Nah, menganalisis penyebaran virus corona SARS-CoV-2 bukanlah kasus penggunaan impian saya . Tetapi berdasarkan tanggapan Ferry Djaja's Tracking Coronavirus COVID-19 Near Real Time dengan artikel SAP HANA XSA, saya memutuskan untuk menambahkan dua groszy saya juga.
[Diperbarui pada 30-03-30 dengan tautan yang diubah ke data sumber; dan keluaran peta baru berdasarkan perincian data baru. Terima kasih Douglas Maltby atas komentar Anda!]
Dalam posting blognya, Ferry menggunakan JavaScript di SAP HANA XSA untuk menarik data dari file CSV yang diperbarui setiap hari oleh Universitas Johns Hopkins.
Saya ingin menunjukkan kepada Anda bagaimana Anda dapat menarik dan memuat file-file ini ke dalam SAP HANA hanya dengan menggunakan beberapa baris kode terima kasih kepada SAP HANA Python Client API untuk Pembelajaran Mesin (hana_ml paket).
Beberapa orang bingung dengan visualisasi pada peta di bagian akhir — harap perhatikan bahwa artikel ini berfokus pada kasus penggunaan teknis yang menghubungkan berbagai komponen, bukan pada analisis mendalam data virus corona.
Dapatkan lingkungan Python, mis. Jupyter
Saya akan menggunakan Jupyter dalam wadah Docker untuk itu. Silakan lihat posting saya sebelumnya Memahami wadah (bagian 05):berbagi file antara host dan wadah jika Anda tidak terbiasa dengan cara memulainya. Anda juga dapat melakukan semua langkah yang sama di bawah ini dari lingkungan Python lainnya.
Jadi, saya punya wadah saya myjupyter01 berlari. Saya terhubung ke UI Jupyter seperti yang dijelaskan di blog sebelumnya.
Instal hana_ml
Gambar Jupyter yang saya gunakan dari registri Docker Hub adalah jupyter/minimal-notebook . Ini sudah berisi beberapa paket pemrosesan data populer, seperti pandas .
Tapi selain itu, saya perlu menginstal hana_ml , yang — dalam versi saat ini 1.0.8 — tersedia di repositori PyPI:https://pypi.org/project/hana-ml/.
