PostgreSQL adalah proyek yang luar biasa dan berkembang dengan kecepatan yang luar biasa. Kami akan fokus pada evolusi kemampuan toleransi kesalahan di PostgreSQL di seluruh versinya dengan serangkaian posting blog. Ini adalah posting kedua dari seri ini dan kita akan berbicara tentang replikasi dan pentingnya toleransi kesalahan dan ketergantungan PostgreSQL.
Jika Anda ingin menyaksikan kemajuan evolusi dari awal, silakan periksa posting blog pertama dari seri:Evolusi Toleransi Kesalahan di PostgreSQL
Replikasi PostgreSQL
Replikasi basis data adalah istilah yang kami gunakan untuk menggambarkan teknologi yang digunakan untuk memelihara salinan dari sekumpulan data di jarak jauh sistem. Menyimpan salinan yang andal dari sistem yang berjalan adalah salah satu masalah terbesar dari redundansi dan kita semua menyukai salinan data kita yang dapat dipelihara, mudah digunakan, dan stabil.
Mari kita lihat arsitektur dasarnya. Biasanya, server database individual disebut sebagai node . Seluruh kelompok server database yang terlibat dalam replikasi dikenal sebagai cluster . Server basis data yang memungkinkan pengguna membuat perubahan dikenal sebagai master atau utama , atau dapat digambarkan sebagai sumber perubahan. Server basis data yang hanya memungkinkan akses hanya-baca dikenal sebagai Siaga Panas . (Istilah Siaga Panas dijelaskan secara rinci di bawah judul Mode Siaga. )
Aspek kunci dari replikasi adalah bahwa perubahan data ditangkap pada master, dan kemudian ditransfer ke node lain. Dalam beberapa kasus, sebuah node dapat mengirim perubahan data ke node lain, yang merupakan proses yang dikenal sebagai cascading atau relai . Jadi, master adalah node pengirim tetapi tidak semua node pengirim harus menjadi master. Replikasi sering dikategorikan berdasarkan apakah lebih dari satu node master diperbolehkan, dalam hal ini akan dikenal sebagai replikasi multimaster .
Mari kita lihat bagaimana PostgreSQL menangani replikasi dari waktu ke waktu dan apa yang paling canggih untuk toleransi kesalahan dengan persyaratan replikasi.
Riwayat Replikasi PostgreSQL
Secara historis (sekitar tahun 2000-2005), Postgres hanya terkonsentrasi pada toleransi/pemulihan kesalahan node tunggal yang sebagian besar dicapai oleh WAL, log transaksi. Toleransi kesalahan ditangani sebagian oleh MVCC (sistem konkurensi multi-versi), tetapi sebagian besar merupakan pengoptimalan.
Write-ahead logging dulu dan masih merupakan metode toleransi kesalahan terbesar di PostgreSQL. Pada dasarnya, hanya memiliki file WAL tempat Anda menulis semuanya dan dapat memulihkan dalam hal kegagalan dengan memutar ulang. Ini sudah cukup untuk arsitektur node tunggal dan replikasi dianggap sebagai solusi terbaik untuk mencapai toleransi kesalahan dengan banyak node.
Komunitas Postgres dulu percaya bahwa replikasi adalah sesuatu yang Postgres tidak boleh sediakan dan harus ditangani oleh alat eksternal, inilah sebabnya alat seperti Slony dan Londiste ada. (Kami akan membahas solusi replikasi berbasis pemicu di entri blog seri berikutnya.)
Akhirnya menjadi jelas bahwa, satu toleransi server tidak cukup dan lebih banyak orang menuntut toleransi kesalahan yang tepat dari perangkat keras dan cara peralihan yang tepat, sesuatu yang ada di dalam Postgres. Ini adalah saat replikasi fisik (lalu streaming fisik) menjadi hidup.
