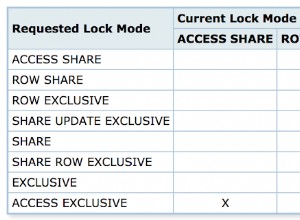
Jika Anda menjatuhkan SearchRank dan cukup filter menggunakan kueri itu akan menggunakan indeks GIN dan berkinerja jauh lebih cepat:
query = SearchQuery(termo,config='portuguese')
entries = Article.objects.filter(search_vector=query)
Anda dapat menambahkan .explain()
untuk mengakhiri untuk melihat kueri dan melihat apakah indeks digunakan:
print(entries.explain(analyze=True))
Anda akan melihat kueri menggunakan Bitmap Heap Scan dan Waktu Eksekusi akan jauh lebih cepat.
Bitmap Heap Scan on your_table
...
Planning Time: 0.176 ms Execution Time: 0.453 ms
Saat Anda membuat anotasi seperti di atas, Anda membuat anotasi setiap Article objek - jadi postgres memutuskan untuk melakukan Pemindaian Seq (atau Pemindaian Seq Paralel) yang diputuskannya lebih efisien. Info lebih lanjut di sini
Coba tambahkan .explain(verbose=True) atau .explain(analyze=True) ke metode SearchRank awal Anda untuk membandingkan.
query = SearchQuery(termo,config='portuguese')
search_rank = SearchRank(F('search_vector'), query)
entries = Article.objects.annotate(rank=search_rank).filter(search_vector=query).order_by('-rank')
print(entries.explain(analyze=True))
Saya sendiri menghadapi masalah ini, dengan tabel dengan 990k entri yang membutuhkan waktu ~ 10 detik. Jika Anda dapat memfilter kueri sebelum anotasi menggunakan bidang lain - ini akan mendorong perencana kueri kembali menggunakan Indeks.
Dari jawaban ini