Blog ini adalah bagian kedua dari Menerapkan Pengaturan Multi-Pusat Data untuk PostgreSQL. Dalam kesempatan ini, kami akan menunjukkan cara menerapkan PostgreSQL di lingkungan jenis ini dan cara melakukan failover jika terjadi kegagalan master menggunakan fitur pemulihan otomatis ClusterControl.
Pada titik ini, kami akan menganggap Anda memiliki konektivitas antara pusat data (seperti yang kita lihat di bagian pertama blog ini) dan Anda memiliki server yang diperlukan untuk tugas ini (seperti yang juga kami sebutkan di bagian sebelumnya).
Menerapkan Cluster PostgreSQL
Kami akan menggunakan ClusterControl untuk tugas ini, jadi kami akan menganggap Anda telah menginstalnya (bisa diinstal pada server Load Balancer yang sama, tetapi jika Anda dapat menggunakan yang berbeda lebih baik lagi).
Buka server ClusterControl Anda, dan pilih opsi 'Deploy'. Jika Anda sudah menjalankan instance PostgreSQL, Anda harus memilih 'Import Existing Server/Database'.
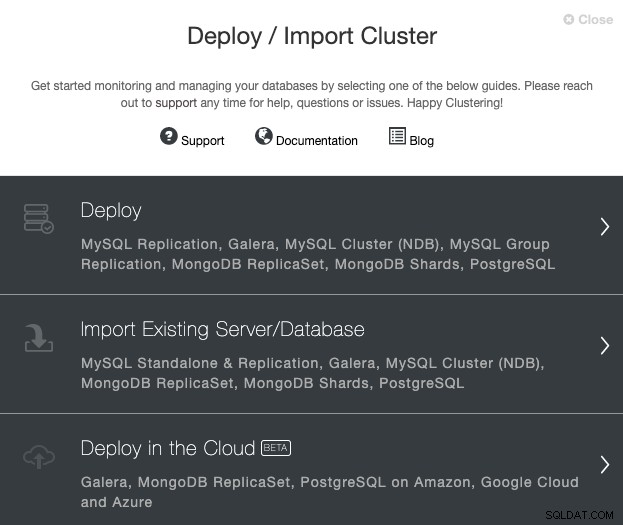
Saat memilih PostgreSQL, Anda harus menentukan Pengguna, Kunci atau Kata Sandi dan port ke terhubung dengan SSH ke host PostgreSQL kami. Anda juga memerlukan nama untuk cluster baru Anda dan jika Anda ingin ClusterControl menginstal perangkat lunak dan konfigurasi yang sesuai untuk Anda.
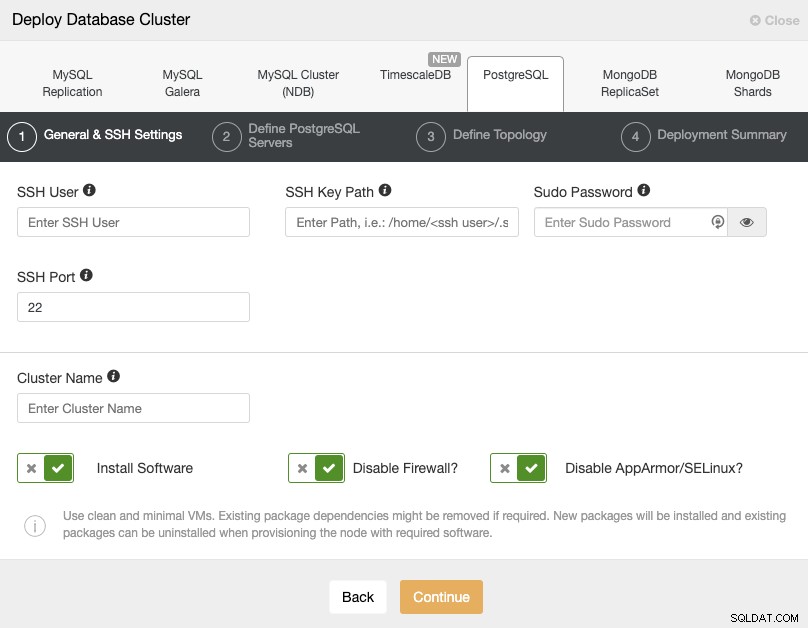
Silakan periksa persyaratan pengguna ClusterControl untuk tugas ini di sini, tetapi jika Anda mengikuti blog sebelumnya, Anda harus menggunakan pengguna 'jarak jauh' di sini dan port SSH yang benar (seperti yang kami sebutkan, disarankan untuk menggunakan yang berbeda jika Anda menggunakan alamat IP publik untuk mengaksesnya daripada VPN).