Kita akan membahas semua metode replikasi nanti di postingan ini, tetapi mari kita lihat kronologis peristiwa sejarah replikasi PostgreSQL berdasarkan rilis utama:
- PostgreSQL 7.x (~2000)
- Replikasi tidak boleh menjadi bagian inti Postgres
- Londiste – Slony (replikasi logis berbasis pemicu)
- PostgreSQL 8.0 (2005)
- Pemulihan Point-In-Time (WAL)
- PostgreSQL 9.0 (2010)
- Replikasi Streaming (fisik)
- PostgreSQL 9.4 (2014)
- Decoding Logis (ekstraksi changeset)
Replikasi Fisik
PostgreSQL memecahkan kebutuhan replikasi inti dengan apa yang dilakukan sebagian besar database relasional; mengambil WAL dan memungkinkan untuk mengirimkannya melalui jaringan. Kemudian file WAL ini diterapkan ke dalam instance Postgres terpisah yang menjalankan read-only.
Instans siaga hanya-baca hanya menerapkan perubahan (oleh WAL) dan satu-satunya operasi tulis datang lagi dari log WAL yang sama. Ini pada dasarnya adalah cara replikasi streaming mekanisme bekerja. Pada awalnya, replikasi awalnya mengirimkan semua file –pengiriman log- , tetapi kemudian berkembang menjadi streaming.
Dalam pengiriman log, kami mengirim seluruh file melalui archive_command . Logikanya cukup sederhana:Anda cukup kirim arsip dan log ke suatu tempat – seperti seluruh file WAL 16 MB – lalu Anda mendaftar ke suatu tempat, lalu Anda mengambil yang berikutnya dan terapkan yang itu dan berjalan seperti itu. Kemudian menjadi streaming melalui jaringan dengan menggunakan protokol libpq di PostgreSQL versi 9.0.
Replikasi yang ada lebih dikenal sebagai Replikasi Streaming Fisik, karena kami mengalirkan serangkaian perubahan fisik dari satu node ke node lainnya. Artinya, saat kita menyisipkan baris ke dalam tabel yang kami hasilkan ubah catatan untuk sisipan ditambah semua entri indeks .
Saat kita VACUUM tabel kami juga menghasilkan catatan perubahan.
