Bagian yang selalu saya temukan membingungkan adalah biaya awal vs total biaya. Saya Google ini setiap kali saya melupakannya, yang membawa saya kembali ke sini, yang tidak menjelaskan perbedaannya, itulah sebabnya saya menulis jawaban ini. Inilah yang saya peroleh dari EXPLAIN Postgres dokumentasi, dijelaskan seperti yang saya pahami.
Berikut ini contoh dari aplikasi yang mengelola forum:
EXPLAIN SELECT * FROM post LIMIT 50;
Limit (cost=0.00..3.39 rows=50 width=422)
-> Seq Scan on post (cost=0.00..15629.12 rows=230412 width=422)
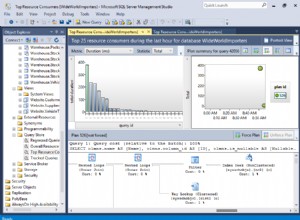
Berikut penjelasan grafis dari PgAdmin:

(Saat Anda menggunakan PgAdmin, Anda dapat mengarahkan mouse ke komponen untuk membaca detail biaya.)
Biaya direpresentasikan sebagai tupel, mis. biaya LIMIT adalah cost=0.00..3.39 dan biaya pemindaian berurutan post adalah cost=0.00..15629.12 . Angka pertama dalam tupel adalah biaya awal dan angka kedua adalah total biaya . Karena saya menggunakan EXPLAIN dan bukan EXPLAIN ANALYZE , biaya ini merupakan perkiraan, bukan ukuran sebenarnya.
- Biaya permulaan adalah konsep yang rumit. Itu tidak hanya mewakili jumlah waktu sebelum komponen itu dimulai . Ini menunjukkan jumlah waktu antara saat komponen mulai dieksekusi (membaca data) dan saat komponen mengeluarkan baris pertamanya .
- Total biaya adalah seluruh waktu eksekusi komponen, mulai dari mulai membaca data hingga selesai menulis outputnya.
Sebagai komplikasi, setiap biaya simpul "induk" mencakup biaya simpul turunannya. Dalam representasi teks, pohon diwakili oleh lekukan, mis. LIMIT adalah simpul induk dan Seq Scan adalah anaknya. Dalam representasi PgAdmin, panah menunjuk dari anak ke induk — arah aliran data — yang mungkin berlawanan dengan intuisi jika Anda terbiasa dengan teori graf.
Dokumentasi mengatakan bahwa biaya sudah termasuk semua node anak, tetapi perhatikan bahwa total biaya induk 3.39 jauh lebih kecil dari total biaya anaknya 15629.12 . Biaya total tidak termasuk karena komponen seperti LIMIT tidak perlu memproses seluruh inputnya. Lihat EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000 LIMIT 2; contoh di Postgres EXPLAIN dokumentasi.
Dalam contoh di atas, waktu mulai adalah nol untuk kedua komponen, karena tidak ada komponen yang perlu melakukan pemrosesan apa pun sebelum mulai menulis baris:pemindaian berurutan membaca baris pertama tabel dan memancarkannya. LIMIT membaca baris pertama dan kemudian memancarkannya.
Kapan suatu komponen perlu melakukan banyak pemrosesan sebelum dapat mulai menampilkan baris apa pun? Ada banyak kemungkinan alasan, tetapi mari kita lihat satu contoh yang jelas. Ini kueri yang sama dari sebelumnya tetapi sekarang berisi ORDER BY klausa:
EXPLAIN SELECT * FROM post ORDER BY body LIMIT 50;
Limit (cost=23283.24..23283.37 rows=50 width=422)
-> Sort (cost=23283.24..23859.27 rows=230412 width=422)
Sort Key: body
-> Seq Scan on post (cost=0.00..15629.12 rows=230412 width=422)
Dan secara grafis:
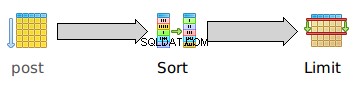
Sekali lagi, pemindaian berurutan pada post tidak memiliki biaya startup:ia mulai mengeluarkan baris dengan segera. Tetapi jenis ini memiliki biaya awal yang signifikan 23283.24 karena harus mengurutkan seluruh tabel sebelum dapat menampilkan bahkan satu baris . Total biaya sortir 23859.27 hanya sedikit lebih tinggi daripada biaya awal, yang mencerminkan fakta bahwa setelah seluruh kumpulan data telah diurutkan, data yang diurutkan dapat dipancarkan dengan sangat cepat.
Perhatikan bahwa waktu mulai dari LIMIT 23283.24 persis sama dengan waktu startup semacam itu. Ini bukan karena LIMIT sendiri memiliki waktu startup yang tinggi. Ini sebenarnya tidak memiliki waktu startup dengan sendirinya, tetapi EXPLAIN menggulung semua biaya anak untuk setiap orang tua, jadi LIMIT waktu mulai termasuk jumlah waktu mulai anak-anaknya.
Penggabungan biaya ini dapat membuat sulit untuk memahami biaya pelaksanaan masing-masing komponen. Misalnya, LIMIT . kami memiliki waktu startup nol, tapi itu tidak jelas pada pandangan pertama. Untuk alasan ini, beberapa orang lain menautkan ke explain.depesz.com, alat yang dibuat oleh Hubert Lubaczewski (alias depesz) yang membantu memahami EXPLAIN dengan — antara lain — mengurangkan biaya anak dari biaya induk. Dia menyebutkan beberapa kerumitan lain dalam posting blog singkat tentang alatnya.