TeamCity adalah integrasi berkelanjutan dan server pengiriman berkelanjutan yang dibangun di Java. Ini tersedia sebagai layanan cloud dan lokal. Seperti yang dapat Anda bayangkan, integrasi berkelanjutan dan alat pengiriman sangat penting untuk pengembangan perangkat lunak, dan ketersediaannya tidak boleh terpengaruh. Untungnya, TeamCity dapat diterapkan dalam mode Sangat Tersedia.
Pos blog ini akan membahas persiapan dan penerapan lingkungan yang sangat tersedia untuk TeamCity.
Lingkungan
TeamCity terdiri dari beberapa elemen. Ada aplikasi Java dan database yang mendukungnya. Itu juga menggunakan agen yang berkomunikasi dengan instance TeamCity utama. Deployment yang sangat tersedia terdiri dari beberapa instance TeamCity, di mana satu bertindak sebagai primer, dan yang lainnya sekunder. Instance tersebut berbagi akses ke database dan direktori data yang sama. Skema yang bermanfaat tersedia di halaman dokumentasi TeamCity, seperti yang ditunjukkan di bawah ini:

Seperti yang kita lihat, ada dua elemen bersama — direktori data dan data. Kita harus memastikan bahwa itu juga sangat tersedia. Ada berbagai opsi yang dapat Anda gunakan untuk membuat dudukan bersama; namun, kami akan menggunakan GlusterFS. Untuk database, kami akan menggunakan salah satu sistem manajemen database relasional yang didukung — PostgreSQL, dan kami akan menggunakan ClusterControl untuk membangun tumpukan ketersediaan tinggi yang berbasis di sekitarnya.
Cara Mengonfigurasi GlusterFS
Mari kita mulai dengan dasar-dasarnya. Kami ingin mengonfigurasi nama host dan /etc/hosts pada node TeamCity kami, tempat kami juga akan menerapkan GlusterFS. Untuk melakukan itu, kita perlu menyiapkan repositori untuk paket GlusterFS terbaru di semuanya:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateKemudian kita dapat menginstal GlusterFS di semua node TeamCity kami:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS menggunakan port 24007 untuk konektivitas antar node; kita harus memastikan bahwa itu terbuka dan dapat diakses oleh semua node.
Setelah konektivitas terpasang, kita dapat membuat cluster GlusterFS dengan menjalankan dari satu node:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Sekarang, kita dapat menguji seperti apa statusnya:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Sepertinya semuanya baik-baik saja dan konektivitasnya tersedia.
Selanjutnya, kita harus menyiapkan perangkat blok yang akan digunakan oleh GlusterFS. Ini harus dijalankan pada semua node. Pertama, buat partisi:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Kemudian, format partisi tersebut:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Akhirnya, di semua node, kita perlu membuat direktori yang akan digunakan untuk memasang partisi dan mengedit fstab untuk memastikannya akan dipasang saat startup:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabMari kita verifikasi sekarang apakah ini berfungsi:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Sekarang kita dapat menggunakan salah satu node untuk membuat dan memulai volume GlusterFS:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successHarap diperhatikan bahwa kami menggunakan nilai '3' untuk jumlah replika. Artinya, setiap volume akan ada dalam tiga salinan. Dalam kasus kami, setiap brick, setiap volume /dev/sdb1 di semua node akan berisi semua data.
Setelah volume dimulai, kami dapat memverifikasi statusnya:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksSeperti yang Anda lihat, semuanya terlihat baik-baik saja. Yang penting adalah GlusterFS memilih port 49152 untuk mengakses volume tersebut, dan kami harus memastikan port tersebut dapat dijangkau di semua node tempat kami akan memasangnya.
Langkah selanjutnya adalah menginstal paket klien GlusterFS. Untuk contoh ini, kita perlu menginstalnya di node yang sama dengan server GlusterFS:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Selanjutnya, kita perlu membuat direktori di semua node untuk digunakan sebagai direktori data bersama untuk TeamCity. Ini harus terjadi di semua node:
example@sqldat.com:~# sudo mkdir /teamcity-storageTerakhir, pasang volume GlusterFS di semua node:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageIni menyelesaikan persiapan penyimpanan bersama.
Membangun Cluster PostgreSQL yang Sangat Tersedia
Setelah penyiapan penyimpanan bersama untuk TeamCity selesai, kami sekarang dapat membangun infrastruktur basis data kami yang sangat tersedia. TeamCity dapat menggunakan database yang berbeda; namun, kami akan menggunakan PostgreSQL di blog ini. Kami akan memanfaatkan ClusterControl untuk menerapkan dan kemudian mengelola lingkungan database.
Panduan TeamCity untuk membangun penerapan multi-node sangat membantu, tetapi tampaknya mengabaikan ketersediaan tinggi dari segala sesuatu selain TeamCity. Panduan TeamCity menyarankan server NFS atau SMB untuk penyimpanan data, yang, dengan sendirinya, tidak memiliki redundansi dan akan menjadi satu titik kegagalan. Kami telah mengatasi ini dengan menggunakan GlusterFS. Mereka menyebutkan database bersama, karena node database tunggal jelas tidak menyediakan ketersediaan tinggi. Kita harus membangun tumpukan yang tepat:

Dalam kasus kami. itu akan terdiri dari tiga node PostgreSQL, satu primer, dan dua replika. Kami akan menggunakan HAProxy sebagai penyeimbang beban dan menggunakan Keepalive untuk mengelola IP Virtual untuk menyediakan satu titik akhir bagi aplikasi untuk terhubung. ClusterControl akan menangani kegagalan dengan memantau topologi replikasi dan melakukan pemulihan yang diperlukan sesuai kebutuhan, seperti memulai ulang proses yang gagal atau gagal ke salah satu replika jika node utama mati.
Untuk memulai, kami akan menerapkan node database. Harap diingat bahwa ClusterControl memerlukan konektivitas SSH dari node ClusterControl ke semua node yang dikelolanya.

Kemudian, kami memilih pengguna yang akan kami gunakan untuk terhubung ke database, kata sandinya, dan versi PostgreSQL yang akan digunakan:

Selanjutnya, kita akan menentukan node mana yang akan digunakan untuk menerapkan PostgreSQL :
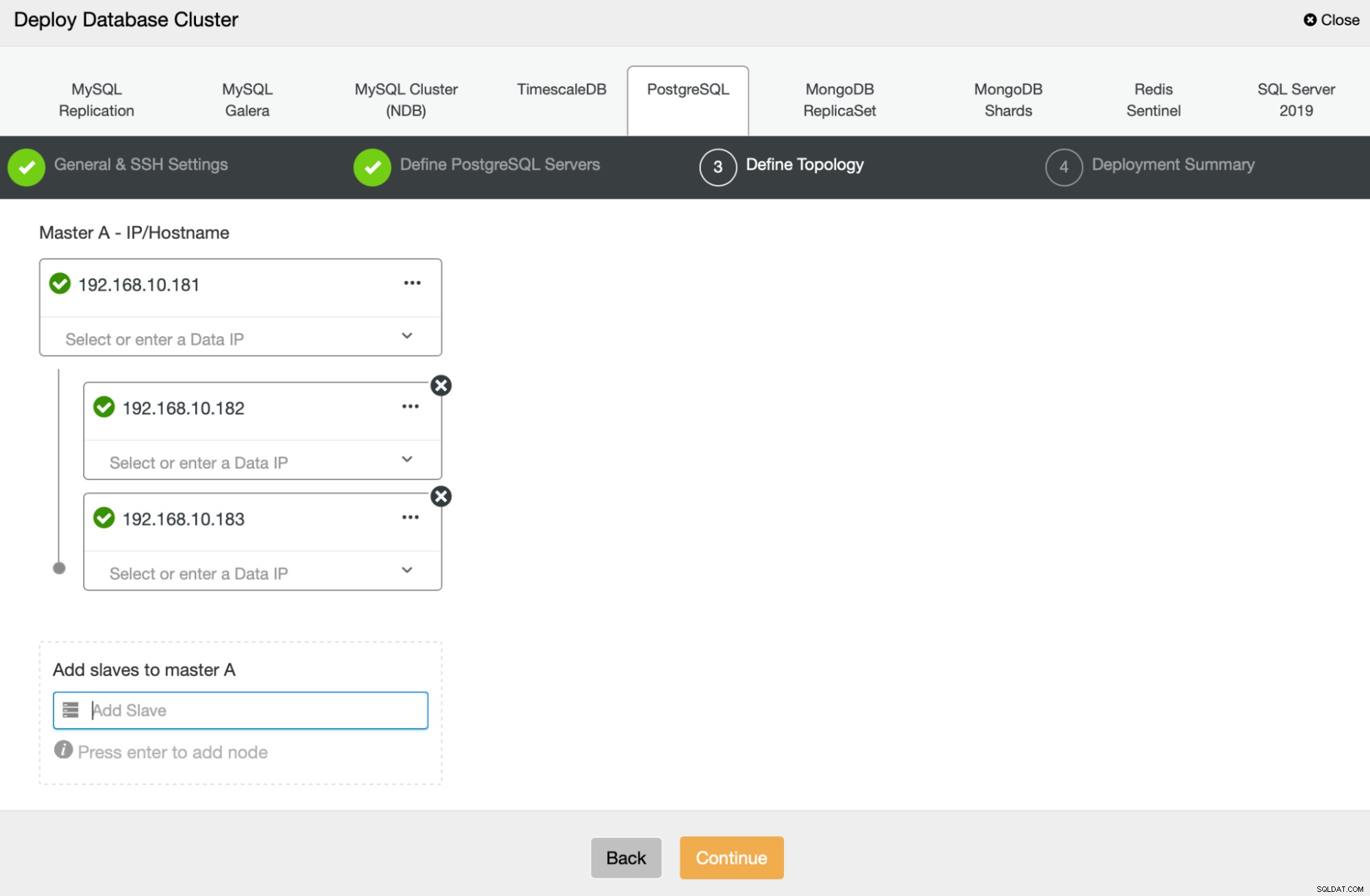
Terakhir, kita dapat menentukan apakah node harus menggunakan replikasi asinkron atau sinkron. Perbedaan utama antara keduanya adalah replikasi sinkron memastikan bahwa setiap transaksi yang dijalankan pada node utama akan selalu direplikasi pada replika. Namun, replikasi sinkron juga memperlambat komit. Sebaiknya aktifkan replikasi sinkron untuk daya tahan terbaik, tetapi Anda harus memverifikasi nanti jika kinerjanya dapat diterima.