Selain itu, Replikasi Streaming Fisik mencatat semua perubahan pada tingkat byte/blok , membuatnya sangat sulit untuk melakukan apa pun selain hanya memutar ulang semuanya
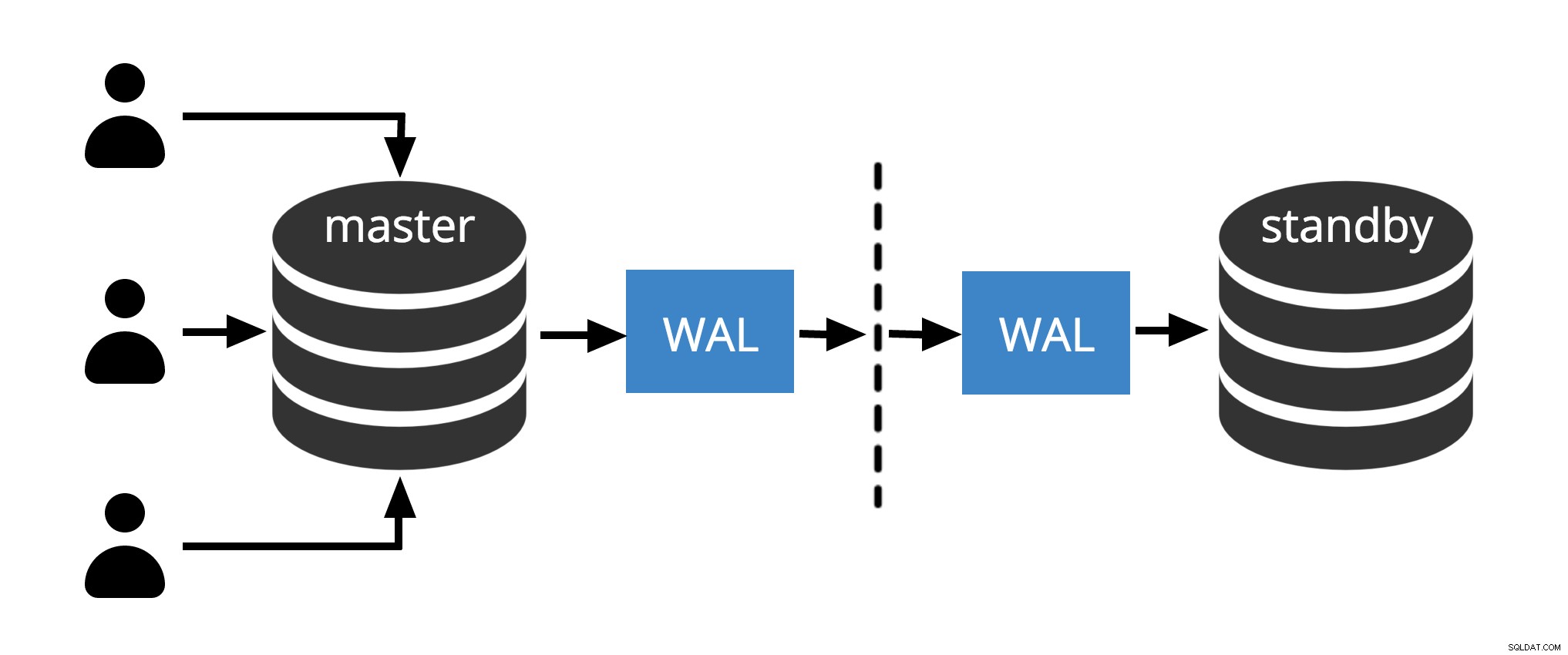
Gbr.1 Replikasi Fisik
Gbr.1 menunjukkan bagaimana replikasi fisik bekerja hanya dengan dua node. Klien mengeksekusi query pada master node, perubahan ditulis ke log transaksi (WAL) dan disalin melalui jaringan ke WAL pada node standby. Proses pemulihan pada node siaga kemudian membaca perubahan dari WAL dan menerapkannya ke file data seperti saat pemulihan macet. Jika standby dalam hot standby mode, klien dapat mengeluarkan kueri hanya-baca pada node saat ini terjadi.
Catatan: Replikasi Fisik hanya mengacu pada pengiriman file WAL melalui jaringan dari master ke node siaga. File dapat dikirim dengan protokol yang berbeda seperti scp, rsync, ftp… perbedaan antara Replikasi Fisik dan Replikasi Streaming Fisik adalah Replikasi Streaming menggunakan protokol internal untuk mengirim file WAL (pengirim dan proses penerima )
Mode Siaga
Beberapa node menyediakan Ketersediaan Tinggi. Untuk alasan itu arsitektur modern biasanya memiliki node siaga. Ada mode berbeda untuk node siaga (standby hangat dan panas). Daftar di bawah ini menjelaskan perbedaan mendasar antara mode siaga yang berbeda, dan juga menunjukkan kasus arsitektur multi-master.
Siaga Hangat
Dapat segera diaktifkan, tetapi tidak dapat melakukan pekerjaan yang berguna sampai diaktifkan. Jika kita terus-menerus mengumpankan rangkaian file WAL ke komputer lain yang telah dimuat dengan file cadangan dasar yang sama, kita memiliki sistem siaga hangat:kapan saja kita dapat membuka mesin kedua dan itu akan memiliki salinan hampir-saat ini dari data. Siaga hangat tidak mengizinkan kueri hanya-baca, Gbr.2 hanya mewakili fakta ini.
