Salah satu persyaratan utama untuk basis data apa pun adalah mencapai skalabilitas. Hal itu hanya dapat dicapai jika pertentangan (locking) diminimalisir sebanyak mungkin, jika tidak dihilangkan secara bersama-sama. Karena membaca/menulis/memperbarui/menghapus menjadi beberapa operasi utama yang sering terjadi di database, jadi sangat penting agar operasi ini berjalan secara bersamaan tanpa diblokir. Untuk mencapai hal ini, sebagian besar database utama menggunakan model konkurensi yang disebut Kontrol Konkurensi Multi-Versi, yang mengurangi pertengkaran ke tingkat minimum.
Apa itu MVCC
Kontrol Konkurensi Multi Versi (di sini dan seterusnya MVCC) adalah algoritme untuk menyediakan kontrol konkurensi yang baik dengan mempertahankan beberapa versi dari objek yang sama sehingga operasi BACA dan TULIS tidak bertentangan. Di sini MENULIS berarti UPDATE dan DELETE, karena catatan yang baru DIMASUKKAN akan dilindungi sesuai tingkat isolasi. Setiap operasi MENULIS menghasilkan versi baru dari objek dan setiap operasi membaca bersamaan membaca versi objek yang berbeda tergantung pada tingkat isolasi. Karena membaca dan menulis keduanya beroperasi pada versi berbeda dari objek yang sama, maka tidak satu pun dari operasi ini yang diperlukan untuk mengunci sepenuhnya dan karenanya keduanya dapat beroperasi secara bersamaan. Satu-satunya kasus di mana pertikaian masih bisa ada adalah ketika dua transaksi bersamaan mencoba MENULIS catatan yang sama.
Sebagian besar database utama saat ini mendukung MVCC. Maksud dari algoritma ini adalah memelihara beberapa versi dari objek yang sama sehingga implementasi MVCC berbeda dari database ke database hanya dalam hal bagaimana beberapa versi dibuat dan dipelihara. Oleh karena itu, operasi database yang sesuai dan penyimpanan data berubah.
Pendekatan yang paling dikenal untuk mengimplementasikan MVCC adalah yang digunakan oleh PostgreSQL dan Firebird/Interbase dan satu lagi digunakan oleh InnoDB dan Oracle. Di bagian selanjutnya, kita akan membahas secara rinci bagaimana implementasinya di PostgreSQL dan InnoDB.
MVCC Di PostgreSQL
Untuk mendukung beberapa versi, PostgreSQL memelihara bidang tambahan untuk setiap objek (Tuple dalam terminologi PostgreSQL) seperti yang disebutkan di bawah ini:
- xmin – ID Transaksi dari transaksi yang memasukkan atau memperbarui tuple. Dalam kasus UPDATE, versi tuple yang lebih baru akan ditetapkan dengan ID transaksi ini.
- xmax – ID Transaksi dari transaksi yang menghapus atau memperbarui tupel. Dalam kasus UPDATE, versi tuple yang ada saat ini akan diberikan ID transaksi ini. Pada tuple yang baru dibuat, nilai default bidang ini adalah null.
PostgreSQL menyimpan semua data dalam penyimpanan utama yang disebut HEAP (halaman dengan ukuran default 8KB). Semua Tuple baru mendapat xmin sebagai transaksi yang membuatnya dan dan Tuple versi lama (yang diperbarui atau dihapus) ditugaskan dengan xmax. Selalu ada tautan dari tupel versi lama ke versi baru. Tuple versi lama dapat digunakan untuk membuat ulang tuple jika terjadi rollback dan untuk membaca tuple versi lama dengan pernyataan READ tergantung pada tingkat isolasi.
