Ini adalah angsuran kedua dari seri dua bagian pada repmgr 2ndQuadrant, alat ketersediaan tinggi sumber terbuka untuk PostgreSQL.
Pada bagian pertama, kami menyiapkan cluster PostgreSQL 12 tiga simpul bersama dengan simpul "saksi". Cluster terdiri dari node utama dan dua node siaga. Cluster dan node saksi di-host di Amazon Web Service Virtual Private Cloud (VPC). Server EC2 yang menghosting instans Postgres ditempatkan di subnet di zona ketersediaan yang berbeda (AZ), seperti yang ditunjukkan di bawah ini:
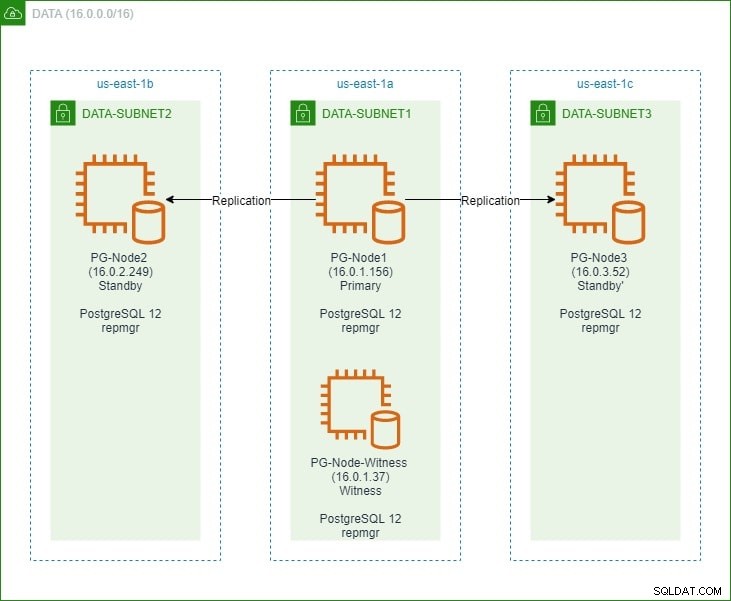
Kami akan membuat referensi ekstensif ke nama node dan alamat IP mereka, jadi di sini adalah tabel lagi dengan detail node:
| Nama Node | Alamat IP | Peran | Aplikasi Berjalan |
| PG-Node1 | 16.0.1.156 | Utama | PostgreSQL 12 dan repmgr |
| PG-Node2 | 16.0.2.249 | Siaga 1 | PostgreSQL 12 dan repmgr |
| PG-Node3 | 16.0.3.52 | Siaga 2 | PostgreSQL 12 dan repmgr |
| PG-Node-Witness | 16.0.1.37 | Saksi | PostgreSQL 12 dan repmgr |
Kami menginstal repmgr di node primer dan standby dan kemudian mendaftarkan node utama dengan repmgr. Kami kemudian mengkloning kedua node siaga dari primer dan memulainya. Kedua node siaga juga terdaftar dengan repmgr. Perintah "repmgr cluster show" menunjukkan kepada kita bahwa semuanya berjalan seperti yang diharapkan:

Masalah Saat Ini
Menyiapkan replikasi streaming dengan repmgr sangat sederhana. Apa yang perlu kita lakukan selanjutnya adalah memastikan cluster akan berfungsi bahkan ketika primary tidak tersedia. Inilah yang akan kami bahas dalam artikel ini.
Dalam replikasi PostgreSQL, primer dapat menjadi tidak tersedia karena beberapa alasan. Misalnya:
- Sistem operasi simpul utama dapat mogok, atau menjadi tidak responsif
- Node utama bisa kehilangan koneksi jaringannya
- Layanan PostgreSQL di node utama dapat mogok, berhenti, atau menjadi tidak tersedia secara tiba-tiba
- Layanan PostgreSQL di node utama dapat dihentikan secara sengaja atau tidak sengaja
Setiap kali primer menjadi tidak tersedia, standby tidak secara otomatis mempromosikan dirinya ke peran utama. Siaga masih terus melayani kueri hanya baca – meskipun data akan diperbarui hingga LSN terakhir yang diterima dari primer. Upaya apa pun untuk operasi tulis akan gagal.
