Topik caching muncul di PostgreSQL sejak 22 tahun yang lalu, dan pada saat itu fokusnya adalah pada keandalan basis data.
Maju cepat ke tahun 2020, piringan disk disembunyikan lebih dalam ke lingkungan tervirtualisasi, hypervisor, dan peralatan penyimpanan terkait. Selain itu, aplikasi terdistribusi yang saling terhubung yang beroperasi pada skala global menuntut koneksi latensi rendah dan tiba-tiba menyetel cache server, dan kueri SQL bersaing untuk memastikan hasilnya dikembalikan ke klien dalam milidetik. Level aplikasi dan cache dalam memori lahir, dan kueri baca sekarang disimpan dekat dengan server aplikasi. Akibatnya, operasi I/O dikurangi menjadi penulisan saja, dan latensi jaringan meningkat secara dramatis. Dengan satu tangkapan. Implementasi bertanggung jawab atas manajemen cache mereka sendiri yang terkadang menyebabkan penurunan kinerja.
Caching menulis adalah masalah yang jauh lebih rumit, seperti yang dijelaskan di wiki PostgreSQL.
Blog ini adalah ikhtisar cache kueri dalam memori dan penyeimbang beban yang digunakan dengan PostgreSQL.
Penyeimbangan Beban PostgreSQL
Ide penyeimbangan beban muncul bersamaan dengan caching, pada tahun 1999, ketika Bruce Momjiam menulis:
[...] mungkin saja kami _sangat_ populer dalam waktu dekat.
Dasar untuk menerapkan penyeimbangan beban di PostgreSQL disediakan oleh fitur Hot Standby bawaan. Satu-satunya persyaratan adalah aplikasi untuk menangani failover dan di sinilah solusi pihak ketiga masuk. Kita akan melihat beberapa solusi tersebut di bagian selanjutnya.
Memuat kueri seimbang hanya dapat mengembalikan hasil yang konsisten selama jeda replikasi sinkron tetap rendah. Dalam praktiknya, bahkan infrastruktur jaringan canggih seperti AWS mungkin menunjukkan penundaan puluhan milidetik:
Kami biasanya mengamati waktu jeda dalam 10 detik milidetik. [...] Namun, dalam kondisi umum, jeda replikasi di bawah satu menit adalah hal biasa. [...]
Replika lintas wilayah yang menggunakan replikasi logis akan dipengaruhi oleh tingkat perubahan/penerapan dan penundaan dalam komunikasi jaringan antara wilayah tertentu yang dipilih. Replika lintas wilayah yang menggunakan Aurora Global Database biasanya memiliki jeda kurang dari satu detik.
Seperti yang dinyatakan sebelumnya, solusi pihak ketiga mengandalkan fitur inti PostgreSQL. Misalnya, penyeimbangan beban kueri baca dicapai menggunakan beberapa siaga sinkron.
Solusi
pgpool-II
pgpool-II adalah produk kaya fitur yang menyediakan penyeimbangan beban dan cache kueri dalam memori. Ini adalah pengganti drop-in, tidak ada perubahan pada sisi aplikasi yang diperlukan.
Sebagai penyeimbang beban, pgpool-II memeriksa setiap kueri SQL — agar beban seimbang, kueri SELECT harus memenuhi beberapa kondisi.
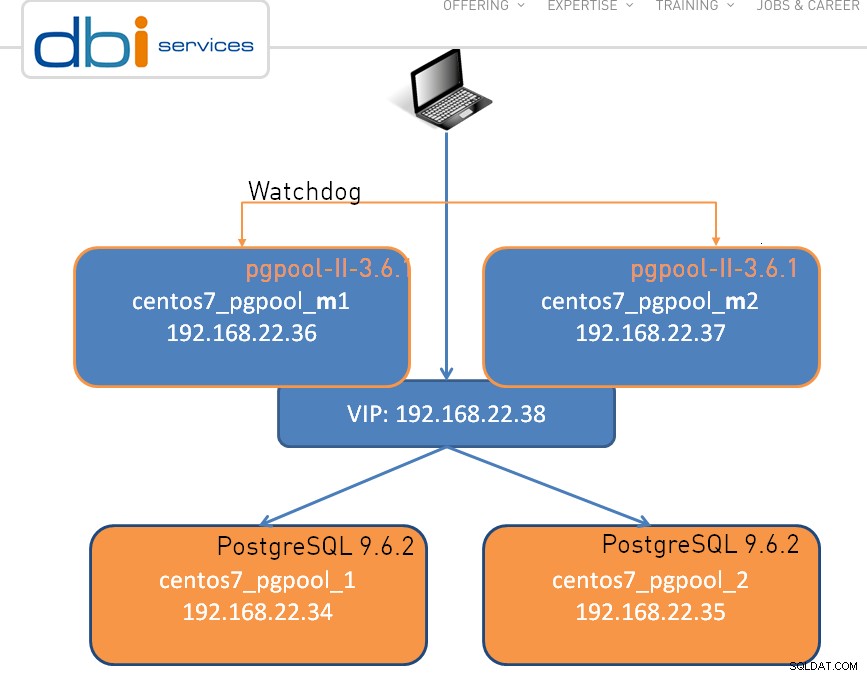
Pengaturan dapat sesederhana satu node, yang ditunjukkan di bawah ini adalah cluster dual-node:
Seperti halnya perangkat lunak yang hebat, ada batasan tertentu , dan pgpool-II tidak terkecuali:
- Tidak menangani kueri multi-pernyataan.