Pertimbangkan ada dua tupel, T1 (dengan nilai 1) dan T2 (dengan nilai 2) untuk sebuah tabel, pembuatan baris baru dapat ditunjukkan dalam 3 langkah di bawah ini:
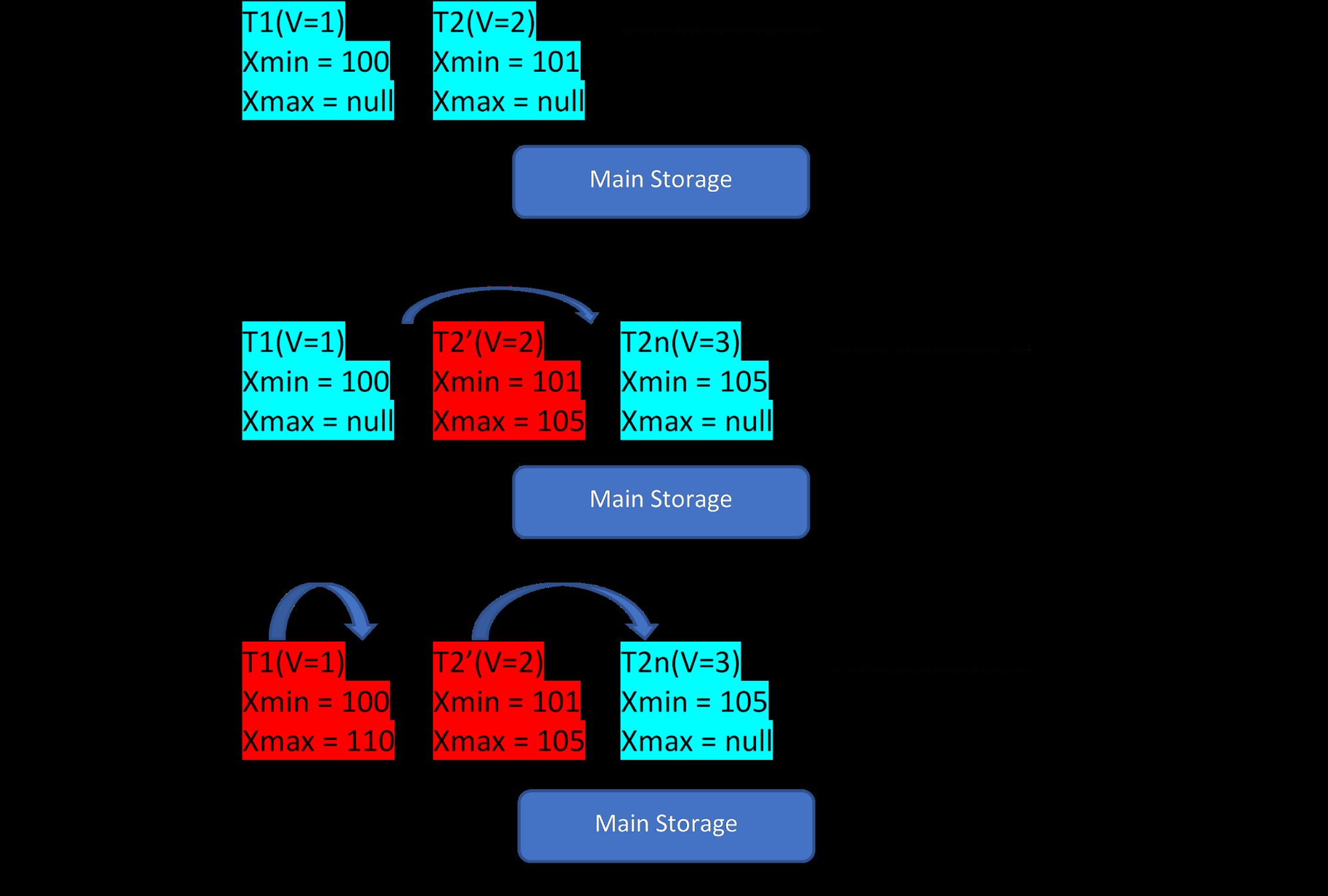 MVCC:Penyimpanan beberapa versi di PostgreSQL
MVCC:Penyimpanan beberapa versi di PostgreSQL Seperti yang terlihat dari gambar, awalnya ada dua tuple dalam database dengan nilai 1 dan 2.
Kemudian, pada langkah kedua, baris T2 dengan nilai 2 diperbarui dengan nilai 3. Pada titik ini, versi baru dibuat dengan nilai baru dan hanya disimpan di sebelah tupel yang ada di area penyimpanan yang sama . Sebelum itu, versi yang lebih lama ditugaskan dengan xmax dan menunjuk ke tupel versi terbaru.
Demikian pula, pada langkah ketiga, ketika baris T1 dengan nilai 1 dihapus, baris yang ada akan dihapus secara virtual (yaitu hanya menetapkan xmax dengan transaksi saat ini) di tempat yang sama. Tidak ada versi baru yang dibuat untuk ini.
Selanjutnya, mari kita lihat bagaimana setiap operasi membuat beberapa versi dan bagaimana tingkat isolasi transaksi dipertahankan tanpa mengunci dengan beberapa contoh nyata. Dalam semua contoh di bawah ini secara default digunakan isolasi “READ COMMITTED”.
MASUKKAN
Setiap kali record dimasukkan, itu akan membuat tuple baru, yang ditambahkan ke salah satu halaman milik tabel yang sesuai.