Ada dua cara untuk mengurangi ini:
- Siaga secara manual ditingkatkan menjadi peran utama. Ini biasanya terjadi pada failover atau “switchover” yang direncanakan
- Siaga otomatis dipromosikan ke peran utama. Ini adalah kasus dengan alat non-asli yang terus memantau replikasi dan mengambil tindakan pemulihan ketika yang utama tidak tersedia. repmgr adalah salah satu alat tersebut.
Kami akan mempertimbangkan skenario kedua di sini. Situasi ini memiliki beberapa tantangan tambahan:
- Jika ada lebih dari satu siaga, bagaimana alat (atau siaga) memutuskan mana yang akan dipromosikan sebagai utama? Bagaimana kuorum dan proses promosi bekerja?
- Untuk beberapa standby, jika salah satunya dijadikan primer, bagaimana node lain mulai "mengikutinya" sebagai primer baru?
- Apa yang terjadi jika primer berfungsi, tetapi karena alasan tertentu terlepas dari jaringan untuk sementara? Jika salah satu siaga dipromosikan menjadi primer dan kemudian primer asli kembali online, bagaimana situasi "otak terbelah" dapat dihindari?
Remgr's Answer:Witness Node dan repmgr Daemon
Untuk menjawab pertanyaan ini, repmgr menggunakan sesuatu yang disebut simpul saksi . Ketika primer tidak tersedia – adalah tugas simpul saksi untuk membantu siaga mencapai kuorum jika salah satu dari mereka harus dipromosikan ke peran utama. Siaga mencapai kuorum ini dengan menentukan apakah node utama benar-benar offline atau hanya sementara tidak tersedia. Node saksi harus ditempatkan di pusat data/segmen jaringan/subnet yang sama dengan node utama, tetapi TIDAK PERNAH berjalan pada host fisik yang sama dengan node utama.
Ingat bahwa di bagian pertama seri ini, kami meluncurkan node saksi di zona ketersediaan dan subnet yang sama dengan node utama. Kami menamakannya PG-Node-Witness dan memasang instance PostgreSQL 12 di sana. Dalam posting ini, kami juga akan menginstal repmgr di sana, tetapi lebih lanjut tentang itu nanti.
Komponen kedua dari solusi adalah repmgr daemon (repmgrd) berjalan di semua node cluster dan node saksi. Sekali lagi, kami tidak memulai daemon ini di bagian pertama dari seri ini, tetapi kami akan melakukannya di sini. Daemon hadir sebagai bagian dari paket repmgr – ketika diaktifkan, ia berjalan sebagai layanan reguler dan terus memantau kesehatan cluster. Ini memulai failover ketika kuorum tercapai tentang yang utama sedang offline. Tidak hanya dapat secara otomatis mempromosikan siaga, itu juga dapat memulai kembali siaga lain dalam cluster multi-simpul untuk mengikuti primer baru .
Proses Kuorum
Ketika standby menyadari bahwa ia tidak dapat melihat yang utama, ia berkonsultasi dengan standby lainnya. Semua standby yang berjalan di cluster mencapai kuorum untuk memilih primary baru menggunakan serangkaian pemeriksaan:
- Setiap standby menginterogasi standby lain tentang waktu terakhirnya "melihat" yang utama. Jika LSN terakhir yang direplikasi standby atau waktu komunikasi terakhir dengan primer lebih baru daripada LSN terakhir yang direplikasi node saat ini atau waktu komunikasi terakhir, node tidak melakukan apa-apa dan menunggu komunikasi dengan primer dipulihkan
- Jika tidak ada standby yang dapat melihat primer, mereka memeriksa apakah node saksi tersedia. Jika node saksi tidak dapat dijangkau, standby menganggap ada pemadaman jaringan di sisi primer dan tidak melanjutkan untuk memilih primer baru
- Jika saksi dapat dihubungi, standbys menganggap primer mati dan melanjutkan untuk memilih primer
- Node yang dikonfigurasi sebagai primer "pilihan" kemudian akan dipromosikan. Setiap standby akan memiliki replikasi yang diinisialisasi ulang untuk mengikuti primer baru.
