Semua sistem database modern mendukung modul Pengoptimal Kueri untuk secara otomatis mengidentifikasi strategi yang paling efisien untuk mengeksekusi kueri SQL. Strategi yang efisien disebut “Rencana” dan diukur dari segi biaya yang berbanding lurus dengan “Eksekusi Kueri/Waktu Respons”. Rencana tersebut direpresentasikan dalam bentuk keluaran pohon dari Pengoptimal Kueri. Node pohon rencana dapat dibagi menjadi 3 kategori berikut:
- Pindai Node :Seperti yang dijelaskan di blog saya sebelumnya “Ikhtisar Berbagai Metode Pemindaian di PostgreSQL”, ini menunjukkan cara data tabel dasar perlu diambil.
- Gabung dengan Node :Seperti yang dijelaskan di blog saya sebelumnya “Sebuah Tinjauan Metode JOIN di PostgreSQL”, ini menunjukkan bagaimana dua tabel perlu digabungkan untuk mendapatkan hasil dari dua tabel.
- Node Materialisasi :Juga disebut sebagai node bantu. Dua jenis node sebelumnya terkait dengan cara mengambil data dari tabel dasar dan cara menggabungkan data yang diambil dari dua tabel. Node dalam kategori ini diterapkan di atas data yang diambil untuk menganalisis lebih lanjut atau menyiapkan laporan, dll. Menyortir data, agregat data, dll.
Pertimbangkan contoh kueri sederhana seperti...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Misalkan rencana yang dibuat sesuai dengan kueri seperti di bawah ini:
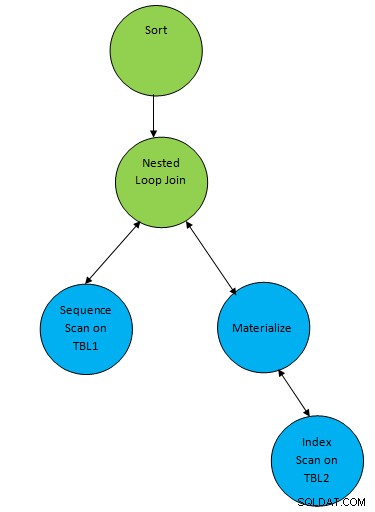
Jadi di sini satu simpul tambahan "Urutkan" ditambahkan di atas hasil dari join untuk mengurutkan data sesuai urutan yang diinginkan.
Beberapa node tambahan yang dihasilkan oleh pengoptimal kueri PostgreSQL adalah sebagai berikut:
- Urutkan
- Agregat
- Kelompokkan Berdasarkan Agregat
- Batas
- Unik
- LockRows
- SetOp
Mari kita pahami masing-masing node ini.
Urutkan
Seperti namanya, simpul ini ditambahkan sebagai bagian dari pohon rencana setiap kali ada kebutuhan untuk data yang diurutkan. Data yang diurutkan dapat diperlukan secara eksplisit atau implisit seperti dua kasus di bawah ini:
Skenario pengguna memerlukan data yang diurutkan sebagai output. Dalam hal ini, simpul Sortir dapat berada di atas seluruh pengambilan data termasuk semua pemrosesan lainnya.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Catatan: Meskipun pengguna membutuhkan hasil akhir dalam urutan yang diurutkan, simpul Sortir tidak dapat ditambahkan dalam rencana akhir jika ada indeks pada tabel dan kolom penyortiran yang sesuai. Dalam hal ini, ia dapat memilih pemindaian indeks yang akan menghasilkan urutan data yang diurutkan secara implisit. Sebagai contoh, mari kita buat indeks pada contoh di atas dan lihat hasilnya:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Seperti yang dijelaskan di blog saya sebelumnya Gambaran Umum Metode GABUNG di PostgreSQL, Gabung Gabung mengharuskan kedua data tabel diurutkan sebelum bergabung. Jadi mungkin saja Merge Join lebih murah daripada metode join lainnya bahkan dengan tambahan biaya penyortiran. Jadi dalam hal ini, simpul Sort akan ditambahkan antara metode join dan scan tabel sehingga record yang diurutkan dapat diteruskan ke metode join.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Agregat
Simpul agregat ditambahkan sebagai bagian dari pohon rencana jika ada fungsi agregat yang digunakan untuk menghitung hasil tunggal dari beberapa baris masukan. Beberapa fungsi agregat yang digunakan adalah COUNT, SUM, AVG (AVERAGE), MAX (MAXIMUM) dan MIN (MINIMUM).
Sebuah simpul agregat dapat muncul di atas pemindaian relasi dasar atau (dan) pada gabungan relasi. Contoh:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Node jenis ini adalah ekstensi dari simpul “Agregat”. Jika fungsi agregat digunakan untuk menggabungkan beberapa baris input sesuai dengan grupnya, maka jenis node ini ditambahkan ke pohon rencana. Jadi, jika kueri memiliki fungsi agregat yang digunakan dan bersama dengan itu ada klausa GROUP BY dalam kueri, maka node HashAggregate atau GroupAggregate akan ditambahkan ke pohon rencana.
Karena PostgreSQL menggunakan Pengoptimal Berbasis Biaya untuk menghasilkan pohon rencana yang optimal, hampir tidak mungkin untuk menebak simpul mana yang akan digunakan. Tapi mari kita pahami kapan dan bagaimana itu digunakan.