Setelah kita mengeklik “Terapkan”, tugas penerapan akan dimulai. Kami dapat memantau kemajuannya di tab Aktivitas di UI ClusterControl. Pada akhirnya kita akan melihat bahwa tugas telah selesai dan cluster berhasil diterapkan.

Terapkan instans HAProxy dengan membuka Kelola -> Muat penyeimbang. Pilih HAProxy sebagai penyeimbang beban dan isi formulirnya. Pilihan yang paling penting adalah di mana Anda ingin menerapkan HAProxy. Kami menggunakan node database dalam kasus ini, tetapi dalam lingkungan produksi, kemungkinan besar Anda ingin memisahkan load balancer dari instans database. Selanjutnya, pilih node PostgreSQL mana yang akan disertakan dalam HAProxy. Kami menginginkan semuanya.

Sekarang penerapan HAProxy akan dimulai. Kami ingin mengulanginya setidaknya sekali lagi untuk membuat dua instance HAProxy untuk redundansi. Dalam penerapan ini, kami memutuskan untuk menggunakan tiga penyeimbang beban HAProxy. Di bawah ini adalah tangkapan layar layar pengaturan saat mengonfigurasi penerapan HAProxy kedua:
Ketika semua instance HAProxy kami aktif dan berjalan, kami dapat menerapkan Keepalive . Idenya di sini adalah bahwa Keepalive akan ditempatkan dengan HAProxy dan memantau proses HAProxy. Salah satu instance dengan HAProxy yang berfungsi akan memiliki IP Virtual yang ditetapkan. VIP ini harus digunakan oleh aplikasi untuk terhubung ke database. Keepalived akan mendeteksi jika HAProxy tersebut menjadi tidak tersedia dan pindah ke instance HAProxy lain yang tersedia.
Wizard penerapan mengharuskan kami untuk meneruskan instance HAProxy yang ingin kami tetap pantau. Kami juga harus memberikan alamat IP dan antarmuka jaringan untuk VIP.