Mengonfigurasi Cluster untuk Kegagalan Otomatis
Kami sekarang akan mengonfigurasi cluster dan node saksi untuk failover otomatis.
Langkah 1:Instal dan Konfigurasi repmgr di Witness
Kami sudah melihat cara menginstal paket repmgr di artikel terakhir kami. Kami melakukan ini di simpul saksi juga:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Dan kemudian:
# yum install repmgr12 -y
Selanjutnya, kita tambahkan baris berikut di file postgresql.conf node saksi:
listen_addresses ='*'shared_preload_libraries ='repmgr'
Kami juga menambahkan baris berikut di file pg_hba.conf di node saksi. Perhatikan bagaimana kami menggunakan rentang CIDR dari cluster alih-alih menentukan alamat IP individual.
[Langkah-langkah yang dijelaskan di sini hanya untuk tujuan demonstrasi. Contoh kami di sini menggunakan IP yang dapat dijangkau secara eksternal untuk node. Oleh karena itu, menggunakan listen_address ='*' bersama dengan mekanisme keamanan "kepercayaan" pg_hba menimbulkan risiko keamanan, dan TIDAK boleh digunakan dalam skenario produksi. Dalam sistem produksi, semua node akan berada di dalam satu atau beberapa subnet pribadi, yang dapat dijangkau melalui IP pribadi dari jumphosts.]
Dengan postgresql.conf dan pg_hba.conf perubahan selesai, kami membuat pengguna repmgr dan database repmgr di saksi, dan mengubah jalur pencarian default pengguna repmgr:
[example@sqldat.comitness ~]$ createuser --superuser repmgr[example@sqldat.com ~]$createdb --owner=repmgr repmgr[example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path KE repmgr, publik;"
Terakhir, kita tambahkan baris berikut ke file repmgr.conf, yang terletak di bawah /etc/repmgr/12/
node_id =4nama_simpul ='PG-Node-Witness'koneksi ='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'data_directory ='/var/lib/pgsql/12/data'
Setelah parameter konfigurasi ditetapkan, kami memulai ulang layanan PostgreSQL di node saksi:
# systemctl restart postgresql-12.service
Untuk menguji konektivitas ke node saksi repmgr, kita dapat menjalankan perintah ini dari node utama:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
Selanjutnya, kita mendaftarkan node saksi dengan repmgr dengan menjalankan perintah “repmgr saksi register” sebagai pengguna postgres. Perhatikan bagaimana kita menggunakan alamat utama node, dan BUKAN node saksi dalam perintah di bawah ini:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daftar saksi -h 16.0.1.156
Ini karena perintah “repmgr saksi register” menambahkan metadata node saksi ke database repmgr node utama, dan jika perlu, menginisialisasi node saksi dengan menginstal ekstensi repmgr dan menyalin metadata repmgr ke node saksi.