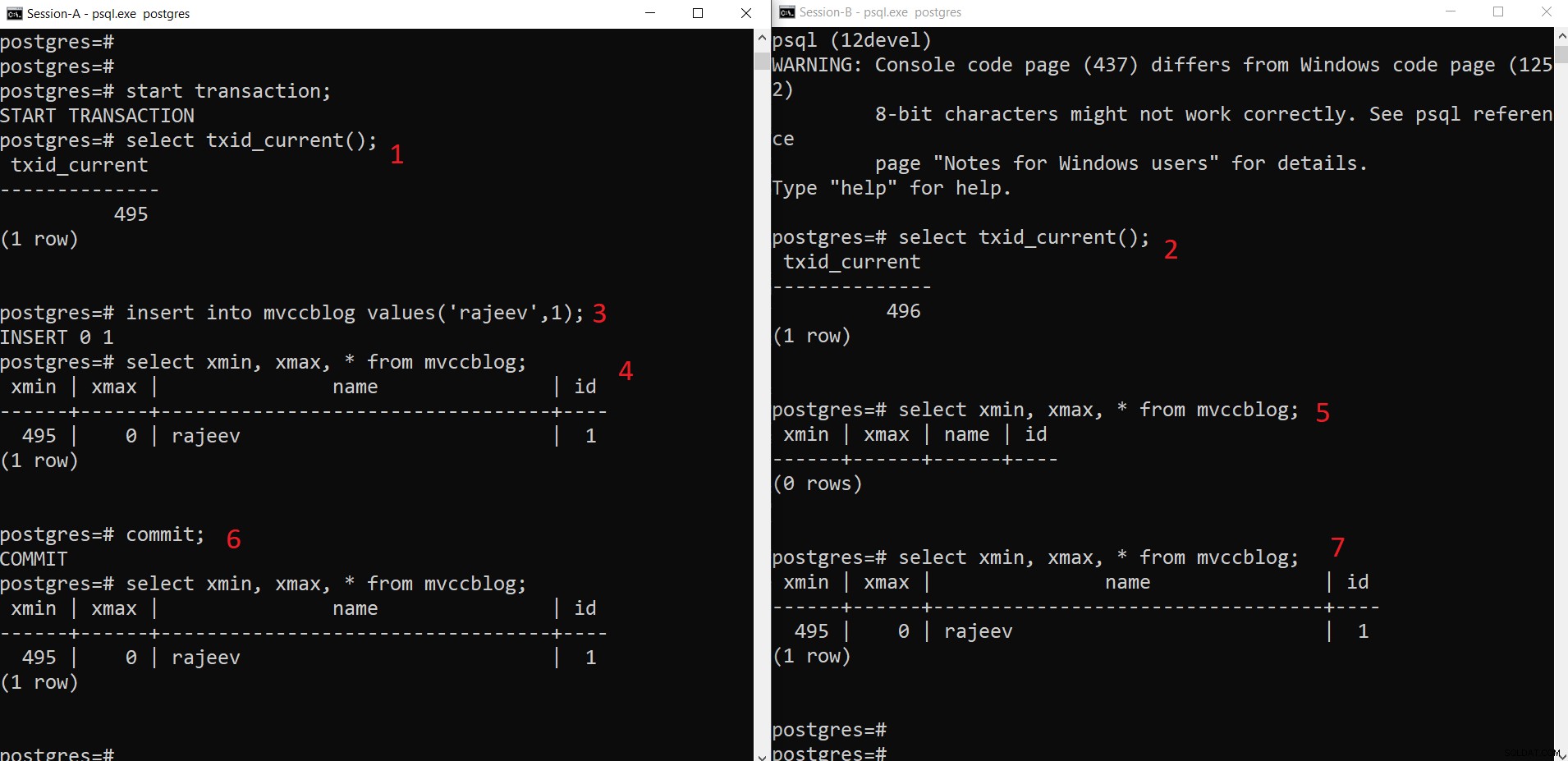 Operasi INSERT bersamaan PostgreSQL
Operasi INSERT bersamaan PostgreSQL Seperti yang dapat kita lihat di sini secara bertahap:
- Sesi-A memulai transaksi dan mendapatkan ID transaksi 495.
- Sesi-B memulai transaksi dan mendapatkan ID transaksi 496.
- Sesi-A menyisipkan tuple baru (disimpan di HEAP)
- Sekarang, tuple baru dengan xmin disetel ke ID transaksi saat ini 495 ditambahkan.
- Tetapi hal yang sama tidak terlihat dari Sesi-B karena xmin (yaitu 495) masih belum dikomit.
- Sekali Berkomitmen.
- Data dapat dilihat oleh kedua sesi.
PERBARUI
PostgreSQL UPDATE bukan pembaruan "IN-PLACE" yaitu tidak mengubah objek yang ada dengan nilai baru yang diperlukan. Sebaliknya, itu menciptakan versi baru dari objek. Jadi, UPDATE secara luas melibatkan langkah-langkah di bawah ini:
- Ini menandai objek saat ini sebagai dihapus.