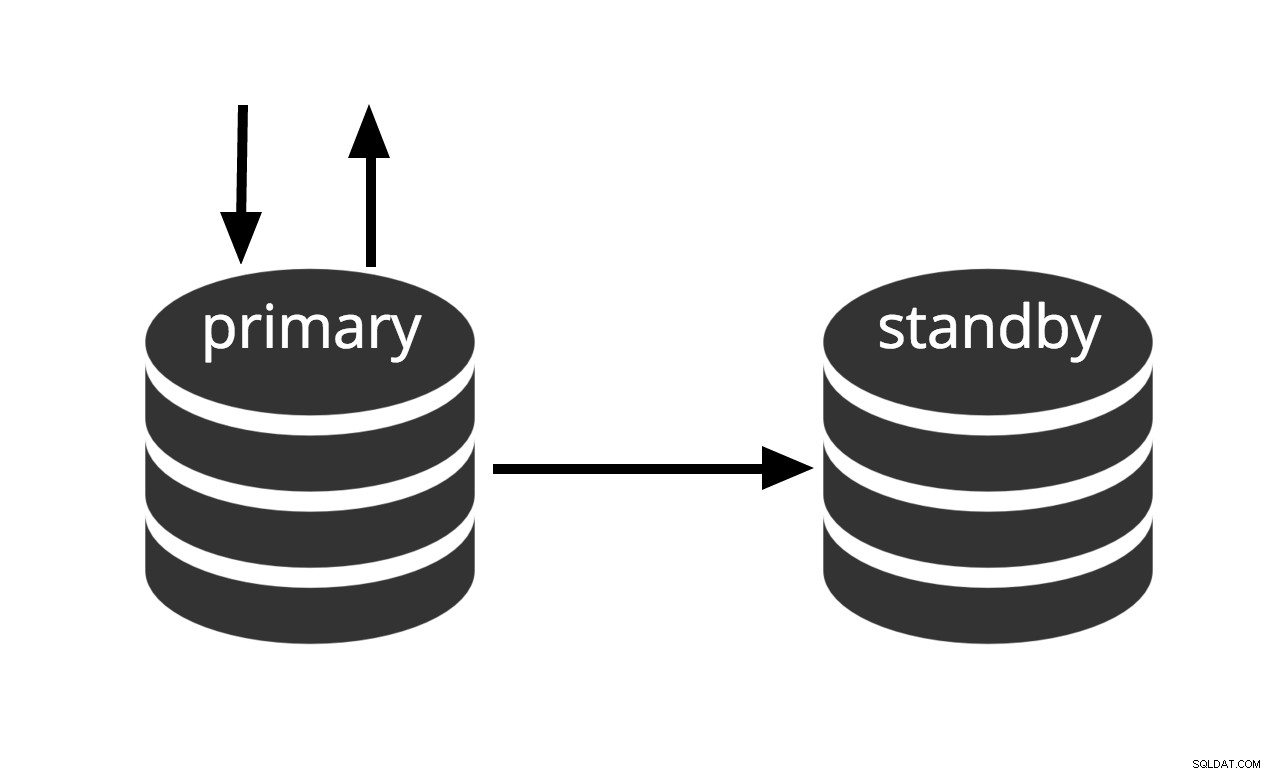
Gbr.2 Siaga Hangat
Performa pemulihan siaga hangat cukup baik sehingga siaga biasanya hanya beberapa saat lagi dari ketersediaan penuh setelah diaktifkan. Akibatnya, ini disebut konfigurasi siaga hangat yang menawarkan ketersediaan tinggi.
Siaga Panas
Siaga panas adalah istilah yang digunakan untuk menggambarkan kemampuan untuk terhubung ke server dan menjalankan kueri hanya-baca saat server dalam pemulihan arsip atau mode siaga. Ini berguna baik untuk tujuan replikasi dan untuk memulihkan cadangan ke keadaan yang diinginkan dengan presisi tinggi.