Perintah untuk menjalankan instalasi adalah python -m pip install hana_ml , tetapi karena saya menjalankannya dari notebook Jupyter dengan kernel Python3, saya perlu menjalankannya dengan ! di awal:
!python -m pip install hana_ml
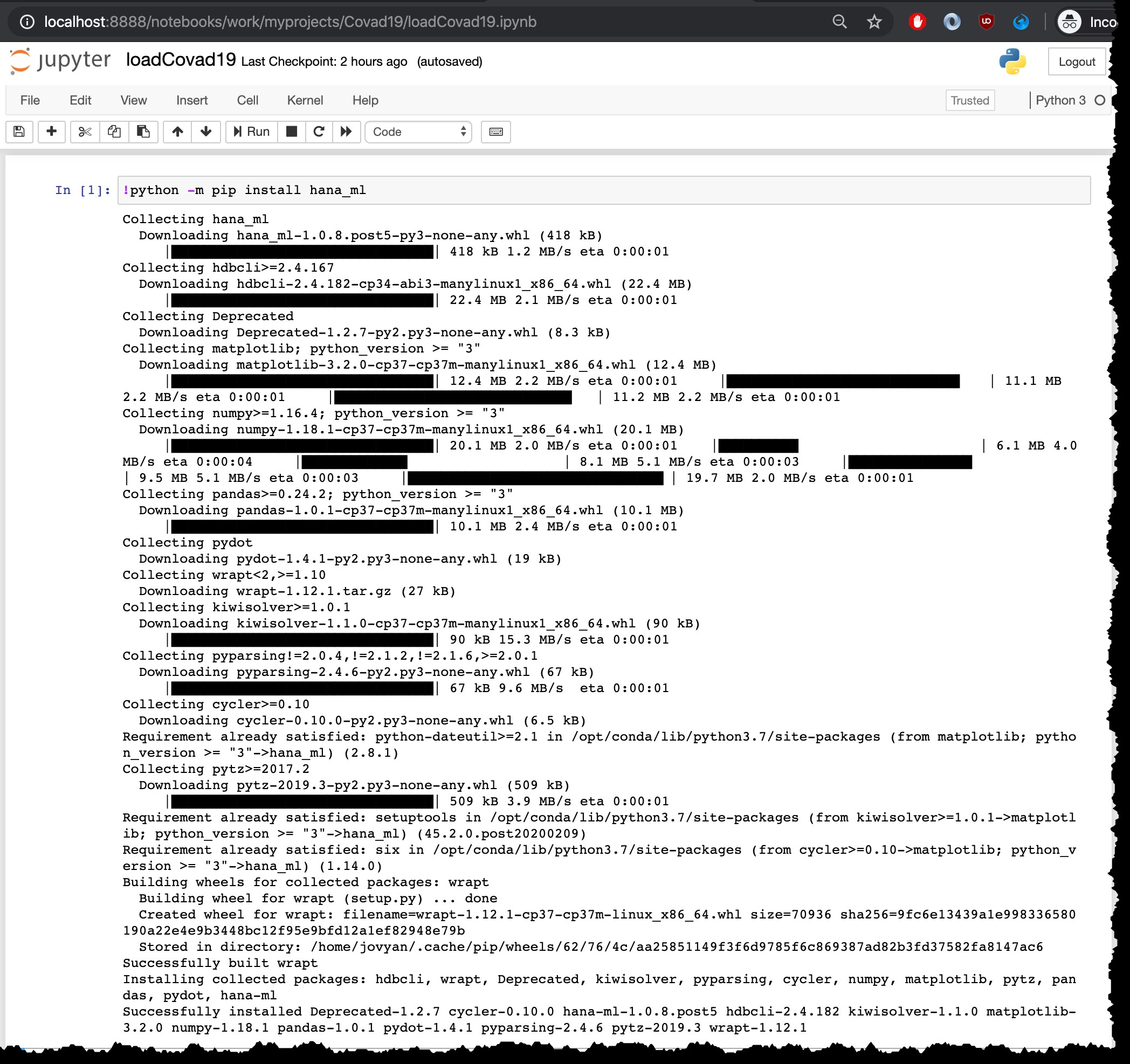
Jelas, langkah instalasi ini harus dilakukan hanya sekali. Tidak perlu menjalankannya kembali dalam wadah yang sama mis. saat memuat ulang file terbaru.
Gunakan pandas untuk mengimpor file dengan data
Mari impor tiga file yang sama (confirmed , deaths , recovered ) dari https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series seperti yang digunakan Ferry dalam contohnya.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
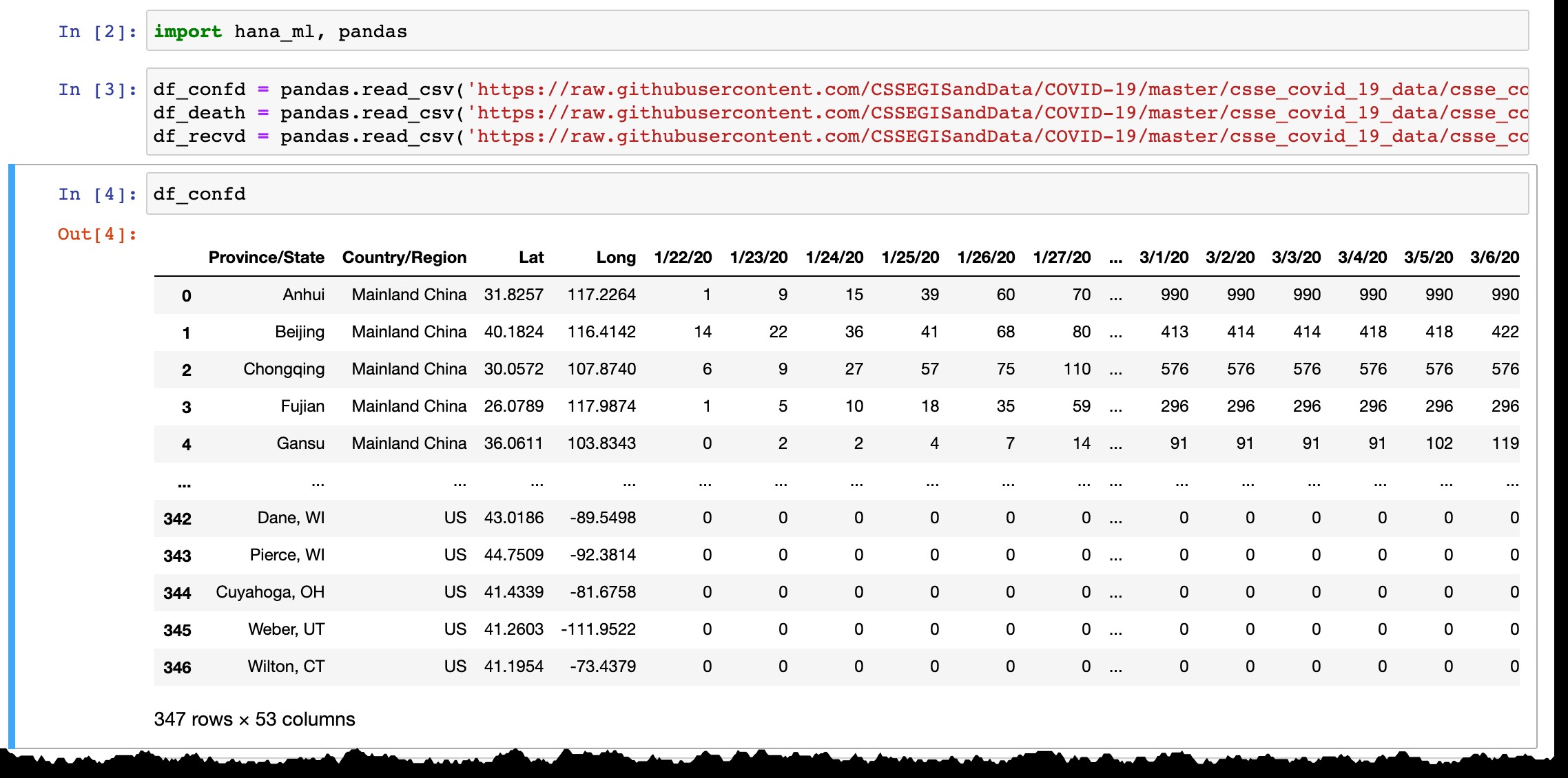
Seperti yang dapat Anda lihat dari pratinjau kerangka data Pandas, ini hanya mencantumkan negara atau provinsi dengan kasus yang dikonfirmasi, dan setiap hari kolom baru ditambahkan dengan data terbaru dari hari sebelumnya. Garis ditambahkan ketika kasus pertama dikonfirmasi di wilayah baru.