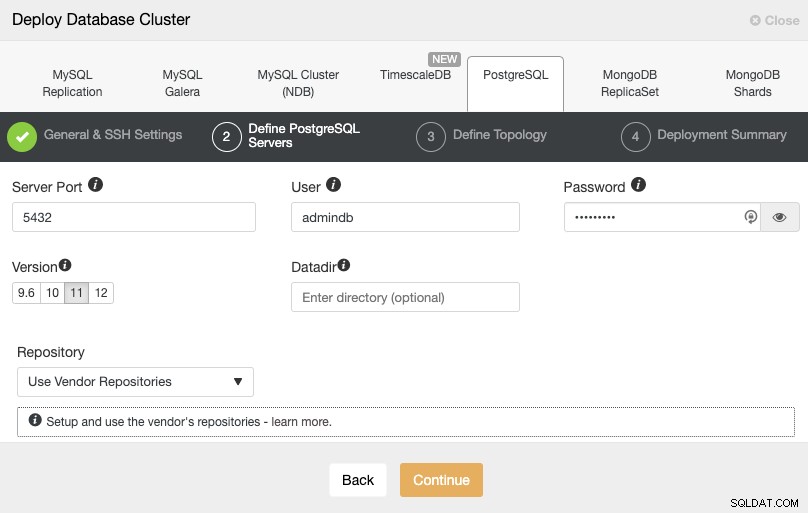
Setelah menyiapkan informasi akses SSH, Anda harus menentukan pengguna database, versi dan datadir (opsional). Anda juga dapat menentukan repositori mana yang akan digunakan. Pada langkah selanjutnya, Anda perlu menambahkan server Anda ke cluster yang akan Anda buat.
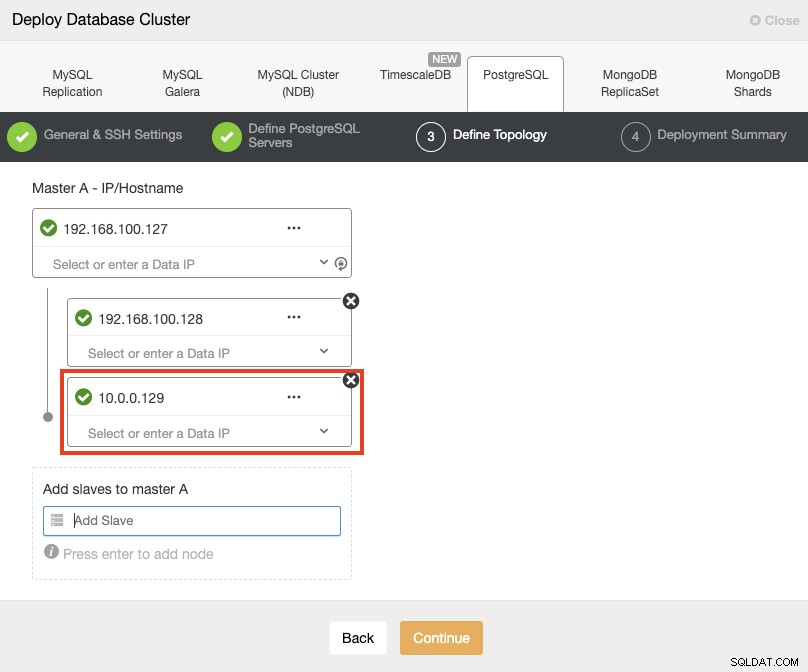
Saat menambahkan server, Anda dapat memasukkan IP atau nama host. Di bagian ini, Anda akan menggunakan alamat IP publik server Anda, dan seperti yang Anda lihat di kotak merah, saya menggunakan jaringan yang berbeda untuk node siaga kedua. ClusterControl tidak memiliki batasan tentang jaringan yang akan digunakan. Satu-satunya persyaratan tentang ini adalah memiliki akses SSH ke node.