Outputnya akan terlihat seperti ini:
INFO:menghubungkan ke node saksi "PG-Node-Witness" (ID:4)INFO:menghubungkan ke node utamaNOTICE:mencoba menginstal ekstensi "repmgr"PERHATIAN:ekstensi "repmgr" berhasil diinstalINFO:pendaftaran saksi selesai PERHATIKAN:node saksi "PG-Node-Witness" (ID:4) berhasil terdaftar
Terakhir, kami memeriksa status pengaturan keseluruhan dari node mana pun:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
Outputnya terlihat seperti ini:

Langkah 2:Memodifikasi File sudoers
Dengan cluster dan saksi berjalan, kami menambahkan baris berikut dalam file sudoers Di setiap node cluster dan node saksi:
Default:postgres !requirettypostgres ALL =NOPASSWD:/usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service , /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Langkah 3:Mengonfigurasi Parameter repmgrd
Kami telah menambahkan empat parameter dalam file repmgr.conf di setiap node. Parameter yang ditambahkan adalah parameter dasar yang diperlukan untuk operasi repmgr. Untuk mengaktifkan daemon repmgr dan failover otomatis, sejumlah parameter lain perlu diaktifkan/ditambahkan. Dalam subbagian berikut, kami akan menjelaskan setiap parameter dan nilai yang akan ditetapkan untuk setiap node.
kegagalan
Parameter failover adalah salah satu parameter wajib untuk daemon repmgr. Parameter ini memberitahu daemon jika harus memulai failover otomatis ketika situasi failover terdeteksi. Itu dapat memiliki salah satu dari dua nilai:"manual" atau "otomatis". Kami akan mengatur ini menjadi otomatis di setiap node:
kegagalan ='otomatis'
promosikan_perintah
Ini adalah parameter wajib lainnya untuk daemon repmgr. Parameter ini memberi tahu daemon repmgr perintah apa yang harus dijalankan untuk mempromosikan standby. Nilai parameter ini biasanya berupa perintah "repmgr standby promote", atau jalur ke skrip shell yang memanggil perintah tersebut. Untuk kasus penggunaan kami, kami menetapkan ini sebagai berikut di setiap node:
promote_command ='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
ikuti_perintah
Ini adalah parameter wajib ketiga untuk daemon repmgr. Parameter ini memberitahu node siaga untuk mengikuti primer baru. Daemon repmgr menggantikan %n placeholder dengan ID node dari primer baru saat run time:
ikuti_perintah ='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
prioritas
Parameter prioritas menambah bobot pada kelayakan node untuk menjadi yang utama. Menyetel parameter ini ke nilai yang lebih tinggi memberikan kelayakan yang lebih besar pada node untuk menjadi node utama. Selain itu, menyetel nilai ini ke nol untuk sebuah simpul akan memastikan bahwa simpul tersebut tidak pernah dipromosikan sebagai yang utama.
Dalam kasus penggunaan kami, kami memiliki dua standby:PG-Node2 dan PG-Node3. Kami ingin mempromosikan PG-Node2 sebagai primer baru ketika PG-Node1 offline, dan PG-Node3 mengikuti PG-Node2 sebagai primer barunya. Kami menetapkan parameter ke nilai berikut di dua node siaga:
| Nama Node | Pengaturan Parameter |
| PG-Node2 | prioritas =60 |
| PG-Node3 | prioritas =40 |
monitor_interval_secs
Parameter ini memberi tahu daemon repmgr seberapa sering (dalam hitungan detik) ia harus memeriksa ketersediaan node upstream. Dalam kasus kami, hanya ada satu simpul hulu:simpul utama. Nilai defaultnya adalah 2 detik, tetapi kami akan mengaturnya secara eksplisit di setiap node:
monitor_interval_secs =2
connection_check_type
Parameter connection_check_type menentukan protokol repmgr daemon yang akan digunakan untuk menjangkau node upstream. Parameter ini dapat mengambil tiga nilai:
- ping :repmgr menggunakan metode PQPing()
- koneksi :repmgr mencoba membuat koneksi baru ke node upstream
- kueri :repmgr mencoba menjalankan kueri SQL pada node upstream menggunakan koneksi yang ada
Sekali lagi, kami akan mengatur parameter ini ke nilai default ping di setiap node:
connection_check_type ='ping'
reconnect_attempts dan reconnect_interval
Ketika primer menjadi tidak tersedia, daemon repmgr di node siaga akan mencoba menyambung kembali ke primer untuk waktu reconnect_attempts. Nilai default untuk parameter ini adalah 6. Di antara setiap upaya penyambungan ulang, parameter ini akan menunggu selang waktu penyambungan ulang, yang memiliki nilai bawaan 10. Untuk tujuan demonstrasi, kami akan menggunakan interval pendek dan upaya penyambungan ulang yang lebih sedikit. Kami menetapkan parameter ini di setiap node:
reconnect_attempts =4interval_koneksi ulang =8
konsensus_visibilitas_primer
Ketika primer menjadi tidak tersedia di cluster multi-simpul, siaga dapat berkonsultasi satu sama lain untuk membangun kuorum tentang failover. Hal ini dilakukan dengan menanyakan setiap standby tentang waktu terakhir mereka melihat primer. Jika komunikasi terakhir node sangat baru dan lebih lambat dari waktu node lokal melihat primer, node lokal menganggap primer masih tersedia, dan tidak melanjutkan dengan keputusan failover.
