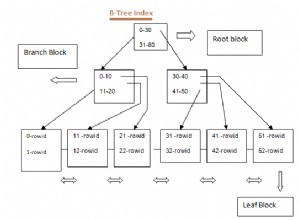
CLUSTER
Jika Anda ingin menggunakan CLUSTER , sintaks yang ditampilkan tidak valid.
create CLUSTER ticket USING ticket_1_idx;
Jalankan sekali:
CLUSTER ticket USING ticket_1_idx;
Ini bisa banyak membantu dengan set hasil yang lebih besar. Tidak terlalu banyak untuk satu baris yang dikembalikan.
Postgres mengingat indeks mana yang digunakan untuk panggilan berikutnya. Jika tabel Anda tidak hanya-baca, efeknya akan semakin buruk seiring waktu dan Anda perlu menjalankannya kembali pada interval tertentu:
CLUSTER ticket;
Mungkin hanya pada partisi yang mudah menguap. Lihat di bawah.
Namun , jika Anda memiliki banyak pembaruan, CLUSTER (atau VACUUM FULL ) mungkin sebenarnya buruk untuk kinerja. Jumlah kembung yang tepat memungkinkan UPDATE untuk menempatkan versi baris baru pada halaman data yang sama dan menghindari kebutuhan untuk terlalu sering memperluas file yang mendasarinya secara fisik di OS. Anda dapat menggunakan FILLFACTOR yang disetel dengan hati-hati untuk mendapatkan yang terbaik dari kedua dunia:
- Faktor isian untuk indeks sekuensial yaitu PK
pg_repack
CLUSTER mengambil kunci eksklusif di atas meja, yang mungkin menjadi masalah di lingkungan multi-pengguna. Mengutip manual:
Saat sebuah tabel sedang dikelompokkan, sebuah
ACCESS EXCLUSIVEkunci diperoleh di atasnya. Ini mencegah operasi basis data lainnya (baik membaca dan menulis ) dari pengoperasian di atas meja hinggaCLUSTERselesai.
Penekanan saya yang berani. Pertimbangkan pg_repack alternatif :
Tidak seperti
CLUSTERdanVACUUM FULLia bekerja secara online, tanpa menahan kunci eksklusif pada tabel yang diproses selama pemrosesan. pg_repack efisien untuk boot, dengan kinerja yang sebanding dengan menggunakanCLUSTERsecara langsung.
dan:
pg_repack perlu mengambil kunci eksklusif di akhir reorganisasi.
Versi 1.3.1 bekerja dengan:
PostgreSQL 8.3, 8.4, 9.0, 9.1, 9.2, 9.3, 9.4
Versi 1.4.2 bekerja dengan:
PostgreSQL 9.1, 9.2, 9.3, 9.4, 9.5, 9.6, 10
Kueri
Kuerinya cukup sederhana untuk tidak menyebabkan masalah kinerja apa pun.
Namun, sepatah kata pun tentang kebenaran :BETWEEN membangun termasuk perbatasan. Kueri Anda memilih semua tanggal 19 Desember, plus catatan dari 20 Desember, 00:00 jam. Itu sangat tidak mungkin persyaratan. Kemungkinan besar, Anda benar-benar ingin:
SELECT *
FROM ticket
WHERE created >= '2012-12-19 0:0'
AND created < '2012-12-20 0:0';
Kinerja
Pertama, Anda bertanya:
Mengapa memilih pemindaian berurutan?
EXPLAIN . Anda keluaran dengan jelas menunjukkan Pemindaian Indeks , bukan pemindaian tabel berurutan. Pasti ada semacam kesalahpahaman.
Jika Anda ditekan keras untuk kinerja yang lebih baik, Anda mungkin dapat meningkatkan hal-hal. Tetapi informasi latar belakang yang diperlukan tidak ada dalam pertanyaan. Opsi yang memungkinkan meliputi:
-
Anda hanya dapat menanyakan kolom yang diperlukan alih-alih
*untuk mengurangi biaya transfer (dan kemungkinan manfaat kinerja lainnya). -
Anda dapat melihat partisi dan menempatkan irisan waktu praktis ke dalam tabel terpisah. Tambahkan indeks ke partisi sesuai kebutuhan.
-
Jika mempartisi bukanlah pilihan, teknik lain yang terkait tetapi tidak terlalu mengganggu adalah dengan menambahkan satu atau lebih indeks parsial .
Misalnya, jika Anda kebanyakan menanyakan bulan berjalan , Anda dapat membuat indeks parsial berikut:CREATE INDEX ticket_created_idx ON ticket(created) WHERE created >= '2012-12-01 00:00:00'::timestamp;CREATEindeks baru tepat sebelum awal bulan baru. Anda dapat dengan mudah mengotomatiskan tugas dengan tugas cron. OpsionalDROPindeks parsial untuk bulan-bulan lama kemudian. -
Simpan total indeks sebagai tambahan untuk
CLUSTER(yang tidak dapat beroperasi pada indeks parsial). Jika record lama tidak pernah berubah, partisi tabel akan sangat membantu tugas ini, karena Anda hanya perlu mengelompokkan ulang partisi yang lebih baru. Kemudian jika record tidak pernah berubah sama sekali, Anda mungkin tidak memerlukanCLUSTER.
Jika Anda menggabungkan dua langkah terakhir, performanya akan luar biasa.
Dasar-dasar Kinerja
Anda mungkin kehilangan salah satu dasar-dasarnya. Semua saran kinerja yang biasa berlaku:
- https://wiki.postgresql.org/wiki/Slow_Query_Questions
- https://wiki.postgresql.org/wiki/Performance_Optimization