Gunakan pandas untuk memformat ulang bingkai data
Sebelum menyimpan data di SAP HANA, mari:
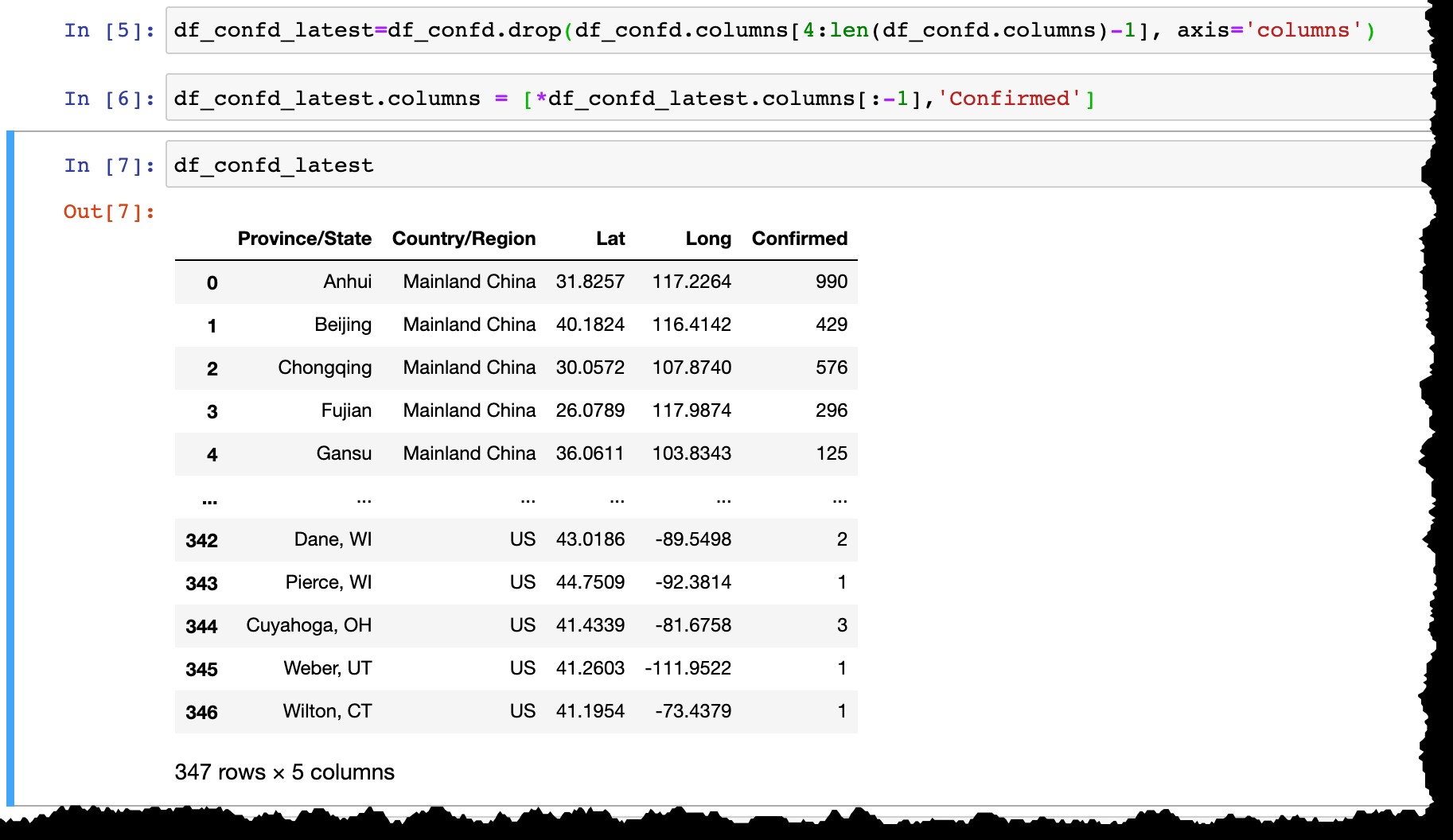
- Hapus semua kolom tanggal kecuali yang terakhir,
- Ganti nama kolom terakhir dari tanggal sebenarnya (seperti
3/10/20hari ini) keConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
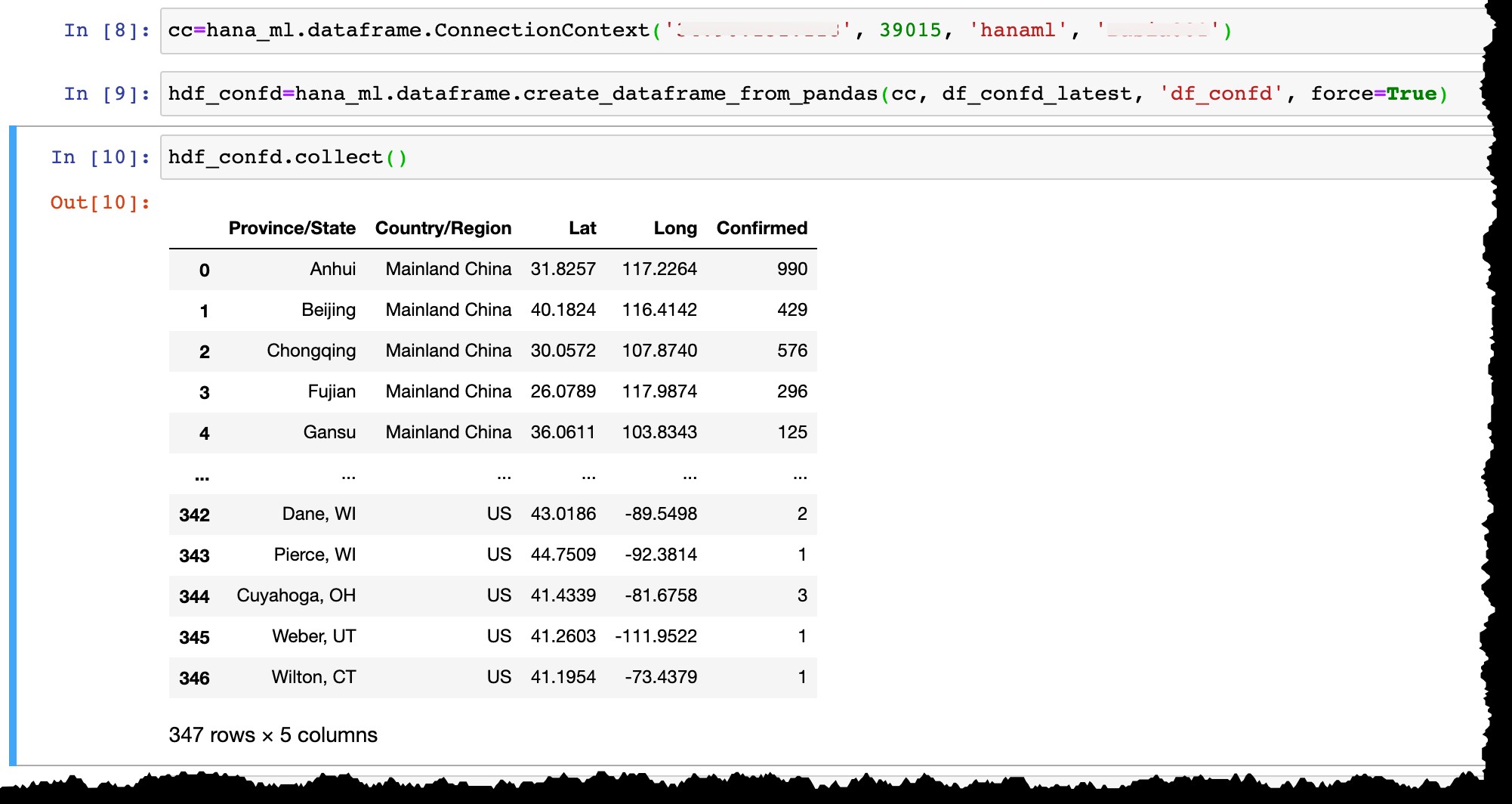
Gunakan hana_ml untuk menyimpan data di tabel SAP HANA
Sekarang izinkan saya terhubung ke instance SAP HANA Express saya dengan pengguna hanaml yang sudah ada disana…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
…dan mengonversi kerangka data Pandas df_confd_latest ke dalam kerangka data HANA hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Setelah kerangka data HANA dibuat:
- Tabel kolom fisik dibuat di HANA dan data dari kerangka data Panda dimasukkan di sana,
- Kerangka data HANA
hdf_confddi Python tidak menyimpan data apa pun di laptop Anda, tetapi hanya menunjuk ke tabelHANAML.df_confddalam memori server SAP HANA, dan semua operasi Python pada kerangka data HANA secara fisik dijalankan dalam db HANA tanpa memindahkan data antara server dan klien, - Untuk menampilkan hasil operasi apa pun, kita perlu menerapkan
collect()metode untuk mengonversi kerangka data HANA ke Pandas (dan sebagai hasilnya membawa data dari server db HANA ke klien lokal).