Untuk mengaktifkan model konsensus ini, parameter primary_visibility_consensus perlu disetel ke “true” di setiap node – termasuk saksi:
konsensus_visibilitas_primer =benar
standby_disconnect_on_failover
Ketika parameter standby_disconnect_on_failover diatur ke "true" di node siaga, daemon repmgr akan memastikan penerima WAL-nya terputus dari primer dan tidak menerima segmen WAL apa pun. Itu juga akan menunggu penerima WAL dari node siaga lainnya berhenti sebelum membuat keputusan failover. Parameter ini harus disetel ke nilai yang sama di setiap node. Kami menyetel ini ke "benar".
standby_disconnect_on_failover =benar
Menyetel parameter ini ke true berarti setiap node siaga telah berhenti menerima data dari primer saat failover terjadi. Proses akan memiliki penundaan 5 detik ditambah waktu yang dibutuhkan penerima WAL untuk berhenti sebelum keputusan failover dibuat. Secara default, daemon repmgr akan menunggu selama 30 detik untuk mengonfirmasi bahwa semua node saudara telah berhenti menerima segmen WAL sebelum kegagalan terjadi.
repmgrd_service_start_command dan repmgrd_service_stop_command
Dua parameter ini menentukan cara memulai dan menghentikan daemon repmgr menggunakan perintah “repmgr daemon start” dan “repmgr daemon stop”.
Pada dasarnya, kedua perintah ini membungkus perintah sistem operasi untuk memulai/menghentikan layanan. Dua nilai parameter memetakan perintah ini ke versi khusus OS mereka. Kami menetapkan parameter ini ke nilai berikut di setiap node:
repmgrd_service_start_command ='sudo /usr/bin/systemctl start repmgr12.service'repmgrd_service_stop_command ='sudo /usr/bin/systemctl stop repmgr12.service'
Perintah Start/Stop/Restart Layanan PostgreSQL
Sebagai bagian dari operasinya, daemon repmgr sering kali harus menghentikan, memulai, atau memulai ulang layanan PostgreSQL. Untuk memastikan ini terjadi dengan lancar, yang terbaik adalah menentukan perintah sistem operasi yang sesuai sebagai nilai parameter dalam file repmgr.conf. Kami akan menetapkan empat parameter di setiap node untuk tujuan ini:
service_start_command ='sudo /usr/bin/systemctl start postgresql-12.service'service_stop_command ='sudo /usr/bin/systemctl stop postgresql-12.service'service_restart_command ='sudo /usr/bin/systemctl restart postgresql-12.service'service_reload_command ='sudo /usr/bin/systemctl reload postgresql-12.service'
monitoring_history
Menyetel parameter monitoring_history ke "yes" akan memastikan repmgr menyimpan data pemantauan klasternya. Kami menyetel ini ke "ya" di setiap simpul:
monitoring_history =ya
log_status_interval
Kami mengatur parameter di setiap node untuk menentukan seberapa sering daemon repmgr akan mencatat pesan status. Dalam hal ini, kami menyetelnya ke setiap 60 detik:
log_status_interval =60
Langkah 4:Memulai repmgr Daemon
Dengan parameter yang sekarang ditetapkan di cluster dan node saksi, kami menjalankan perintah kering untuk memulai daemon repmgr. Kami menguji ini di node utama terlebih dahulu, dan kemudian dua node siaga, diikuti oleh node saksi. Perintah harus dijalankan sebagai pengguna postgres:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
Outputnya akan terlihat seperti ini:
INFO:prasyarat untuk memulai repmrd terpenuhi DETAIL:perintah berikut akan dijalankan: sudo /usr/bin/systemctl start repmgr12.service
Selanjutnya, kita memulai daemon di keempat node:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
Output di setiap node harus menunjukkan daemon telah dimulai:
PERHATIKAN:mengeksekusi:"sudo /usr/bin/systemctl start repmgr12.service"PERHATIKAN:repmgrd berhasil dimulai
