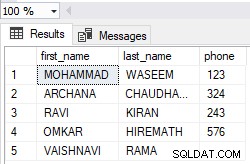
Masalahnya adalah Anda memanggil encode pada str objek.
Sebuah str adalah string byte, biasanya mewakili teks yang dikodekan dalam beberapa cara seperti UTF-8. Saat Anda memanggil encode pada itu, pertama-tama harus diterjemahkan kembali ke teks, sehingga teks dapat dikodekan ulang. Secara default, Python melakukannya dengan memanggil s.decode(sys.getgetdefaultencoding()) , dan getdefaultencoding() biasanya mengembalikan 'ascii' .
Jadi, Anda berbicara tentang teks yang disandikan UTF-8, mendekodekannya seolah-olah ASCII, lalu menyandikan ulang dalam UTF-8.
Solusi umumnya adalah memanggil decode . secara eksplisit dengan pengkodean yang tepat, alih-alih membiarkan Python menggunakan default, lalu encode hasilnya.
Tetapi ketika pengkodean yang tepat sudah menjadi yang Anda inginkan, solusi yang lebih mudah adalah dengan melewatkan .decode('utf-8').encode('utf-8') dan cukup gunakan str UTF-8 sebagai str UTF-8 yang sudah ada.
Atau, sebagai alternatif, jika pembungkus MySQL Anda memiliki fitur yang memungkinkan Anda menentukan penyandian dan mendapatkan kembali unicode nilai untuk CHAR /VARCHAR /TEXT kolom alih-alih str nilai (misalnya, di MySQLdb, Anda melewati use_unicode=True ke connect panggilan, atau charset='UTF-8' jika database Anda terlalu tua untuk mendeteksinya secara otomatis), lakukan saja. Maka Anda akan memiliki unicode objek, dan Anda dapat memanggil .encode('utf-8') pada mereka.
Secara umum, cara terbaik untuk mengatasi masalah Unicode adalah yang terakhir—decode semuanya sedini mungkin, lakukan semua pemrosesan di Unicode, dan kemudian encode selambat mungkin. Tapi bagaimanapun caranya, Anda harus konsisten. Jangan panggil str pada sesuatu yang mungkin berupa unicode; jangan gabungkan str literal ke unicode atau berikan satu ke replace metode; dll. Setiap kali Anda mencampur dan mencocokkan, Python akan secara implisit mengonversi untuk Anda, menggunakan penyandian default Anda, yang hampir tidak pernah seperti yang Anda inginkan.
Sebagai catatan tambahan, ini adalah salah satu dari banyak hal yang membantu perubahan Unicode Python 3.x. Pertama, str sekarang teks Unicode, bukan byte yang disandikan. Lebih penting lagi, jika Anda memiliki byte yang disandikan, misalnya, dalam bytes objek, memanggil encode akan memberi Anda AttributeError alih-alih mencoba mendekode secara diam-diam sehingga dapat menyandikan ulang. Dan, sama halnya, mencoba mencampur dan mencocokkan Unicode dan byte akan memberi Anda TypeError yang jelas , alih-alih konversi implisit yang berhasil dalam beberapa kasus dan memberikan pesan samar tentang enkode atau dekode yang tidak Anda minta di kasus lain.