Jadi mengikuti contoh kita sebelumnya, alamat IP ini seharusnya:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)Pada langkah terakhir, Anda dapat memilih apakah replikasi Anda akan Sinkron atau Asinkron.
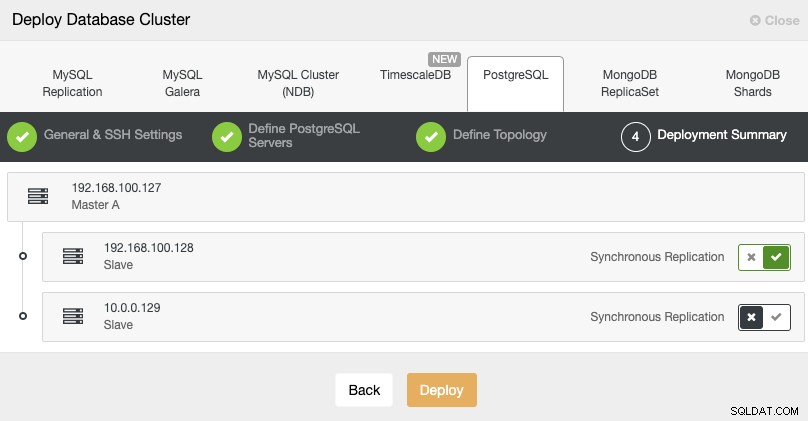
Dalam hal ini, penting untuk menggunakan replikasi Asinkron untuk node jarak jauh Anda , jika tidak, cluster Anda dapat terpengaruh oleh latensi atau masalah jaringan.
Anda dapat memantau status pembuatan cluster baru Anda dari monitor aktivitas ClusterControl.
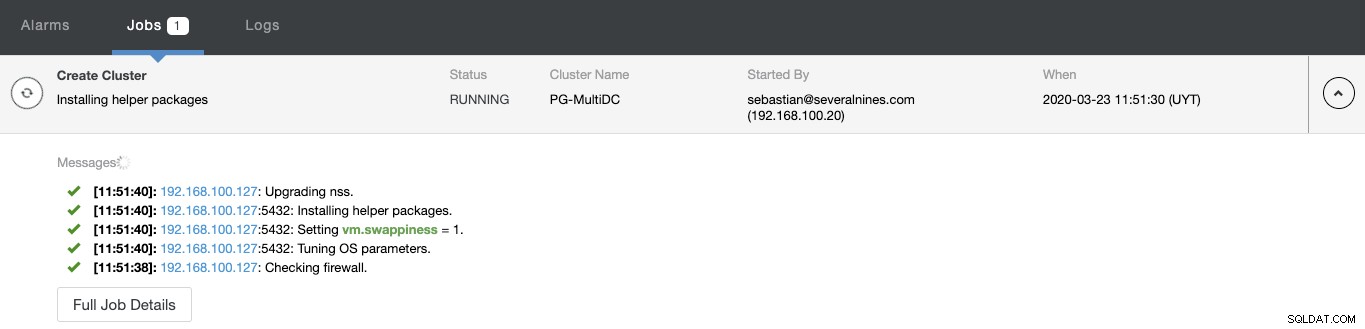
Setelah tugas selesai, Anda dapat melihat klaster PostgreSQL baru Anda di layar ClusterControl utama.