Kami juga dapat memeriksa acara startup layanan dari node utama atau siaga:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
Outputnya akan menunjukkan daemon memantau koneksi:
ID Node | Nama | Acara | Oke | Stempel waktu | Detail--------+-------+---------------+----+- --------------------+---------------------------- -------------------------------------4 | PG-Node-Saksi | repmrd_start | t | 05-02-2020 11:37:31 | menyaksikan koneksi pemantauan ke node utama "PG-Node1" (ID:1) 3 | PG-Node3 | repmrd_start | t | 05-02-2020 11:37:24 | memantau koneksi ke node upstream "PG-Node1" (ID:1) 2 | PG-Node2 | repmrd_start | t | 05-02-2020 11:37:19 | memantau koneksi ke node upstream "PG-Node1" (ID:1) 1 | PG-Node1 | repmrd_start | t | 05-02-2020 11:37:14 | memantau cluster utama "PG-Node1" (ID:1)
Terakhir, kita dapat memeriksa output daemon dari syslog di salah satu standby:
# cat /var/log/messages | grep repmgr | kurang
Berikut adalah output dari PG-Node3:
5 Februari 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [PEMBERITAHUAN] menggunakan file konfigurasi yang disediakan "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [PEMBERITAHUAN] repmgrd (repmgrd 5.0.0) dimulai 5 Feb 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] menghubungkan ke database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]:repmgr12.service:Tidak dapat membuka file PID /run/repmgr/repmgrd-12.pid (belum?) setelah mulai:Tidak ada file atau direktori seperti ituFeb 5 11:37 :24 PG-Node3 repmgrd[2014]:INFO: set_repmgrd_pid():file pid yang disediakan adalah /run/repmgr/repmgrd-12.pid 5 Feb 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [PEMBERITAHUAN] memulai pemantauan node "PG-Node3" (ID:3) 5 Feb 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] "connection_check_type" disetel ke "ping" 5 Feb 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] memantau koneksi ke node upstream "PG-Node1" (ID:1) 5 Feb 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID:3) memantau node upstream "PG- Node1" (ID:1) dalam keadaan normal 5 Feb 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [DETAIL] pembaruan statistik pemantauan terakhir adalah 2 detik yang lalu 5 Feb 11:39:26 PG-Node3 repmgrd[2014]:[2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID:3) memantau node upstream "PG- Node1" (ID:1) dalam keadaan normal … …
Memeriksa syslog di node utama menunjukkan jenis output yang berbeda:
5 Februari 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [PEMBERITAHUAN] menggunakan file konfigurasi yang disediakan "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [PEMBERITAHUAN] repmgrd (repmgrd 5.0.0) dimulai 5 Feb 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] menghubungkan ke database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [PEMBERITAHUAN] memulai pemantauan node "PG-Node1" (ID:1) 5 Feb 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] "connection_check_type" disetel ke "ping" 5 Feb 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [PEMBERITAHUAN] cluster pemantauan utama "PG-Node1" (ID:1) 5 Feb 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] node turunan [INFO] "PG-Node-Witness" (ID:4) belum terpasangFeb 5 11 :37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] node anak "PG-Node3" (ID:3) terpasang 5 Feb 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] node turunan "PG-Node2" (ID:2) terpasang 5 Feb 11:37:32 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:32] [PEMBERITAHUAN] saksi baru "PG-Node-Witness" (ID:4) telah terhubung 5 Feb 11:38:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:38:14] [INFO] memantau node utama "PG-Node1" (ID:1) dalam keadaan normal 5 Feb 11:39:15 PG-Node1 repmgrd[2017]:[2020-02-05 11:39:15] [INFO] memantau node utama "PG-Node1" (ID:1) dalam keadaan normal … …