- Kemudian ia menambahkan versi baru dari objek tersebut.
- Mengalihkan versi objek yang lebih lama ke versi yang baru.
Jadi meskipun sejumlah record tetap sama, HEAP membutuhkan ruang seolah-olah satu record lagi dimasukkan.
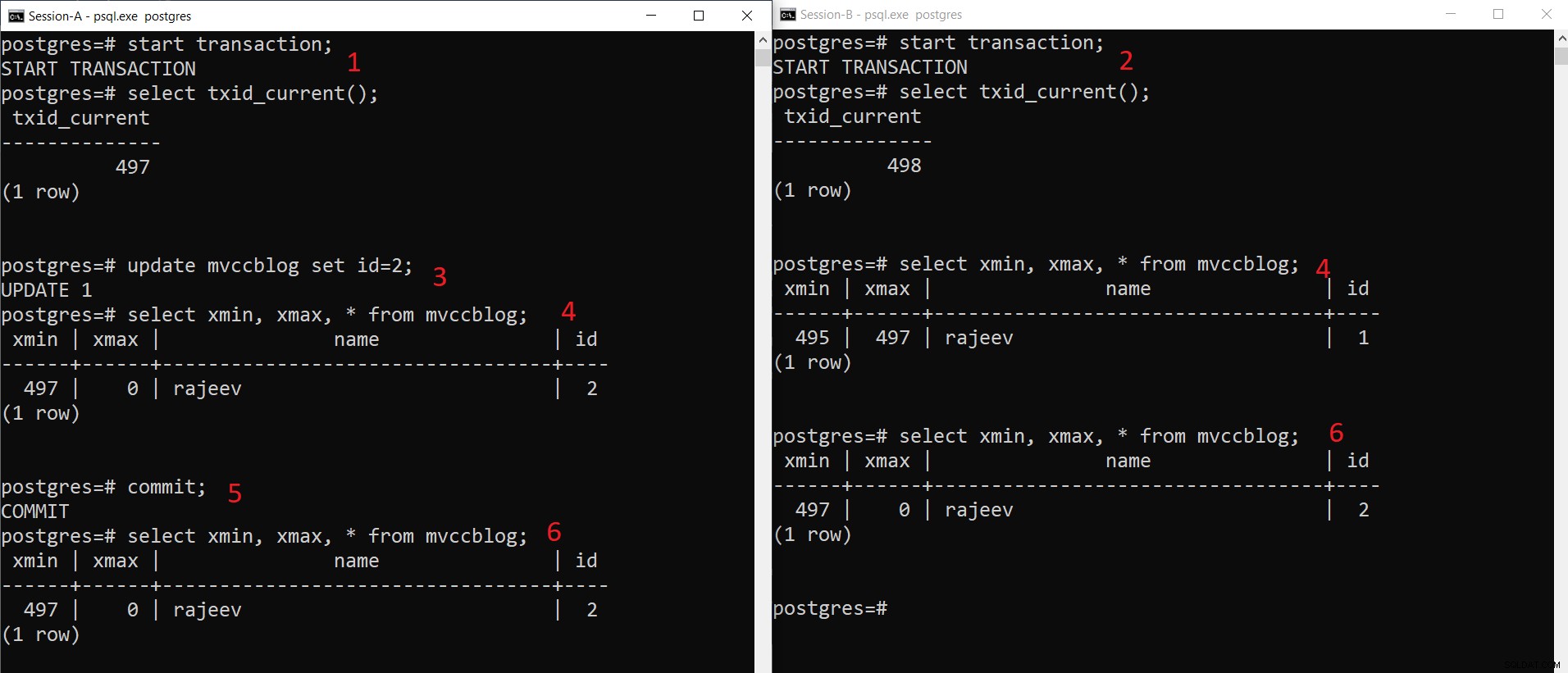 Operasi INSERT bersamaan PostgreSQL
Operasi INSERT bersamaan PostgreSQL Seperti yang dapat kita lihat di sini secara bertahap:
- Sesi-A memulai transaksi dan mendapatkan ID transaksi 497.
- Sesi-B memulai transaksi dan mendapatkan ID transaksi 498.
- Sesi-A memperbarui catatan yang ada.
- Di sini Sesi-A melihat satu versi tuple (tupel yang diperbarui) sedangkan Sesi-B melihat versi lain (Tuple lama tetapi xmax disetel ke 497). Kedua versi tuple disimpan di penyimpanan HEAP (bahkan halaman yang sama tergantung pada ketersediaan ruang)
- Setelah Sesi-A melakukan transaksi, tuple yang lebih lama akan kedaluwarsa karena xmax dari tuple yang lebih lama dilakukan.