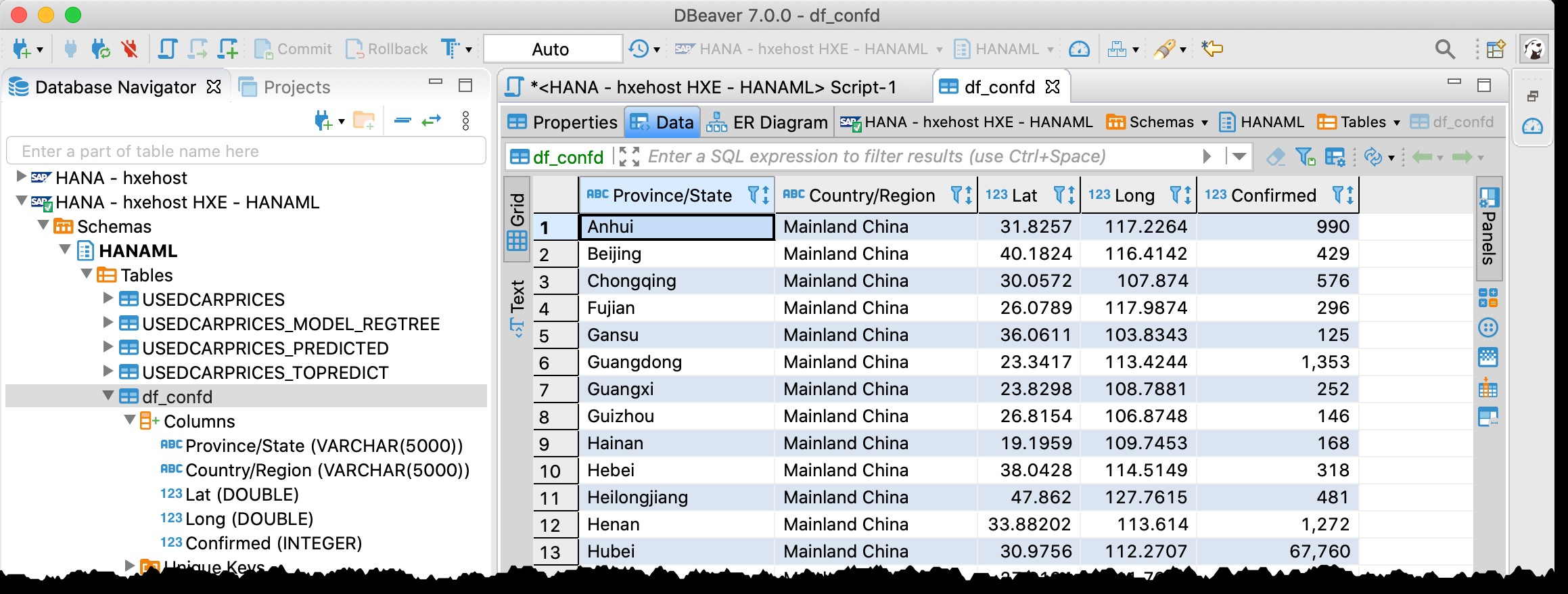
Gunakan DBeaver untuk memeriksa data di SAP HANA…
Anda mungkin ingat saya sudah menggunakan DBeaver — alat database gratis yang mendukung SAP HANA — di posting saya sebelumnya “GeoArt dengan SAP HANA dan DBeaver“.
Saya menggunakannya sekarang lagi, dan memang saya dapat menemukan tabel df_confd dalam skema HANAML dengan semua data dari sumber dataframe Pandas.
…dan lakukan pratinjau spasial
Karena tabel berisi kolom lintang dan bujur, saya dapat memvisualisasikan negara/negara bagian yang terkena dampak langsung dari DBeaver dengan SQL berikut menggunakan pratinjau data Spasial.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Saya perlu mengubah proyeksi peta menjadi EPSG:4326 untuk mendapatkan titik-titik ini di peta. Dan DBeaver menunjukkan sisa data rekaman saat saya mengklik titik mana pun.