Menambahkan Penyeimbang Beban PostgreSQL (HAProxy)
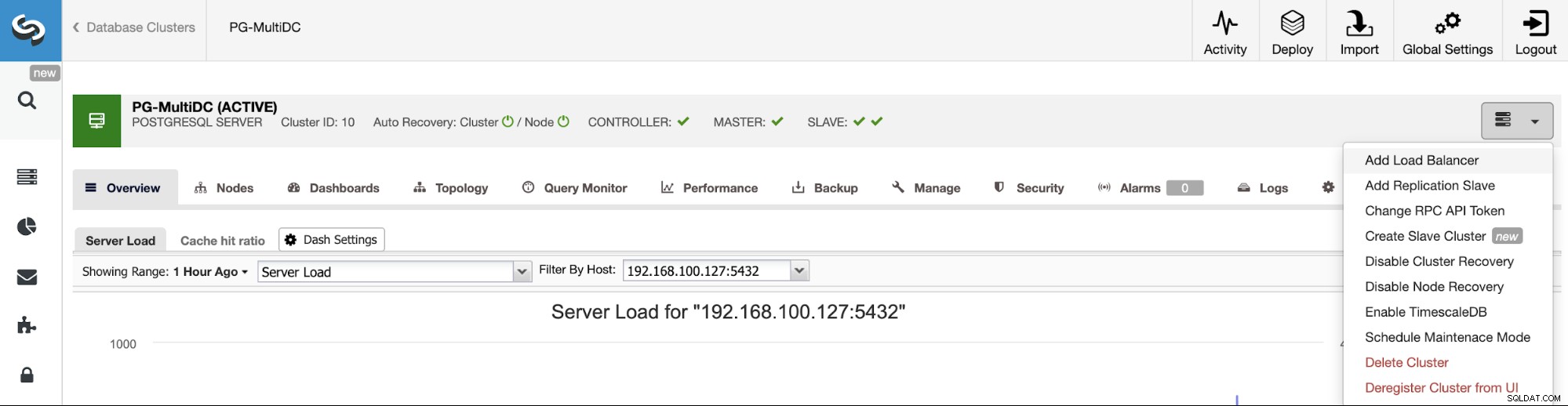
Setelah cluster Anda dibuat, Anda dapat melakukan beberapa tugas di dalamnya, seperti menambahkan penyeimbang beban (HAProxy) atau replika baru.
Untuk mengikuti contoh sebelumnya, mari tambahkan penyeimbang beban yang, seperti yang telah disebutkan, akan membantu Anda mengelola lingkungan HA Anda. Untuk ini, buka ClusterControl -> Pilih PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer.
Di sini Anda harus menambahkan informasi yang akan digunakan ClusterControl untuk menginstal dan mengkonfigurasi Penyeimbang beban HAProxy. Load Balancer ini dapat diinstal di server ClusterControl yang sama, tetapi jika Anda dapat menggunakan yang berbeda, lebih baik lagi.
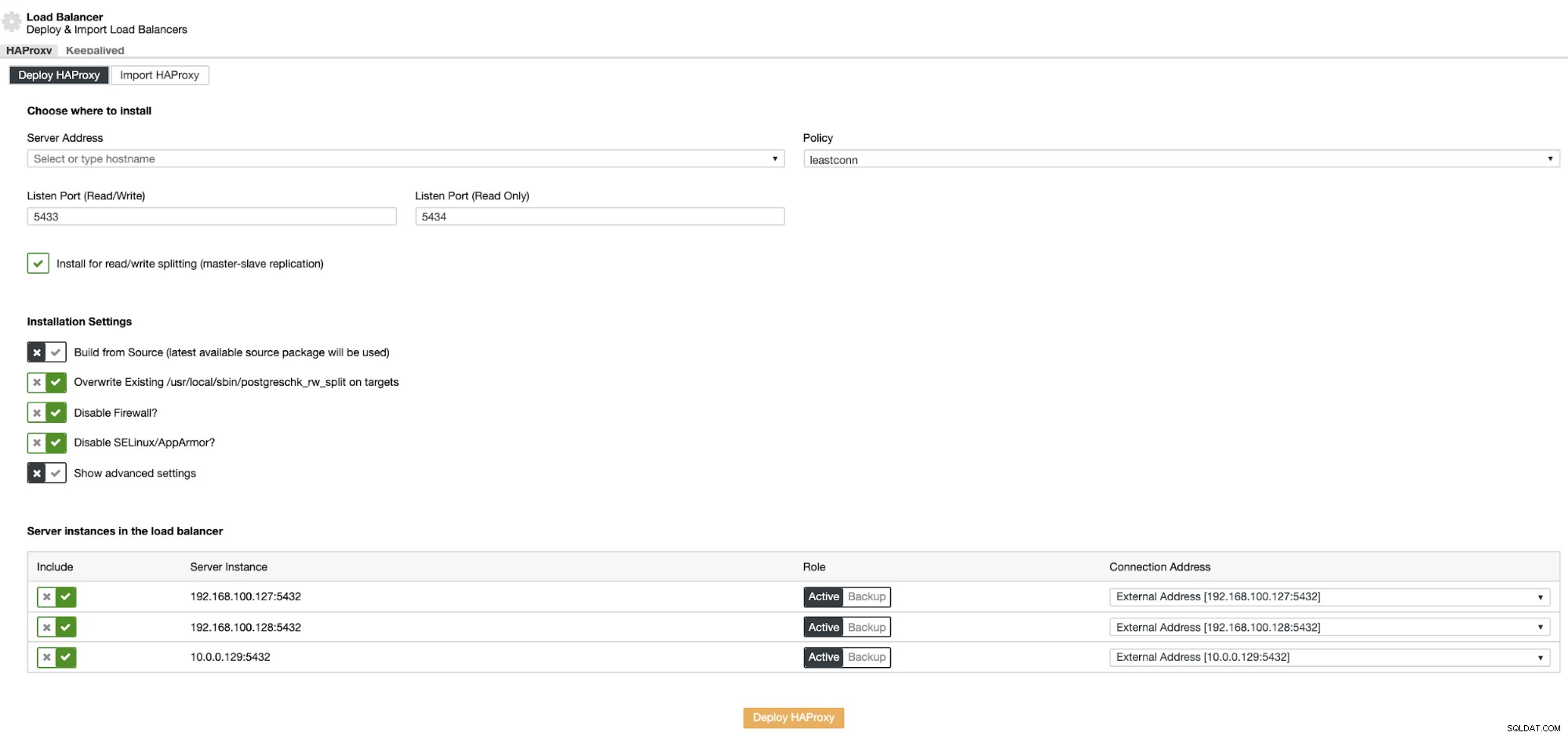
Informasi yang perlu Anda perkenalkan adalah:
Tindakan:Terapkan atau Impor.
Alamat Server:Alamat IP untuk server HAProxy Anda (Dapat berupa Alamat IP ClusterControl yang sama).
Listen Port (Baca/Tulis):Port untuk mode baca/tulis.
Listen Port (Read Only):Port untuk mode hanya baca.
Kebijakan:Bisa berupa:
- leastconn:Server dengan jumlah koneksi terendah menerima koneksi.
- roundrobin:Setiap server digunakan secara bergiliran, sesuai dengan bobotnya.
- sumber:Alamat IP sumber di-hash dan dibagi dengan berat total server yang berjalan untuk menentukan server mana yang akan menerima permintaan.
Instal untuk pemisahan baca/tulis:Untuk replikasi master-slave.
Build from Source:Anda dapat memilih Instal dari pengelola paket atau build dari sumber.
Dan Anda harus memilih server mana yang ingin Anda tambahkan ke konfigurasi HAProxy.
Selain itu, Anda dapat mengonfigurasi Setelan Lanjutan seperti Pengguna Admin, Nama Backend, Waktu Habis, dan lainnya.
Saat Anda menyelesaikan konfigurasi dan mengonfirmasi penerapan, Anda dapat mengikuti perkembangannya di bagian Aktivitas pada UI ClusterControl.
