Apakah Anda bertanya-tanya apa itu skema Postgresql dan mengapa itu penting dan bagaimana Anda dapat menggunakan skema untuk membuat implementasi database Anda lebih kuat dan dapat dipelihara? Artikel ini akan memperkenalkan dasar-dasar skema di Postgresql dan menunjukkan kepada Anda cara membuatnya dengan beberapa contoh dasar. Artikel mendatang akan membahas contoh cara mengamankan dan menggunakan skema untuk aplikasi nyata.
Pertama, untuk menjernihkan potensi kebingungan terminologi, mari kita pahami bahwa di dunia Postgresql, istilah "skema" mungkin agak kelebihan beban. Dalam konteks yang lebih luas dari sistem manajemen basis data relasional (RDBMS), istilah "skema" dapat dipahami untuk merujuk pada desain logis atau fisik keseluruhan dari basis data, yaitu definisi semua tabel, kolom, tampilan, dan objek lainnya. yang merupakan definisi database. Dalam konteks yang lebih luas itu, sebuah skema dapat diekspresikan dalam diagram hubungan entitas (ER) atau skrip pernyataan bahasa definisi data (DDL) yang digunakan untuk membuat instance database aplikasi.
Di dunia Postgresql, istilah "skema" mungkin lebih baik dipahami sebagai "ruang nama". Faktanya, dalam tabel sistem Postgresql, skema dicatat dalam kolom tabel yang disebut "ruang nama", yang, IMHO, adalah terminologi yang lebih akurat. Praktisnya, setiap kali saya melihat "skema" dalam konteks Postgresql, saya diam-diam menafsirkannya kembali sebagai "ruang nama".
Tetapi Anda mungkin bertanya:“Apa itu ruang nama?” Umumnya, ruang nama adalah sarana yang agak fleksibel untuk mengatur dan mengidentifikasi informasi berdasarkan nama. Sebagai contoh, bayangkan dua rumah tangga tetangga, Smiths, Alice dan Bob, dan Jones, Bob dan Cathy (lih. Gambar 1). Jika kami hanya menggunakan nama depan, mungkin akan membingungkan orang yang kami maksud ketika berbicara tentang Bob. Tetapi dengan menambahkan nama keluarga, Smith atau Jones, kami secara unik mengidentifikasi orang yang kami maksud.
Seringkali, ruang nama diatur dalam hierarki bersarang. Hal ini memungkinkan klasifikasi yang efisien dari sejumlah besar informasi ke dalam struktur yang sangat halus, seperti, misalnya sistem nama domain internet. Di tingkat atas, “.com”, “.net”, “.org”, “.edu”, dan lain-lain menentukan ruang nama luas di mana nama terdaftar untuk entitas tertentu, jadi misalnya, “severalnines.com” dan "postgresql.org" didefinisikan secara unik. Namun di bawah masing-masing subdomain tersebut terdapat sejumlah subdomain umum seperti “www”, “mail”, dan “ftp”, misalnya, yang merupakan duplikat, tetapi dalam ruang nama masing-masing adalah unik.
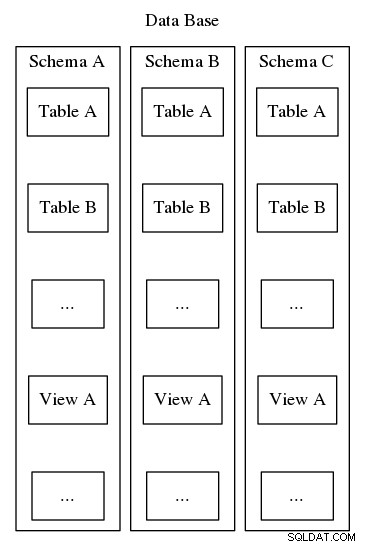
Skema Postgresql melayani tujuan yang sama untuk mengatur dan mengidentifikasi, namun, tidak seperti contoh kedua di atas, skema Postgresql tidak dapat disarangkan dalam hierarki. Sementara database mungkin berisi banyak skema, hanya ada satu tingkat dan dalam database, nama skema harus unik. Juga, setiap database harus menyertakan setidaknya satu skema. Setiap kali database baru dipakai, skema default bernama "publik" dibuat. Isi skema mencakup semua objek database lain seperti tabel, tampilan, prosedur tersimpan, pemicu, dan lain-lain. Untuk memvisualisasikannya, lihat Gambar 2, yang menggambarkan sarang seperti boneka matryoshka yang menunjukkan di mana skema masuk ke dalam struktur a Basis data Postgresql.