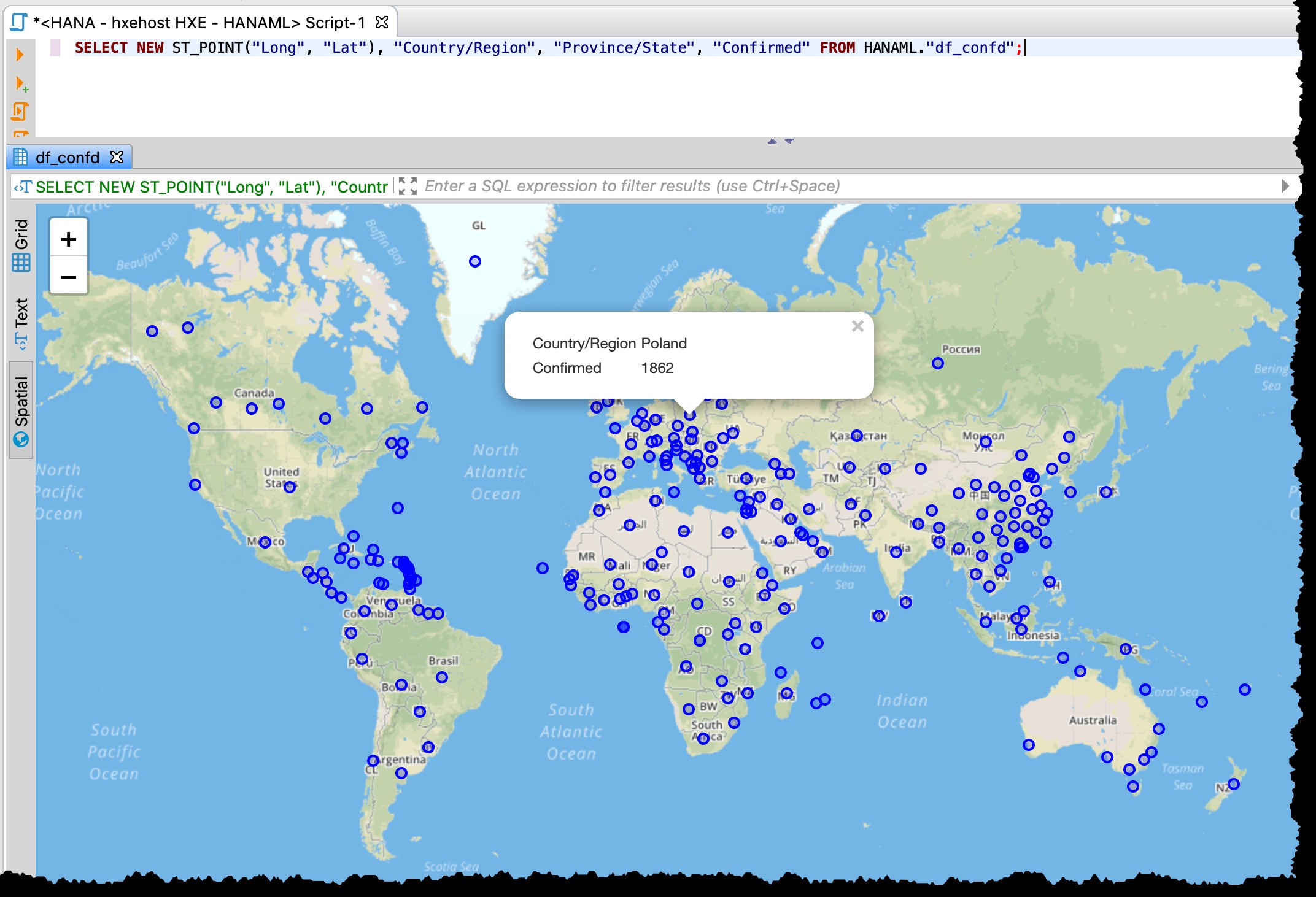
[Di bawah adalah tangkapan layar lama dari 11-03-2020, yang juga menunjukkan perincian yang berbeda dari