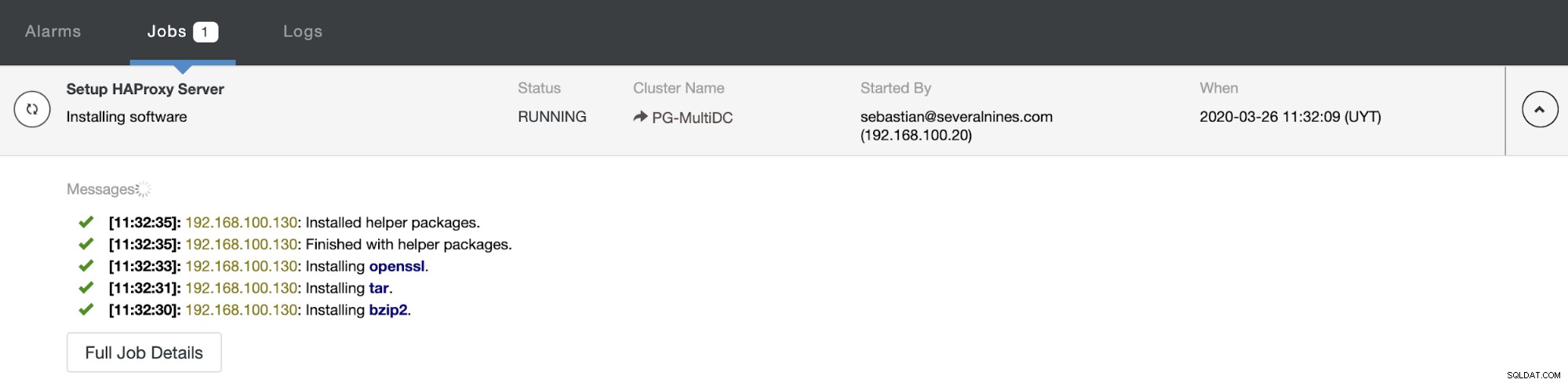
Dan ketika ini selesai, Anda dapat pergi ke ClusterControl -> Nodes -> HAProxy node, dan periksa status saat ini.
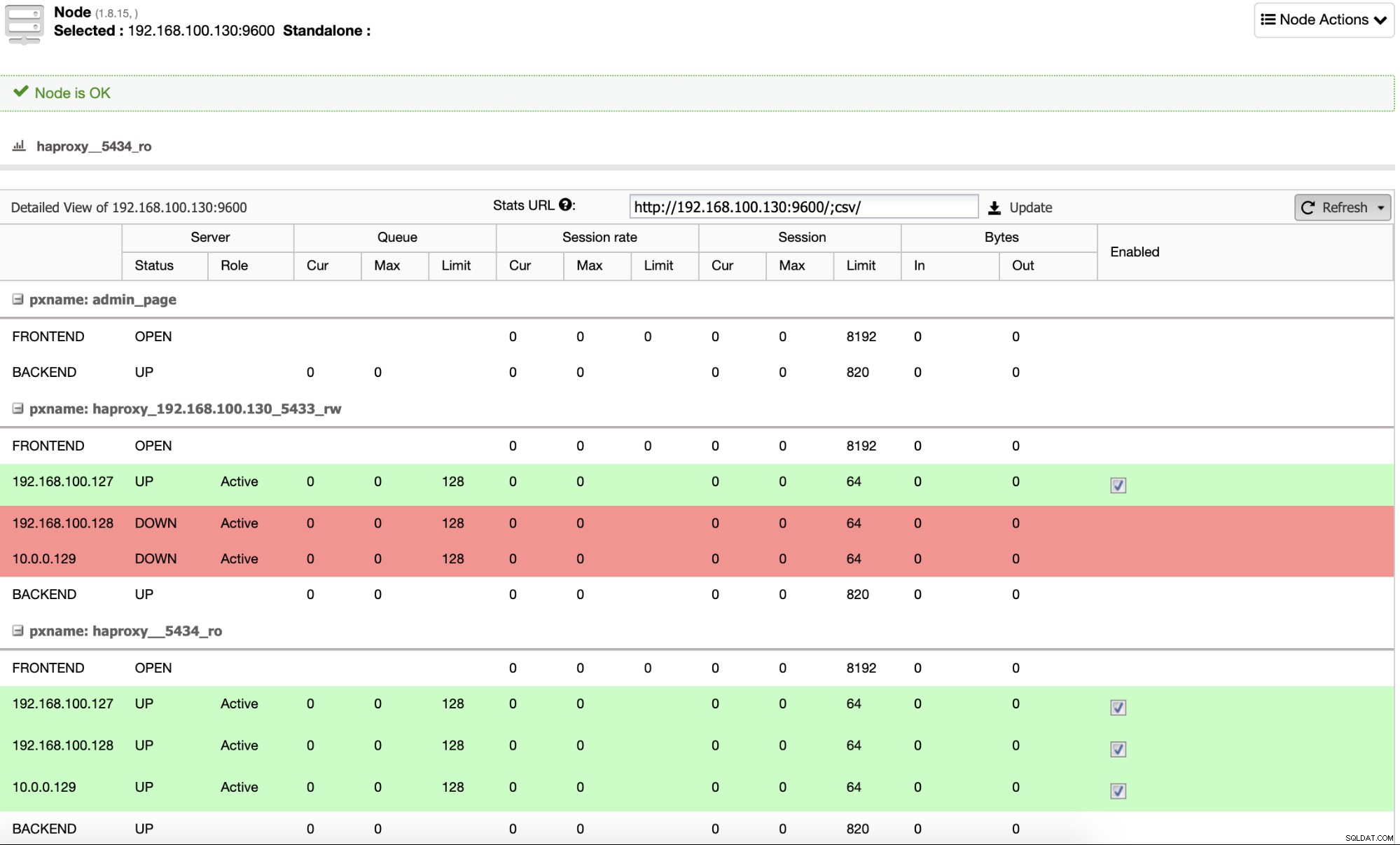
Secara default, ClusterControl mengonfigurasi HAProxy dengan dua port berbeda, satu untuk Read- Write, yang akan digunakan untuk aplikasi atau pengguna untuk menulis (dan membaca) data, dan satu lagi untuk Read-Only, yang akan digunakan untuk menyeimbangkan lalu lintas baca antara semua node. Di port Baca-Tulis, hanya node master yang diaktifkan, dan jika terjadi kegagalan master, ClusterControl akan mempromosikan budak paling canggih ke master dan akan mengkonfigurasi ulang port ini untuk menonaktifkan master lama dan mengaktifkan