Langkah 5:Mensimulasikan Pratama yang Gagal
Sekarang kita akan mensimulasikan primary yang gagal dengan menghentikan primary node (PG-Node1). Dari prompt shell dari node, kami menjalankan perintah berikut:
# systemctl stop postgresql-12.service
Proses Failover
Setelah proses berhenti, kami menunggu sekitar satu atau dua menit, lalu memeriksa file syslog PG-Node2. Pesan berikut ditampilkan. Untuk kejelasan dan kesederhanaan, kami memiliki grup pesan berkode warna dan menambahkan spasi putih di antara baris:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [PERINGATAN] tidak dapat melakukan ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"5 Februari 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [ DETAIL] PQping() mengembalikan "PQPING_NO_RESPONSE" 5 Feb 11:53:36 PG-Node2 repmgrd[2165]:[05-02-2020 11:53:36] [INFO] tidur 8 detik hingga upaya penyambungan ulang berikutnya 5 Feb 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [INFO] memeriksa status node 1, 2 dari 4 upaya 5 Feb 11:53:44 PG-Node2 repmgrd[2165]:[05-02-2020 11:53:44] [PERINGATAN] tidak dapat melakukan ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"5 Februari 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [ DETAIL] PQping() mengembalikan "PQPING_NO_RESPONSE" 5 Feb 11:53:44 PG-Node2 repmgrd[2165]:[05-02-2020 11:53:44] [INFO] tidur 8 detik hingga upaya penyambungan ulang berikutnya 5 Feb 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [INFO] memeriksa status node 1, 3 dari 4 upaya 5 Feb 11:53:52 PG-Node2 repmgrd[2165]:[05-02-2020 11:53:52] [PERINGATAN] tidak dapat melakukan ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"5 Februari 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [ DETAIL] PQping() mengembalikan "PQPING_NO_RESPONSE" 5 Feb 11:53:52 PG-Node2 repmgrd[2165]:[05-02-2020 11:53:52] [INFO] tidur 8 detik hingga upaya penyambungan ulang berikutnya 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] memeriksa status node 1, 4 dari 4 percobaan 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [PERINGATAN] tidak dapat melakukan ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"5 Februari 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [ DETAIL] PQping() mengembalikan "PQPING_NO_RESPONSE" 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [PERINGATAN] tidak dapat menyambung kembali ke node 1 setelah 4 upaya 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [PEMBERITAHUAN] menyetel "wal_retrieve_retry_interval" ke 86405000 milidetik 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[05-02-2020 11:54:00] [PERINGATAN] penerima wal tidak berjalan 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [PEMBERITAHUAN] Penerima WAL terputus di semua node saudara 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] Penerima WAL terputus pada semua 2 node saudara 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] penerimaan terakhir node lokal lsn:0/2214A000 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] memeriksa status node saudara "PG-Node3" (ID:3) 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID:3) melaporkan upstream-nya adalah node 1 , terakhir terlihat 26 detik yang lalu 5 Feb 11:54:00 PG-Node2 repmgr[2165]:[2020-02-05 11:54:00] [INFO] node 3 terakhir melihat node utama 26 detik yang lalu 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] terakhir menerima LSN untuk node saudara "PG-Node3" (ID:3) adalah :0/2214A000 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID:3) memiliki LSN yang sama dengan kandidat saat