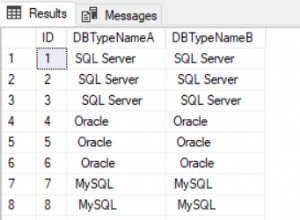
demo1:db<>biola , demo2:db<>biola
WITH combined AS (
SELECT
a.email as a_email,
b.email as b_email,
array_remove(ARRAY[a.id, b.id], NULL) as ids
FROM
a
FULL OUTER JOIN b ON (a.email = b.email)
), clustered AS (
SELECT DISTINCT
ids
FROM (
SELECT DISTINCT ON (unnest_ids)
*,
unnest(ids) as unnest_ids
FROM combined
ORDER BY unnest_ids, array_length(ids, 1) DESC
) s
)
SELECT DISTINCT
new_id,
unnest(array_cat) as email
FROM (
SELECT
array_cat(
array_agg(a_email) FILTER (WHERE a_email IS NOT NULL),
array_agg(b_email) FILTER (WHERE b_email IS NOT NULL)
),
row_number() OVER () as new_id
FROM combined co
JOIN clustered cl
ON co.ids <@ cl.ids
GROUP BY cl.ids
) s
Penjelasan langkah demi langkah:
Untuk penjelasan saya akan mengambil dataset ini. Ini sedikit lebih rumit daripada milik Anda. Itu bisa menggambarkan langkah saya dengan lebih baik. Beberapa masalah tidak terjadi di perangkat Anda yang lebih kecil. Pikirkan karakter sebagai variabel untuk alamat email.
Tabel A:
| id | email |
|----|-------|
| 1 | a |
| 1 | b |
| 2 | c |
| 5 | e |
Tabel B
| id | email |
|----|-------|
| 3 | a |
| 3 | d |
| 4 | e |
| 4 | f |
| 3 | b |
CTE combined :
GABUNG kedua tabel pada alamat email yang sama untuk mendapatkan titik kontak. ID dari Id yang sama akan digabungkan dalam satu larik:
| a_email | b_email | ids |
|-----------|-----------|-----|
| (null) | example@sqldat.com | 3 |
| example@sqldat.com | example@sqldat.com | 1,3 |
| example@sqldat.com | (null) | 1 |
| example@sqldat.com | (null) | 2 |
| (null) | example@sqldat.com | 4 |
CTE clustered (maaf atas nama-namanya...):
Tujuannya adalah untuk mendapatkan semua elemen tepat hanya dalam satu array. Dalam combined Anda bisa lihat, misalnya saat ini ada lebih banyak array dengan elemen 4 :{5,4} dan {4} .
Pertama-tama urutkan baris berdasarkan panjang ids their array karena DISTINCT nanti harus mengambil larik terpanjang (karena memegang titik sentuh {5,4} bukannya {4} ).
Kemudian unnest ids array untuk mendapatkan dasar untuk penyaringan. Ini berakhir dengan:
| a_email | b_email | ids | unnest_ids |
|---------|---------|-----|------------|
| b | b | 1,3 | 1 |
| a | a | 1,3 | 1 |
| c | (null) | 2 | 2 |
| b | b | 1,3 | 3 |
| a | a | 1,3 | 3 |
| (null) | d | 3 | 3 |
| e | e | 5,4 | 4 |
| (null) | f | 4 | 4 |
| e | e | 5,4 | 5 |
Setelah memfilter dengan DISTINCT ON
| a_email | b_email | ids | unnest_ids |
|---------|---------|-----|------------|
| b | b | 1,3 | 1 |
| c | (null) | 2 | 2 |
| b | b | 1,3 | 3 |
| e | e | 5,4 | 4 |
| e | e | 5,4 | 5 |
Kami hanya tertarik pada ids kolom dengan cluster id unik yang dihasilkan. Jadi kita membutuhkan semuanya hanya sekali. Ini adalah tugas DISTINCT terakhir . Jadi CTE clustered hasil dalam
| ids |
|-----|
| 2 |
| 1,3 |
| 5,4 |
Sekarang kita tahu id mana yang digabungkan dan harus membagikan datanya. Sekarang kita bergabung dengan ids yang berkerumun terhadap tabel asal. Karena kami telah melakukan ini dalam combined CTE kita dapat menggunakan kembali bagian ini (itulah alasan mengapa bagian ini di-outsource menjadi satu CTE:Kita tidak perlu lagi menggabungkan kedua tabel dalam langkah ini). Operator GABUNG <@ mengatakan:GABUNG jika array "titik sentuh" dari combined adalah subgrup dari kluster id dari clustered . Ini menghasilkan:
| a_email | b_email | ids | ids |
|---------|---------|-----|-----|
| c | (null) | 2 | 2 |
| a | a | 1,3 | 1,3 |
| b | b | 1,3 | 1,3 |
| (null) | d | 3 | 1,3 |
| e | e | 5,4 | 5,4 |
| (null) | f | 4 | 5,4 |
Sekarang kita dapat mengelompokkan alamat email dengan menggunakan clustered id (kolom paling kanan).
array_agg menggabungkan surat-surat dari satu kolom, array_cat menggabungkan larik email dari kedua kolom menjadi satu larik email besar.
Karena ada kolom di mana email adalah NULL kita dapat memfilter nilai-nilai ini sebelum mengelompokkan dengan FILTER (WHERE...) klausa.
Hasil sejauh ini:
| array_cat |
|-----------|
| c |
| a,b,a,b,d |
| e,e,f |
Sekarang kami mengelompokkan semua alamat email untuk satu id tunggal. Kita harus membuat id unik baru. Itulah fungsi jendela
row_number adalah untuk. Itu hanya menambahkan jumlah baris ke tabel:
| array_cat | new_id |
|-----------|--------|
| c | 1 |
| a,b,a,b,d | 2 |
| e,e,f | 3 |
Langkah terakhir adalah unnest array untuk mendapatkan baris per alamat email. Karena dalam array masih ada beberapa duplikat, kita dapat menghilangkannya pada langkah ini dengan DISTINCT juga:
| new_id | email |
|--------|-------|
| 1 | c |
| 2 | a |
| 2 | b |
| 2 | d |
| 3 | e |
| 3 | f |