- Sekarang kedua sesi melihat versi rekaman yang sama.
HAPUS
Hapus hampir seperti operasi UPDATE kecuali tidak harus menambahkan versi baru. Itu hanya menandai objek saat ini sebagai DELETED seperti yang dijelaskan dalam kasus UPDATE.
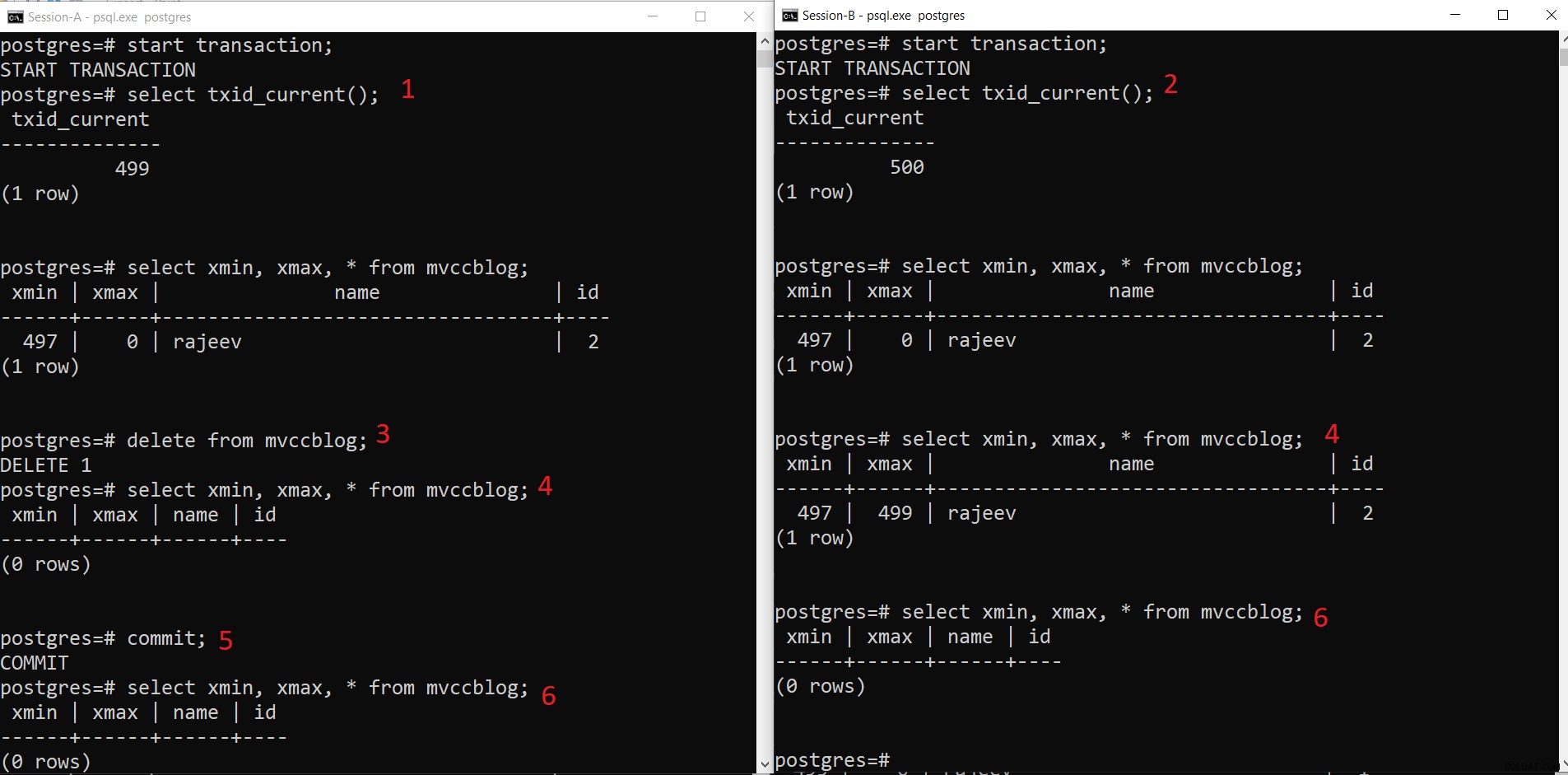 Operasi DELETE PostgreSQL bersamaan
Operasi DELETE PostgreSQL bersamaan - Sesi-A memulai transaksi dan mendapatkan ID transaksi 499.
- Sesi-B memulai transaksi dan mendapatkan ID transaksi 500.