HashAggregate
HashAggregate bekerja dengan membuat tabel hash dari data untuk mengelompokkannya. Jadi HashAggregate dapat digunakan oleh agregat tingkat grup jika agregat terjadi pada kumpulan data yang tidak disortir.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Di sini data skema tabel demo1 sesuai dengan contoh yang ditampilkan di bagian sebelumnya. Karena hanya ada 1000 baris untuk dikelompokkan, maka sumber daya yang diperlukan untuk membuat tabel hash lebih murah daripada biaya penyortiran. Perencana kueri memutuskan untuk memilih HashAggregate.
GrupAgregat
GroupAggregate bekerja pada data yang diurutkan sehingga tidak memerlukan struktur data tambahan. GroupAggregate dapat digunakan oleh agregat level grup jika agregasi berada pada kumpulan data yang diurutkan. Untuk mengelompokkan data yang diurutkan, ia dapat mengurutkan secara eksplisit (dengan menambahkan simpul Sortir) atau mungkin bekerja pada data yang diambil oleh indeks yang dalam hal ini diurutkan secara implisit.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Di sini data skema tabel demo2 sesuai dengan contoh yang ditampilkan di bagian sebelumnya. Karena di sini ada 100.000 baris untuk dikelompokkan, jadi sumber daya yang diperlukan untuk membuat tabel hash mungkin lebih mahal daripada biaya penyortiran. Jadi perencana kueri memutuskan untuk memilih GroupAggregate. Amati di sini catatan yang dipilih dari tabel “demo2” diurutkan secara eksplisit dan untuk itu ada simpul yang ditambahkan di pohon rencana.
Lihat di bawah contoh lain, di mana data yang sudah diambil diurutkan karena pemindaian indeks:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Lihat di bawah satu contoh lagi, yang meskipun memiliki Index Scan, masih perlu diurutkan secara eksplisit sebagai kolom yang indeksnya ada dan kolom pengelompokannya tidak sama. Jadi masih perlu diurutkan sesuai kolom pengelompokan.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Catatan: GroupAggregate/HashAggregate dapat digunakan untuk banyak kueri tidak langsung lainnya meskipun agregasi dengan grup tidak ada di kueri. Itu tergantung pada bagaimana perencana menafsirkan kueri. Misalnya. Katakanlah kita perlu mendapatkan nilai yang berbeda dari tabel, kemudian dapat dilihat sebagai grup dengan kolom yang sesuai dan kemudian mengambil satu nilai dari setiap grup.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Jadi di sini HashAggregate digunakan meskipun tidak ada agregasi dan grup yang terlibat.
Batas
Limit node ditambahkan ke pohon rencana jika klausa “limit/offset” digunakan dalam kueri SELECT. Klausa ini digunakan untuk membatasi jumlah baris dan secara opsional menyediakan offset untuk mulai membaca data. Contoh di bawah ini:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Unik
Node ini dipilih untuk mendapatkan nilai yang berbeda dari hasil yang mendasarinya. Perhatikan bahwa tergantung pada kueri, selektivitas, dan info sumber daya lainnya, nilai yang berbeda dapat diambil menggunakan HashAggregate/GroupAggregate juga tanpa menggunakan simpul Unik. Contoh:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL menyediakan fungsionalitas untuk mengunci semua baris yang dipilih. Baris dapat dipilih dalam mode "Berbagi" atau mode "Eksklusif" tergantung pada klausa "UNTUK BERBAGI" dan "UNTUK UPDATE". Node baru “LockRows” ditambahkan ke pohon rencana dalam mencapai operasi ini.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL menyediakan fungsionalitas untuk menggabungkan hasil dari dua kueri atau lebih. Jadi saat jenis simpul Gabung dipilih untuk menggabungkan dua tabel, jenis simpul SetOp yang serupa akan dipilih untuk menggabungkan hasil dari dua atau lebih kueri. Misalnya, perhatikan tabel dengan karyawan dengan id, nama, usia dan gaji mereka seperti di bawah ini:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Sekarang mari dapatkan karyawan dengan usia lebih dari 25 tahun:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Sekarang mari dapatkan karyawan dengan gaji lebih dari 95 juta:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Sekarang untuk mendapatkan karyawan dengan usia lebih dari 25 tahun dan gaji lebih dari 95 juta, kita dapat menulis kueri berpotongan di bawah ini:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Jadi di sini, jenis node HashSetOp baru ditambahkan untuk mengevaluasi perpotongan dari dua kueri individual ini.
Perhatikan bahwa ada dua jenis simpul baru lainnya yang ditambahkan di sini:
Tambahkan
Node ini ditambahkan untuk menggabungkan beberapa hasil yang ditetapkan menjadi satu.
Pemindaian Subkueri
Node ini ditambahkan untuk mengevaluasi subquery apa pun. Dalam rencana di atas, subquery ditambahkan untuk mengevaluasi satu nilai kolom konstanta tambahan yang menunjukkan set input mana yang berkontribusi pada baris tertentu.
HashedSetop bekerja menggunakan hash dari hasil yang mendasarinya tetapi dimungkinkan untuk menghasilkan operasi SetOp berdasarkan Sort oleh pengoptimal kueri. Sortir berdasarkan node Setop dilambangkan sebagai “Setop”.
Catatan:Hal ini dimungkinkan untuk mencapai hasil yang sama seperti yang ditunjukkan pada hasil di atas dengan satu kueri tetapi di sini ditampilkan menggunakan intersect hanya untuk demonstrasi yang mudah.
Kesimpulan
Semua node PostgreSQL berguna dan dipilih berdasarkan sifat kueri, data, dll. Banyak klausa dipetakan satu per satu dengan node. Untuk beberapa klausa, ada beberapa opsi untuk node, yang diputuskan berdasarkan perhitungan biaya data yang mendasarinya.