Selain hanya mengatur objek database ke dalam kelompok logis untuk membuatnya lebih mudah dikelola, skema melayani tujuan praktis untuk menghindari tabrakan nama. Salah satu paradigma operasional melibatkan mendefinisikan skema untuk setiap pengguna database sehingga memberikan beberapa derajat isolasi, ruang di mana pengguna dapat menentukan tabel dan tampilan mereka sendiri tanpa mengganggu satu sama lain. Pendekatan lain adalah menginstal alat pihak ketiga atau ekstensi basis data dalam skema individu untuk menjaga semua komponen terkait secara logis bersama-sama. Artikel selanjutnya dalam seri ini akan merinci pendekatan baru untuk desain aplikasi yang kuat, menggunakan skema sebagai sarana tipuan untuk membatasi paparan desain fisik database dan sebagai gantinya menyajikan antarmuka pengguna yang menyelesaikan kunci sintetis dan memfasilitasi pemeliharaan jangka panjang dan manajemen konfigurasi saat persyaratan sistem berkembang.
Ayo buat kode!
Unduh Whitepaper Hari Ini Pengelolaan &Otomatisasi PostgreSQL dengan ClusterControlPelajari tentang apa yang perlu Anda ketahui untuk menerapkan, memantau, mengelola, dan menskalakan PostgreSQLUnduh WhitepaperPerintah paling sederhana untuk membuat skema dalam database adalah
CREATE SCHEMA hollywood;Perintah ini memerlukan hak istimewa buat dalam database, dan skema "hollywood" yang baru dibuat akan dimiliki oleh pengguna yang menjalankan perintah tersebut. Permintaan yang lebih kompleks dapat mencakup elemen opsional yang menentukan pemilik yang berbeda, dan bahkan mungkin menyertakan pernyataan DDL yang membuat objek basis data dalam skema semuanya dalam satu perintah!
Format umumnya adalah
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]di mana "nama pengguna" adalah siapa yang akan memiliki skema dan "schema_element" mungkin merupakan salah satu dari perintah DDL tertentu (lihat dokumentasi Postgresql untuk spesifiknya). Hak istimewa pengguna super diperlukan untuk menggunakan opsi OTORISASI.
Jadi misalnya, untuk membuat skema bernama "hollywood" yang berisi tabel bernama "film" dan tampilan bernama "pemenang" dalam satu perintah, Anda bisa melakukan
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Objek database tambahan selanjutnya dapat dibuat secara langsung, misalnya tabel tambahan akan ditambahkan ke skema dengan
CREATE TABLE hollywood.actors (name text, dob date, gender text);Perhatikan pada contoh di atas awalan nama tabel dengan nama skema. Ini diperlukan karena secara default, yaitu tanpa spesifikasi skema eksplisit, objek database baru dibuat dalam skema apa pun saat ini, yang akan kita bahas selanjutnya.