- Sesi-A menghapus rekaman yang ada.
- Di sini Sesi-A tidak melihat tuple apa pun yang dihapus dari transaksi saat ini. Sedangkan Session-B melihat versi tuple yang lebih lama (dengan xmax sebagai 499; transaksi yang menghapus catatan ini).
- Setelah Sesi-A melakukan transaksi, tuple yang lebih lama akan kedaluwarsa karena xmax dari tuple yang lebih lama dilakukan.
- Sekarang kedua sesi tidak melihat tupel yang dihapus.
Seperti yang dapat kita lihat, tidak ada operasi yang menghapus versi objek yang ada secara langsung dan di mana pun diperlukan, ia menambahkan versi tambahan dari objek.
Sekarang, mari kita lihat bagaimana kueri SELECT dieksekusi pada tuple yang memiliki banyak versi:SELECT perlu membaca semua versi tuple hingga menemukan tuple yang sesuai sesuai tingkat isolasi. Misalkan ada Tuple T1, yang diperbarui dan membuat versi baru T1' dan yang pada gilirannya membuat T1'' pada pembaruan:
- Operasi SELECT akan melalui penyimpanan heap untuk tabel ini dan periksa T1 terlebih dahulu. Jika transaksi T1 xmax dilakukan, maka transaksi tersebut akan dipindahkan ke versi berikutnya dari tuple ini.
- Misalkan sekarang T1’ tuple xmax juga di-commit, lalu pindah lagi ke versi berikutnya dari tuple ini.
- Akhirnya, ia menemukan T1'' dan melihat bahwa xmax tidak dikomit (atau nol) dan T1'' xmin terlihat pada transaksi saat ini sesuai tingkat isolasi. Akhirnya, ia akan membaca tupel T1.
Seperti yang dapat kita lihat, tuple perlu melintasi ketiga versi tupel untuk menemukan tupel yang terlihat sesuai hingga tupel yang kedaluwarsa dihapus oleh pengumpul sampah (VACUUM).
MVCC Di InnoDB
Untuk mendukung beberapa versi, InnoDB memelihara bidang tambahan untuk setiap baris seperti yang disebutkan di bawah ini:
- DB_TRX_ID:ID transaksi dari transaksi yang menyisipkan atau memperbarui baris.
- DB_ROLL_PTR:Ini juga disebut penunjuk roll dan menunjuk untuk membatalkan catatan log yang ditulis ke segmen rollback (lebih lanjut tentang ini selanjutnya).
Seperti PostgreSQL, InnoDB juga membuat beberapa versi baris sebagai bagian dari semua operasi tetapi penyimpanan versi yang lebih lama berbeda.