Langkah terakhir dan terakhir adalah membuat database untuk TeamCity:

Dengan ini, kami telah menyimpulkan penyebaran cluster PostgreSQL yang sangat tersedia.
Menerapkan TeamCity sebagai Multi-node
Langkah selanjutnya adalah men-deploy TeamCity di lingkungan multi-node. Kami akan menggunakan tiga node TeamCity. Pertama, kita harus menginstal Java JRE dan JDK yang sesuai dengan persyaratan TeamCity.
apt install default-jre default-jdkSekarang, di semua node, kita harus mengunduh TeamCity. Kami akan menginstal di direktori lokal, bukan direktori bersama.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzKemudian kita dapat memulai TeamCity di salah satu node:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logSetelah TeamCity dimulai, kita dapat mengakses UI dan memulai penerapan. Awalnya, kita harus melewati lokasi direktori data. Ini adalah volume bersama yang kami buat di GlusterFS.

Selanjutnya, pilih database. Kita akan menggunakan cluster PostgreSQL yang telah kita buat.

Unduh dan instal driver JDBC:

Selanjutnya, isi detail akses. Kami akan menggunakan IP virtual yang disediakan oleh Keepalive. Harap dicatat bahwa kami menggunakan port 5433. Ini adalah port yang digunakan untuk backend baca/tulis HAProxy; itu akan selalu mengarah ke simpul utama yang aktif. Selanjutnya, pilih pengguna dan database yang akan digunakan dengan TeamCity.

Setelah ini selesai, TeamCity akan mulai menginisialisasi struktur database.

Setuju dengan Perjanjian Lisensi:

Terakhir, buat pengguna untuk TeamCity:

Itu dia! Kita sekarang seharusnya dapat melihat GUI TeamCity:

Sekarang, kita harus menyiapkan TeamCity dalam mode multi-simpul. Pertama, kita harus mengedit skrip startup di semua node:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shKita harus memastikan bahwa dua variabel berikut diekspor. Harap verifikasi bahwa Anda menggunakan nama host, IP, dan direktori yang benar untuk penyimpanan lokal dan bersama:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Setelah ini selesai, Anda dapat memulai node yang tersisa:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startAnda akan melihat output berikut di Administrasi -> Konfigurasi Node:Satu node utama dan dua node siaga.

Harap diingat bahwa failover di TeamCity tidak otomatis. Jika node utama berhenti bekerja, Anda harus terhubung ke salah satu node sekunder. Untuk melakukannya, buka "Konfigurasi Node" dan promosikan ke node “Utama”. Dari layar login, Anda akan melihat indikasi yang jelas bahwa ini adalah node sekunder:

Dalam "Konfigurasi Node", Anda akan melihat bahwa satu node memiliki dijatuhkan dari kluster:

Anda akan menerima pesan yang menyatakan bahwa Anda tidak dapat menulis ke node ini. Jangan khawatir; penulisan yang diperlukan untuk mempromosikan simpul ini ke status "utama" akan berfungsi dengan baik:

Klik "Aktifkan", dan kami telah berhasil mempromosikan simpul TimeCity sekunder:

Ketika node1 tersedia dan TeamCity dimulai lagi pada node itu, kami akan melihatnya bergabung kembali dengan cluster:

Jika Anda ingin meningkatkan kinerja lebih lanjut, Anda dapat menggunakan HAProxy + Keepalive di depan UI TeamCity untuk menyediakan satu titik masuk ke GUI. Anda dapat menemukan detail tentang mengonfigurasi HAProxy untuk TeamCity di dokumentasi.
Menutup
Seperti yang Anda lihat, menerapkan TeamCity untuk ketersediaan tinggi tidak terlalu sulit — sebagian besar telah dibahas secara menyeluruh dalam dokumentasi. Jika Anda mencari cara untuk mengotomatiskan beberapa hal ini dan menambahkan backend database yang sangat tersedia, pertimbangkan untuk mengevaluasi ClusterControl gratis selama 30 hari. ClusterControl dapat dengan cepat menerapkan dan memantau backend, menyediakan failover otomatis, pemulihan, pemantauan, manajemen pencadangan, dan banyak lagi.
Untuk kiat lebih lanjut tentang alat pengembangan perangkat lunak dan praktik terbaik, lihat cara mendukung tim DevOps Anda dengan kebutuhan database mereka.
Untuk mendapatkan berita terbaru dan praktik terbaik untuk mengelola infrastruktur basis data berbasis sumber terbuka, jangan lupa untuk mengikuti kami di Twitter atau LinkedIn dan berlangganan buletin kami. Sampai jumpa lagi!