Ingat bagaimana dalam contoh ruang nama depan di atas, kami memiliki dua orang bernama Bob, dan kami menjelaskan cara menghilangkan konflik atau membedakan mereka dengan memasukkan nama keluarga. Tetapi di dalam masing-masing rumah tangga Smith dan Jones secara terpisah, setiap keluarga memahami "Bob" untuk merujuk pada salah satu yang pergi dengan rumah tangga tertentu. Jadi misalnya dalam konteks rumah tangga masing-masing, Alice tidak perlu memanggil suaminya sebagai Bob Jones, dan Cathy tidak perlu menyebut suaminya sebagai Bob Smith:mereka masing-masing cukup mengatakan “Bob”.
Skema Postgresql saat ini seperti rumah tangga pada contoh di atas. Objek dalam skema saat ini dapat direferensikan tanpa pengecualian, tetapi merujuk ke objek bernama serupa di skema lain memerlukan kualifikasi nama dengan mengawali nama skema seperti di atas.
Skema saat ini berasal dari parameter konfigurasi "search_path". Parameter ini menyimpan daftar nama skema yang dipisahkan koma dan dapat diperiksa dengan perintah
SHOW search_path;atau setel ke nilai baru dengan
SET search_path TO schema [, schema, ...];Nama skema pertama dalam daftar adalah "skema saat ini" dan merupakan tempat objek baru dibuat jika ditentukan tanpa kualifikasi nama skema.
Daftar nama skema yang dipisahkan koma juga berfungsi untuk menentukan urutan pencarian yang digunakan sistem untuk menemukan objek bernama yang tidak memenuhi syarat yang ada. Misalnya, kembali ke lingkungan Smith dan Jones, pengiriman paket yang ditujukan hanya kepada "Bob" akan membutuhkan kunjungan ke setiap rumah tangga sampai penduduk pertama bernama "Bob" ditemukan. Catatan, ini mungkin bukan penerima yang dimaksud. Logika yang sama berlaku untuk Postgresql. Sistem mencari tabel, tampilan, dan objek lain dalam skema dalam urutan jalur_pencarian, lalu objek pencocokan nama yang pertama kali ditemukan digunakan. Objek bernama yang memenuhi syarat skema digunakan secara langsung tanpa referensi ke search_path.
Dalam konfigurasi default, kueri variabel konfigurasi search_path mengungkapkan nilai ini
SHOW search_path;
Search_path
--------------
"$user", publicSistem menafsirkan nilai pertama yang ditunjukkan di atas sebagai nama pengguna yang masuk saat ini dan mengakomodasi kasus penggunaan yang disebutkan sebelumnya di mana setiap pengguna dialokasikan skema nama pengguna untuk ruang kerja yang terpisah dari pengguna lain. Jika tidak ada skema nama pengguna yang telah dibuat, entri tersebut akan diabaikan dan skema "publik" menjadi skema saat ini tempat objek baru dibuat.
Jadi, kembali ke contoh kita sebelumnya dalam membuat tabel “hollywood.actors”, jika kita tidak mengkualifikasikan nama tabel dengan nama skema, maka tabel akan dibuat dalam skema publik. Jika kita mengantisipasi membuat semua objek dalam skema tertentu, maka akan lebih mudah untuk mengatur variabel search_path seperti
SET search_path TO hollywood,public;memfasilitasi pengetikan singkatan nama yang tidak memenuhi syarat untuk membuat atau mengakses objek database.
Ada juga fungsi informasi sistem yang mengembalikan skema saat ini dengan kueri
select current_schema();Dalam kasus ejaan yang tidak tepat, pemilik skema dapat mengubah nama, asalkan pengguna juga telah membuat hak istimewa untuk database, dengan
ALTER SCHEMA old_name RENAME TO new_name;Dan terakhir, untuk menghapus skema dari database, ada perintah drop
DROP SCHEMA schema_name;Perintah DROP akan gagal jika skema berisi objek apa pun, jadi objek tersebut harus dihapus terlebih dahulu, atau Anda dapat menghapus skema secara rekursif semua isinya dengan opsi CASCADE
DROP SCHEMA schema_name CASCADE;Dasar-dasar ini akan membantu Anda memahami skema!