Dalam kasus InnoDB, versi lama dari baris yang diubah disimpan di tablespace/penyimpanan terpisah (disebut undo segment). Jadi tidak seperti PostgreSQL, InnoDB hanya menyimpan baris versi terbaru di area penyimpanan utama dan versi yang lebih lama disimpan di segmen batalkan. Versi baris dari segmen undo digunakan untuk membatalkan operasi jika terjadi rollback dan untuk membaca versi baris yang lebih lama dengan pernyataan READ tergantung pada tingkat isolasi.
Misalkan ada dua baris, T1 (dengan nilai 1) dan T2 (dengan nilai 2) untuk sebuah tabel, pembuatan baris baru dapat ditunjukkan dalam 3 langkah di bawah ini:
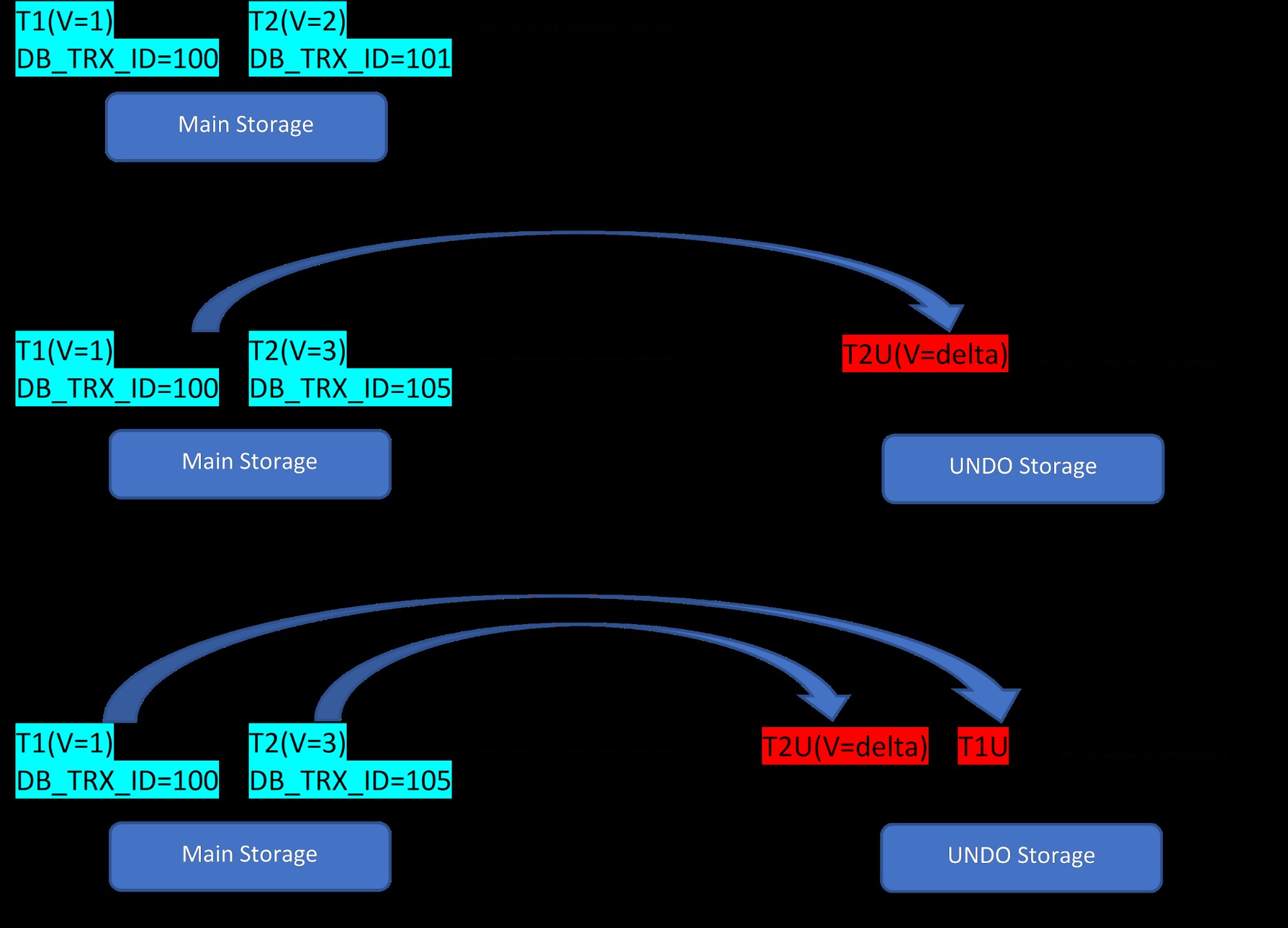 MVCC:Penyimpanan beberapa versi di InnoDB
MVCC:Penyimpanan beberapa versi di InnoDB Seperti yang terlihat dari gambar, awalnya ada dua baris dalam database dengan nilai 1 dan 2.
Kemudian pada tahap kedua, baris T2 dengan nilai 2 diperbarui dengan nilai 3. Pada titik ini, versi baru dibuat dengan nilai baru dan menggantikan versi yang lebih lama. Sebelum itu, versi lama disimpan di segmen undo (perhatikan versi segmen UNDO hanya memiliki nilai delta). Juga, perhatikan bahwa ada satu penunjuk dari versi baru ke versi lama di segmen rollback. Jadi tidak seperti PostgreSQL, pembaruan InnoDB adalah “IN-PLACE”.
Demikian pula, pada langkah ketiga, ketika baris T1 dengan nilai 1 dihapus, maka baris yang ada akan dihapus secara virtual (yaitu hanya menandai bit khusus di baris) di area penyimpanan utama dan versi baru yang sesuai dengan ini akan ditambahkan di segmen Batalkan. Sekali lagi, ada satu roll pointer dari penyimpanan utama ke segmen undo.
Semua operasi berperilaku dengan cara yang sama seperti dalam kasus PostgreSQL jika dilihat dari luar. Hanya penyimpanan internal beberapa versi yang berbeda.
Unduh Whitepaper Hari Ini Pengelolaan &Otomatisasi PostgreSQL dengan ClusterControlPelajari tentang apa yang perlu Anda ketahui untuk menerapkan, memantau, mengelola, dan menskalakan PostgreSQLUnduh WhitepaperMVCC:PostgreSQL vs InnoDB
Sekarang, mari kita analisis apa perbedaan utama antara PostgreSQL dan InnoDB dalam hal implementasi MVCC mereka:
-
Ukuran versi lama
PostgreSQL baru saja memperbarui xmax pada versi tuple yang lebih lama, sehingga ukuran versi yang lebih lama tetap sama dengan catatan yang dimasukkan terkait. Ini berarti jika Anda memiliki 3 versi dari tuple lama, maka semuanya akan memiliki ukuran yang sama (kecuali perbedaan ukuran data aktual jika ada pada setiap pembaruan).