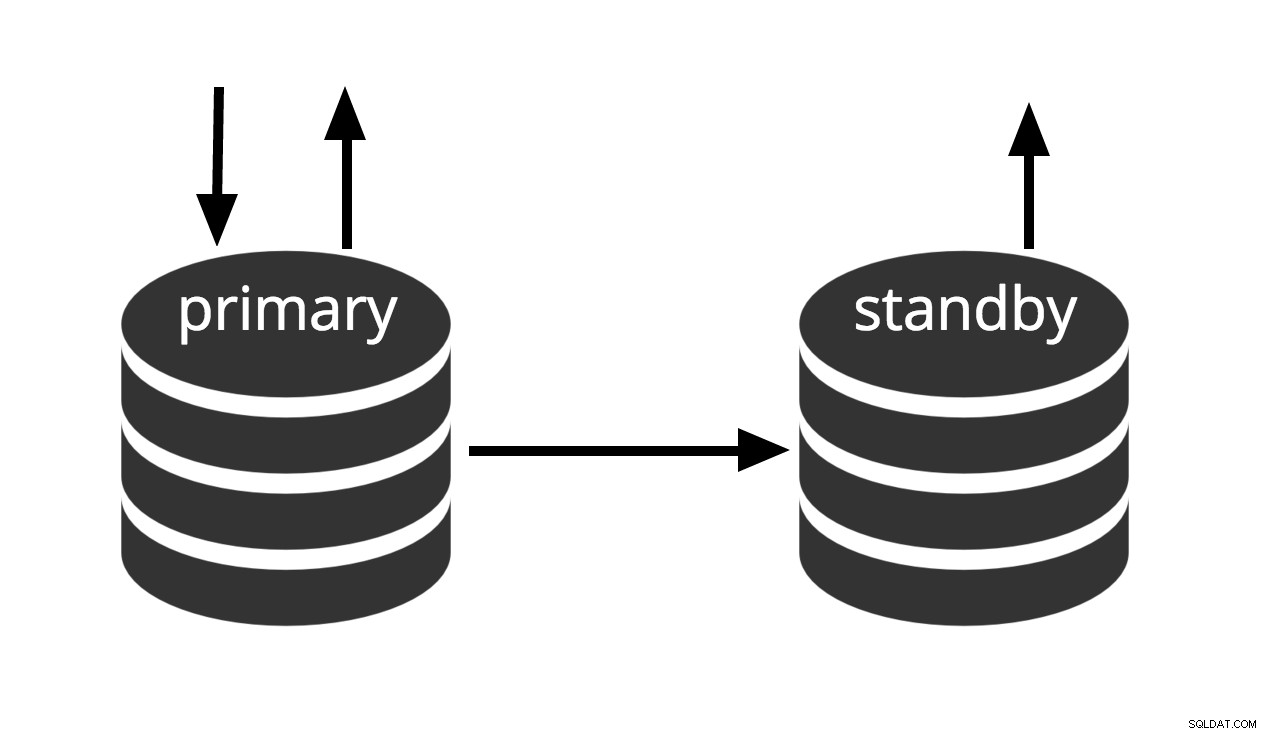 Gbr.3 Siaga Panas
Gbr.3 Siaga Panas
Istilah siaga panas juga mengacu pada kemampuan server untuk berpindah dari pemulihan ke operasi normal sementara pengguna terus menjalankan kueri dan/atau menjaga koneksi mereka tetap terbuka. Gbr.3 menunjukkan bahwa mode standby memungkinkan query read-only.
Multi-Master
Semua node dapat melakukan pekerjaan baca/tulis. (Kami akan membahas arsitektur multi-master di entri blog seri berikutnya.)
Parameter tingkat WAL
Ada hubungan antara pengaturan wal_level parameter dalam file postgresql.conf dan untuk apa pengaturan ini cocok. Saya membuat tabel untuk menampilkan relasi PostgreSQL versi 9.6.

Failover dan Switchover
Dalam replikasi master tunggal, jika master mati, salah satu standby harus menggantikannya (promosi ). Jika tidak, kami tidak akan dapat menerima transaksi tulis baru. Jadi, istilah penunjukan, master dan standby, hanyalah peran yang dapat diambil oleh node mana pun di beberapa titik. Untuk memindahkan peran master ke node lain, kami melakukan prosedur bernama Switchover .
Jika master mati dan tidak pulih, maka perubahan peran yang lebih parah dikenal sebagai Failover . Dalam banyak hal, ini bisa serupa, tetapi akan membantu jika menggunakan istilah yang berbeda untuk setiap peristiwa. (Mengetahui persyaratan failover dan switchover akan membantu kami memahami masalah timeline di entri blog berikutnya.)
Kesimpulan
Dalam posting blog ini kami membahas replikasi PostgreSQL dan pentingnya menyediakan toleransi kesalahan dan ketergantungan. Kami membahas Replikasi Streaming Fisik dan berbicara tentang Mode Siaga untuk PostgreSQL. Kami menyebutkan Failover dan Switchover. Kami akan melanjutkan timeline PostgreSQL di entri blog berikutnya.
Referensi
Dokumentasi PostgreSQL
Replikasi Logis di PostgreSQL 5432…Presentasi MeetUs oleh Petr Jelinek
Buku Masak Administrasi PostgreSQL 9 – Edisi Kedua