ini "PG-Node2" (ID:2) 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID:3) memiliki prioritas lebih rendah (40) dari kandidat saat ini "PG-Node2" (ID:2) (60) 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] memeriksa status node saudara "PG-Node-Witness" (ID:4) 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID:4) melaporkan upstream-nya simpul 1, terakhir terlihat 26 detik yang lalu 5 Feb 11:54:00 PG-Node2 repmgr[2165]:[2020-02-05 11:54:00] [INFO] node 4 terakhir melihat node utama 26 detik yang lalu 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[05-02-2020 11:54:00] [INFO] node yang terlihat:3; jumlah node:3; tidak ada node yang melihat yang utama dalam 4 detik terakhir ……5 Februari 11:54:00 PG-Node2 repmgrd[2165]:[05-02-2020 11:54:00] Kandidat promosi [PEMBERITAHUAN] adalah "PG-Node2" (ID:2) 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[05-02-2020 11:54:00] [PEMBERITAHUAN] menyetel "wal_retrieve_retry_interval" ke 5000 md 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [PEMBERITAHUAN] node ini adalah pemenangnya, sekarang akan mempromosikan dirinya sendiri dan menginformasikan node lain …… 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [PEMBERITAHUAN] mempromosikan standby ke primer 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [DETAIL] mempromosikan server "PG-Node2" (ID:2) menggunakan pg_promote() 5 Feb 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [PEMBERITAHUAN] menunggu hingga 60 detik (parameter "promote_check_timeout") untuk menyelesaikan promosi 5 Feb 11:54:01 PG-Node2 repmgrd[2165]:[05-02-2020 11:54:01] [PEMBERITAHUAN] PROMOSI SIAGA berhasil 5 Feb 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID:2) berhasil dipromosikan ke primer 5 Feb 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [INFO] 2 pengikut untuk diberi tahu 5 Feb 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [PEMBERITAHUAN] memberi tahu node "PG-Node3" (ID:3) untuk mengikuti node 2 5 Feb 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [PEMBERITAHUAN] memberi tahu node "PG-Node-Witness" (ID:4) untuk mengikuti node 2 5 Feb 11:54:01 PG-Node2 repmgrd[2165]:[05-02-2020 11:54:01] [INFO] beralih ke mode pemantauan utama 5 Feb 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [PEMBERITAHUAN] cluster pemantauan utama "PG-Node2" (ID:2) 5 Feb 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [PEMBERITAHUAN] saksi baru "PG-Node-Witness" (ID:4) telah terhubung 5 Feb 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [PEMBERITAHUAN] standby baru "PG-Node3" (ID:3) telah terhubung 5 Feb 11:54:07 PG-Node2 repmgrd[2165]:[05-02-2020 11:54:07] [PEMBERITAHUAN] standby baru "PG-Node3" (ID:3) telah terhubung5 Feb 11:55:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:55:02] [INFO] memantau node utama "PG-Node2" (ID:2) dalam keadaan normal 5 Feb 11:56:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:56:02] [INFO] memantau node utama "PG-Node2" (ID:2) dalam keadaan normal … …
Ada banyak informasi di sini, tetapi mari kita uraikan bagaimana peristiwa itu terjadi. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
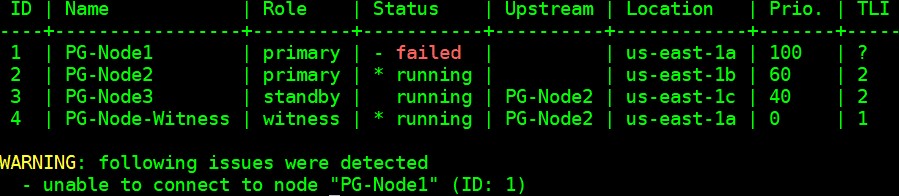
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID:2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID:3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID:4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID:2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID:2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID:2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID:4) has connected
Kesimpulan
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1