Sedangkan dalam kasus InnoDB, versi objek yang disimpan di segmen Undo biasanya lebih kecil dari catatan yang dimasukkan terkait. Ini karena hanya nilai yang diubah (yaitu diferensial) yang ditulis ke log UNDO.
-
MASUKKAN operasi
InnoDB perlu menulis satu record tambahan di segmen UNDO bahkan untuk INSERT sedangkan PostgreSQL membuat versi baru hanya jika UPDATE.
-
Memulihkan versi lama jika terjadi rollback
PostgreSQL tidak memerlukan sesuatu yang spesifik untuk memulihkan versi yang lebih lama jika terjadi rollback. Ingat versi yang lebih lama memiliki xmax sama dengan transaksi yang memperbarui tuple ini. Jadi, hingga id transaksi ini dikomit, itu dianggap sebagai tupel hidup untuk snapshot bersamaan. Setelah transaksi dibatalkan, transaksi terkait akan secara otomatis dianggap aktif untuk semua transaksi karena transaksi tersebut akan dibatalkan.
Sedangkan dalam kasus InnoDB, secara eksplisit diperlukan untuk membangun kembali versi objek yang lebih lama setelah rollback terjadi.
-
Merebut kembali ruang yang ditempati oleh versi lama
Dalam kasus PostgreSQL, ruang yang ditempati oleh versi yang lebih lama dapat dianggap mati hanya jika tidak ada snapshot paralel untuk membaca versi ini. Setelah versi yang lebih lama mati, maka operasi VACUUM dapat merebut kembali ruang yang ditempati oleh mereka. VACUUM dapat dipicu secara manual atau sebagai tugas latar belakang tergantung pada konfigurasi.
Log UNDO InnoDB dibagi menjadi INSERT UNDO dan UPDATE UNDO. Yang pertama akan dibuang segera setelah transaksi yang sesuai dilakukan. Yang kedua perlu dipertahankan hingga sejajar dengan snapshot lainnya. InnoDB tidak memiliki operasi VACUUM eksplisit tetapi pada baris yang sama memiliki PURGE asinkron untuk membuang log UNDO yang berjalan sebagai tugas latar belakang.
-
Dampak vakum tertunda
Seperti yang telah dibahas pada poin sebelumnya, ada dampak besar dari penundaan vakum dalam kasus PostgreSQL. Ini menyebabkan tabel mulai membengkak dan menyebabkan ruang penyimpanan meningkat meskipun catatan terus-menerus dihapus. Ini juga dapat mencapai titik di mana VAKUM PENUH perlu dilakukan yang merupakan operasi yang sangat mahal.
-
Pemindaian berurutan jika tabel membengkak
Pemindaian sekuensial PostgreSQL harus melintasi semua versi objek yang lebih lama meskipun semuanya mati (sampai dihapus menggunakan vakum). Ini adalah masalah khas dan paling banyak dibicarakan di PostgreSQL. Ingat PostgreSQL menyimpan semua versi tuple dalam penyimpanan yang sama.
Sedangkan dalam kasus InnoDB, tidak perlu membaca Undo record kecuali diperlukan. Jika semua record undo sudah mati, maka hanya cukup untuk membaca semua objek versi terbaru.
-
Indeks
PostgreSQL menyimpan indeks dalam penyimpanan terpisah yang menyimpan satu tautan ke data aktual di HEAP. Jadi PostgreSQL harus memperbarui bagian INDEX juga meskipun tidak ada perubahan di INDEX. Meskipun kemudian masalah ini diperbaiki dengan menerapkan pembaruan HOT (Heap Only Tuple) tetapi masih memiliki batasan bahwa jika heap tuple baru tidak dapat ditampung di halaman yang sama, maka mundur ke UPDATE normal.
InnoDB tidak memiliki masalah ini karena mereka menggunakan indeks berkerumun.
Kesimpulan
PostgreSQL MVCC memiliki beberapa kelemahan terutama dalam hal penyimpanan yang membengkak jika beban kerja Anda sering UPDATE/DELETE. Jadi, jika Anda memutuskan untuk menggunakan PostgreSQL, Anda harus sangat berhati-hati dalam mengonfigurasi VACUUM dengan bijak.
Komunitas PostgreSQL juga telah mengakui ini sebagai masalah besar dan mereka telah mulai mengerjakan pendekatan MVCC berbasis UNDO (nama sementara sebagai ZHEAP) dan kita mungkin melihat hal yang sama di rilis mendatang.



