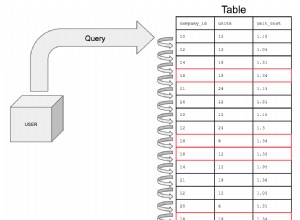
Definisi Anda:
kegiatan dari kelompok B selalu dilakukan setelah kegiatan dari kelompok A.
.. secara logis menyiratkan bahwa ada, per pengguna, 0 atau 1 aktivitas B setelah 1 atau lebih aktivitas A. Tidak pernah lebih dari 1 aktivitas B secara berurutan.
Anda dapat membuatnya bekerja dengan satu fungsi jendela, DISTINCT ON dan CASE , yang seharusnya menjadi cara tercepat untuk sedikit baris per pengguna (lihat juga di bawah):
SELECT name
, CASE WHEN a2 LIKE 'B%' THEN a1 ELSE a2 END AS activity
, CASE WHEN a2 LIKE 'B%' THEN a2 END AS next_activity
FROM (
SELECT DISTINCT ON (name)
name
, lead(activity) OVER (PARTITION BY name ORDER BY time DESC) AS a1
, activity AS a2
FROM t
WHERE (activity LIKE 'A%' OR activity LIKE 'B%')
ORDER BY name, time DESC
) sub;
db<>main biola di sini
SQL CASE ekspresi default ke NULL jika tidak ada ELSE cabang ditambahkan, jadi saya membuatnya singkat.
Dengan asumsi time didefinisikan NOT NULL . Jika tidak, Anda mungkin ingin menambahkan NULLS LAST . Mengapa?
- Urutkan menurut kolom ASC, tetapi nilai NULL terlebih dahulu?
(activity LIKE 'A%' OR activity LIKE 'B%') lebih verbose daripada activity ~ '^[AB]' , tetapi biasanya lebih cepat di versi Postgres yang lebih lama. Tentang pencocokan pola:
- Pencocokan pola dengan LIKE, SIMILAR TO atau ekspresi reguler di PostgreSQL
Fungsi jendela bersyarat?
Itu sebenarnya mungkin . Anda dapat menggabungkan agregat FILTER klausa dengan OVER klausa fungsi jendela. Namun :
-
FILTERklausa itu sendiri hanya dapat bekerja dengan nilai dari baris saat ini. -
Lebih penting lagi,
FILTERtidak diimplementasikan untuk fungsi asli murni sepertilead()ataulag()(hingga Postgres 13) - hanya untuk fungsi agregat.
Jika Anda mencoba:
lead(activity) FILTER (WHERE activity LIKE 'A%') OVER () AS activity
Postgres akan memberi tahu Anda:
FILTER is not implemented for non-aggregate window functions
Tentang FILTER :
- Kolom gabungan dengan filter tambahan (berbeda)
- Mereferensikan baris saat ini dalam klausa FILTER dari fungsi jendela
Kinerja
Untuk sedikit pengguna dengan sedikit baris per pengguna, cukup banyak apa saja kueri cepat, bahkan tanpa indeks.
Untuk banyak pengguna dan sedikit baris per pengguna, kueri pertama di atas harus tercepat. Lihat:
- Pilih baris pertama di setiap grup GROUP BY?
Untuk banyak baris per pengguna, ada (berpotensi banyak ) teknik yang lebih cepat, tergantung pada detail penyiapan Anda. Lihat:
- Optimalkan kueri GROUP BY untuk mengambil baris terbaru per pengguna