- Kueri PILIH pada tabel sementara memerlukan komentar /*NO LOAD BALANCE*/ SQL.
Aplikasi yang berjalan di lingkungan berkinerja tinggi akan mendapat manfaat dari konfigurasi campuran di mana pgBouncer adalah pooler koneksi dan pgpool-II menangani penyeimbangan beban dan caching. Hasilnya adalah peningkatan throughput 4 kali yang mengesankan dan pengurangan latensi 40 persen:
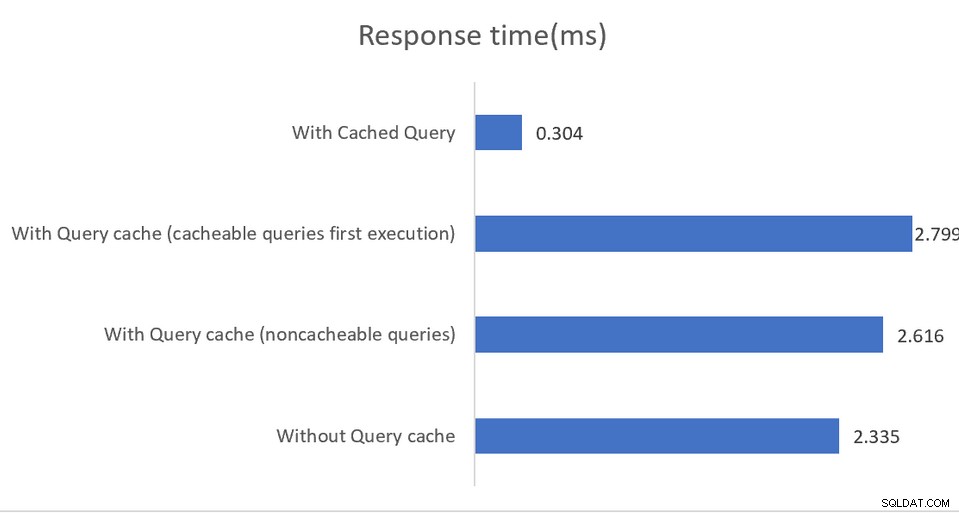
Caching dalam memori berfungsi, sekali lagi, hanya pada kueri baca, dengan cache data disimpan baik ke dalam memori bersama atau ke dalam instalasi memcached eksternal. Sementara dokumentasi cukup baik dalam menjelaskan berbagai opsi konfigurasi, secara tidak langsung menyarankan bahwa implementasi harus memantau output SHOW POOL CACHE untuk memperingatkan rasio hit yang jatuh di bawah tanda 70%, di mana peningkatan kinerja yang disediakan oleh caching hilang.
Bucardo
Bucardo adalah alat replikasi PostgreSQL yang ditulis dalam Perl dan PL/Perl.
Saya telah menyebutkan Bucardo, karena load balancing adalah salah satu fiturnya, menurut wiki PostgreSQL, namun, pencarian di internet tidak memberikan hasil yang relevan. Untuk memperjelas, saya menuju ke dokumentasi resmi yang membahas detail tentang cara kerja perangkat lunak ini:

Itu membuatnya cukup jelas, Bucardo bukan penyeimbang beban, sama seperti ditunjukkan oleh orang-orang di Database Soup.
HAProxy
HAProxy adalah penyeimbang beban tujuan umum yang beroperasi pada tingkat TCP (untuk tujuan koneksi database). Health check memastikan bahwa kueri hanya dikirim ke node yang hidup.
Dibandingkan dengan pgpool-II, aplikasi yang menggunakan HAProxy sebagai penyeimbang beban, harus diberi tahu tentang permintaan pengiriman titik akhir ke node pembaca.
Apache Ignite
Apache Ignite adalah cache tingkat kedua yang memahami ANSI-99 SQL dan menyediakan dukungan untuk transaksi ACID. Apache Ignite tidak memahami PostgreSQL Frontend/Backend Protocol dan oleh karena itu aplikasi harus menggunakan salah satu lapisan persistensi seperti Hibernate ORM. Sebagai alternatif untuk memodifikasi aplikasi, Apache Ignite menyediakan `memcached integration`_ yang memerlukan ekstensi PostgreSQL memcached. Sayangnya, opsi terakhir ini tidak kompatibel dengan PostgreSQL versi terbaru, karena ekstensi pgmemcache terakhir diperbarui pada tahun 2017.
Data Heimdall
Sebagai produk komersial, Heimdall Data mencentang kedua kotak:load balancing dan caching. Ini adalah produk yang matang, yang telah dipamerkan di konferensi PostgreSQL sejak PGCon 2017:

Detail lebih lanjut dan demo produk dapat ditemukan di blog Azure untuk PostgreSQL .
Kesimpulan
Dalam komputasi terdistribusi saat ini, Query Caching dan Load Balancing sama pentingnya dengan penyetelan kinerja PostgreSQL seperti halnya GUC, kernel OS, penyimpanan, dan pengoptimalan kueri yang terkenal. Sementara pgpool-II dan Heimdall Data adalah open source dan masing-masing, solusi pilihan komersial, ada kasus di mana alat yang dibuat dengan sengaja dapat digunakan sebagai blok pembangun untuk mencapai hasil yang serupa.