yang baru. Dengan cara ini, aplikasi Anda masih dapat bekerja jika terjadi kegagalan database master, karena lalu lintas dialihkan oleh Load Balancer ke node yang benar.
Anda juga dapat memantau server HAProxy Anda dengan memeriksa bagian Dasbor.
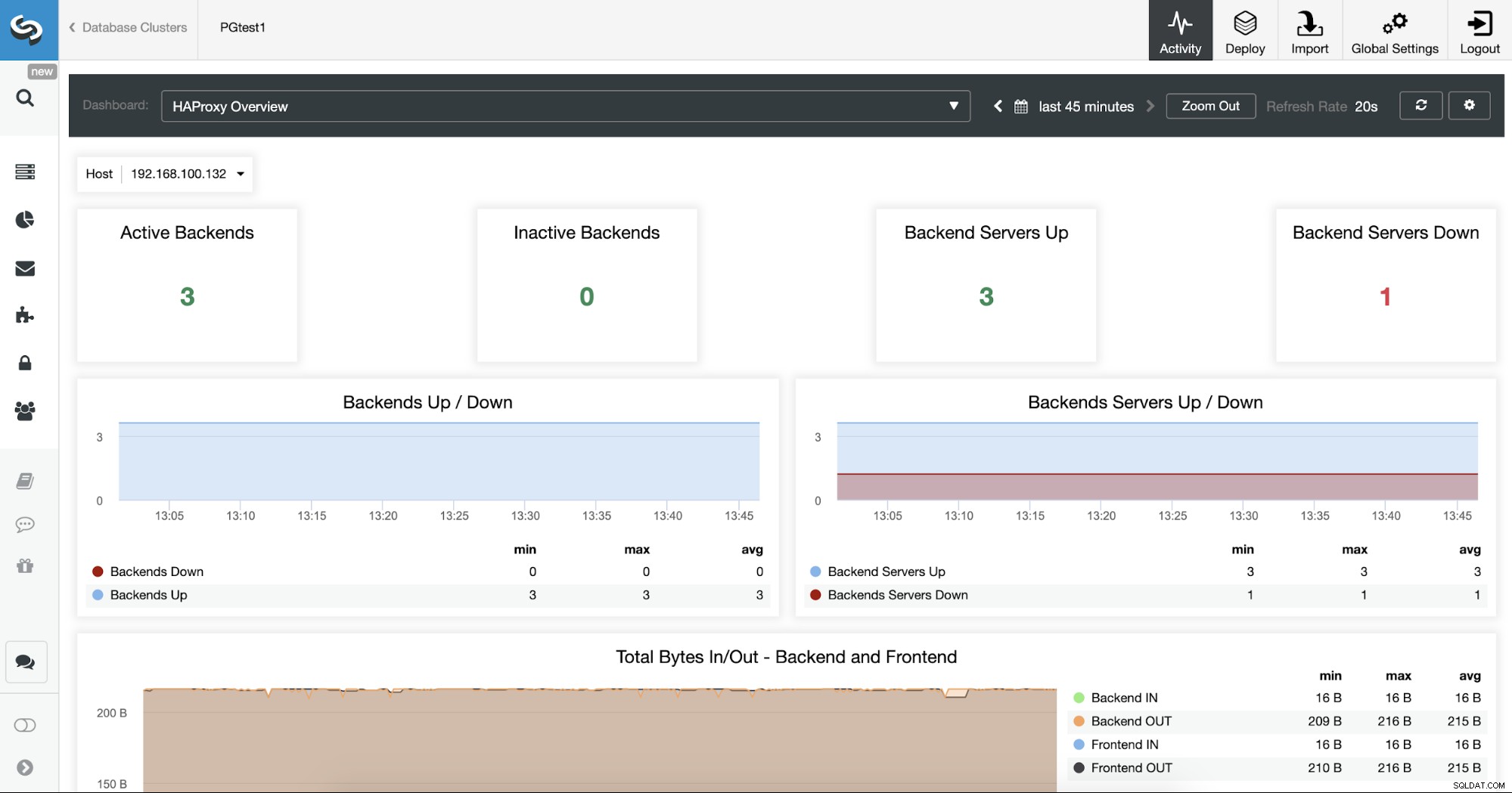
Sekarang, Anda dapat meningkatkan desain HA dengan menambahkan simpul HAProxy baru di pusat data jarak jauh dan mengonfigurasi layanan Keepalive di antara mereka. Keepalive akan memungkinkan Anda untuk menggunakan alamat IP virtual yang ditetapkan ke node Load Balancer aktif. Jika node ini gagal, IP virtual ini akan dimigrasikan ke node HAProxy sekunder, jadi mengonfigurasi IP ini di aplikasi Anda akan memungkinkan Anda untuk menjaga semuanya tetap berfungsi jika terjadi masalah Load Balancer.
Semua konfigurasi ini dapat dilakukan menggunakan ClusterControl.
Kesimpulan
Dengan mengikuti blog dua bagian ini, Anda dapat menerapkan pengaturan multi-pusat data untuk PostgreSQL dengan Ketersediaan Tinggi dan konektivitas SSH antara pusat data, untuk menghindari kerumitan konfigurasi VPN.
Menggunakan replikasi asinkron untuk node jarak jauh Anda akan menghindari masalah apa pun yang terkait dengan latensi dan kinerja jaringan, dan menggunakan ClusterControl Anda akan memiliki failover otomatis (atau manual) jika terjadi kegagalan (di antara beberapa fitur lainnya). Ini bisa menjadi cara paling sederhana untuk mencapai topologi ini dan kami harap ini bermanfaat bagi Anda.



