih Lihat -> Data Miner -> Koneksi Data Miner:
Tab baru terbuka di samping tab Koneksi yang ada:
Untuk menambahkan usr_dm_01 skema ke daftar ini, klik pada jendela plus hijau dan OK
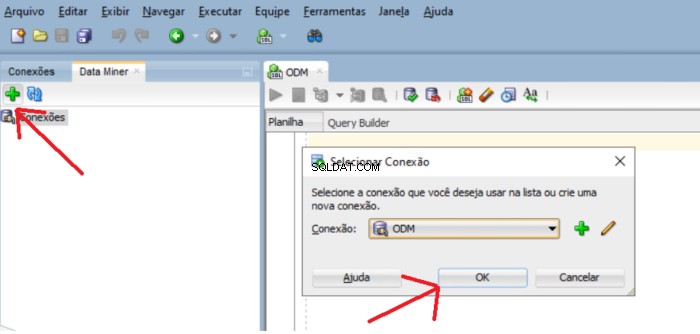
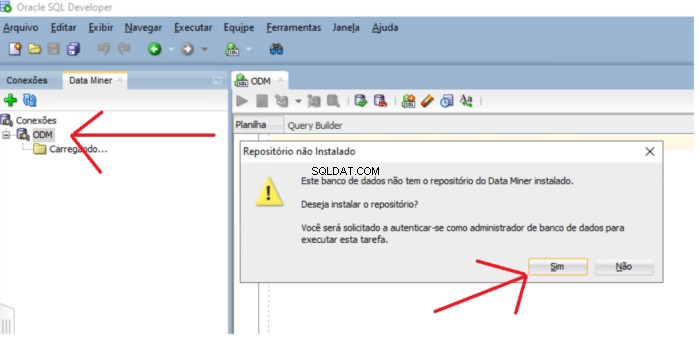
Jika repositori tidak ada tampilan pesan yang menanyakan apakah Anda ingin menginstal repositori. Klik Ya tombol untuk melanjutkan penginstalan.
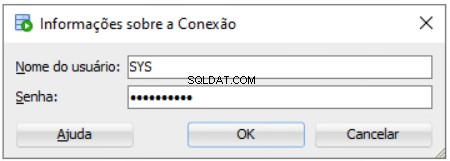
Anda harus memasukkan kata sandi SYS
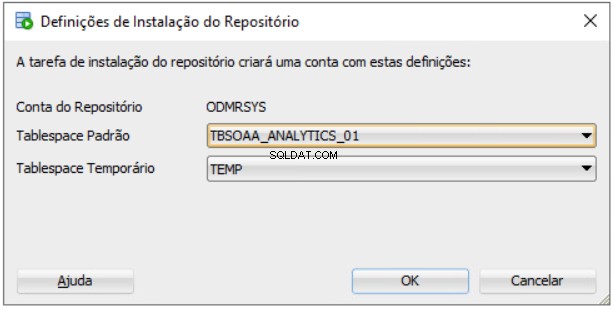
Pengaturan Instalasi Repositori
Instal jendela kemajuan Repositori Data Miner
Tugas Berhasil Selesai
Berkas Log
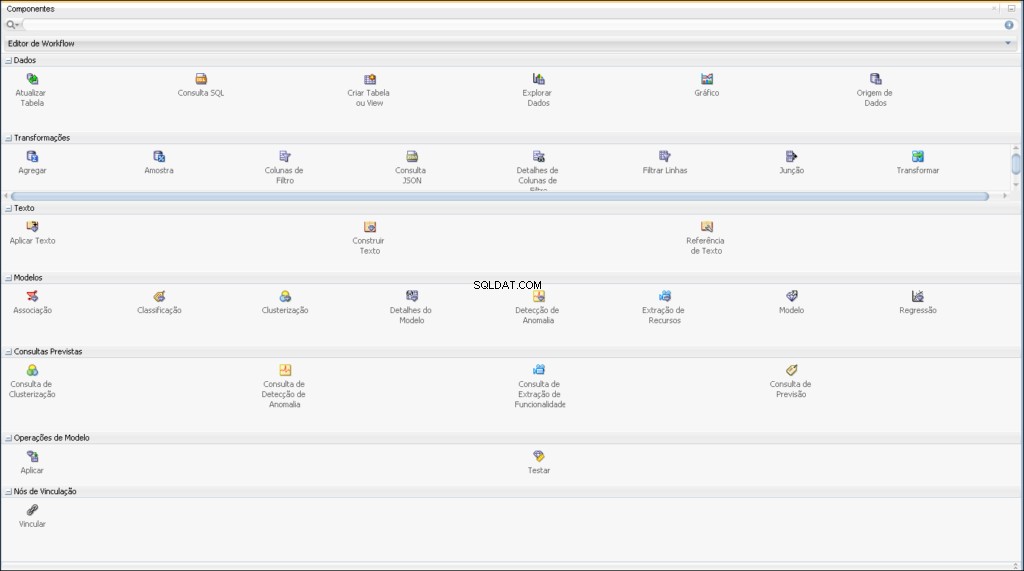
Komponen Penambangan Data Oracle
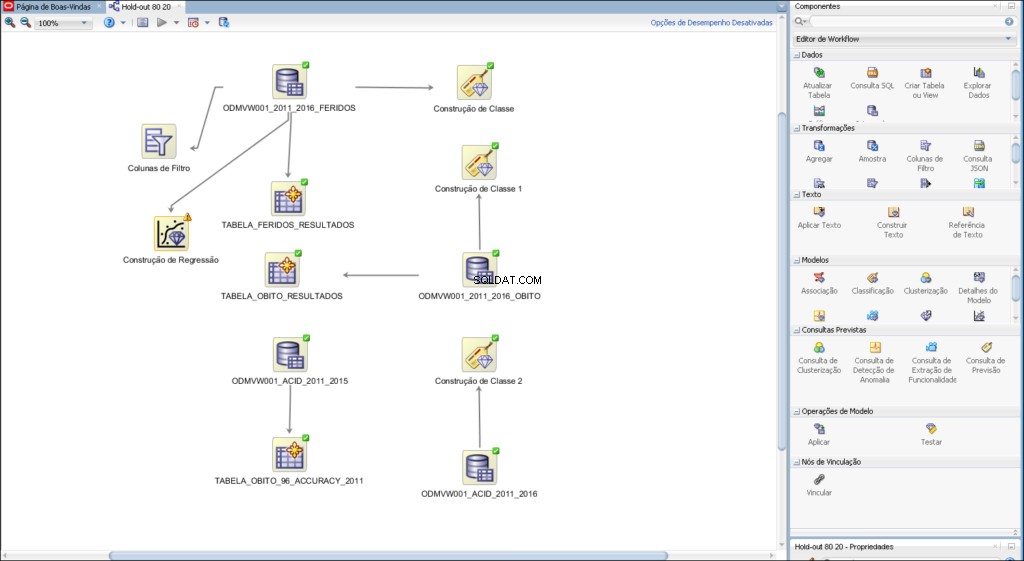
Alur kerja memungkinkan Anda membangun serangkaian simpul yang melakukan semua pemrosesan yang diperlukan pada data Anda.
Contoh alur kerja yang dikembangkan untuk analisis prediktif
Tampilan Kamus Data ODM
Anda dapat memperoleh informasi tentang model penambangan dari kamus data.
Tampilan kamus data Data Mining diringkas sebagai berikut:
Catatan:* dapat diganti dengan ALL_, USER_, DBA_ dan CDB_
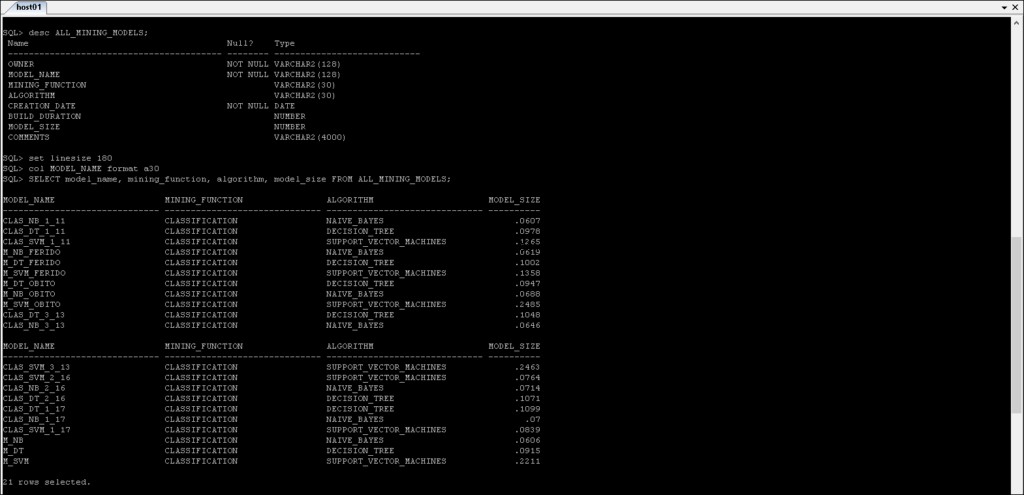
*_MINING_MODEL :Informasi tentang model penambangan yang telah dibuat.
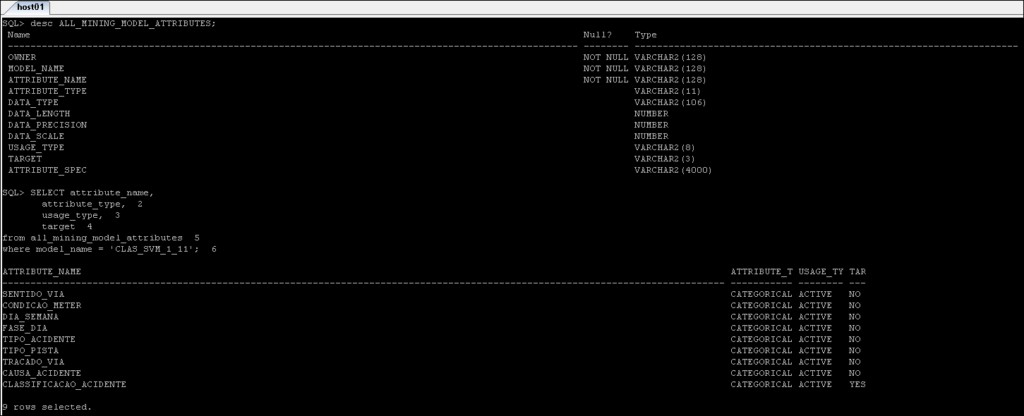
*_MINING_MODEL_ATTRIBUTES :Berisi detail atribut yang telah digunakan untuk membuat model Oracle Data Mining.
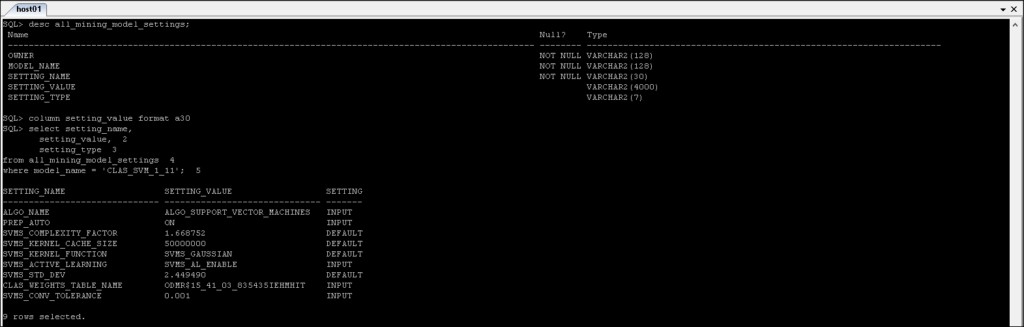
*_MINING_MODEL_SETTINGS :Mengembalikan informasi tentang pengaturan untuk model penambangan yang dapat Anda akses.
Referensi
Panduan Pengguna Penambangan Data Oracle. Tersedia di:https://docs.Oracle.com/en/database/Oracle/Oracle-database/19/dmprg/lot.html
Oracle Data Mining – Analisis prediktif dalam basis data yang dapat diskalakan. Tersedia di:https://www.Oracle.com/database/technologies/advanced-analytics/odm.html
Ikhtisar Sistem Penambang Data Oracle. Tersedia di:https://docs.Oracle.com/database/sql-developer-17.4/DMRIG/Oracle-data-miner-overview.htm#DMRIG124