mis. Data AS yang digunakan saat itu]
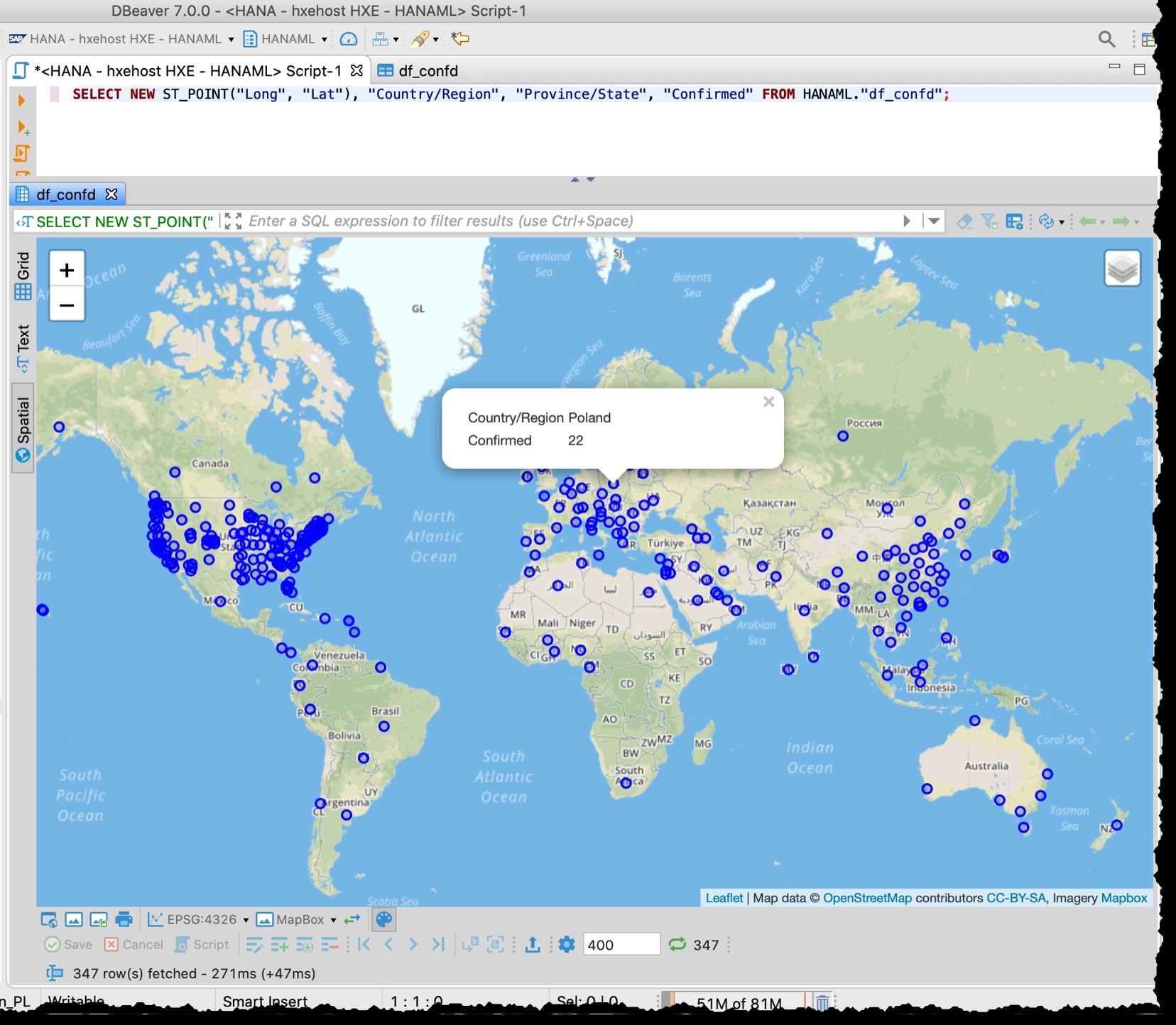
Pratinjau spasial DBeaver bukanlah alat eksplorasi visual geospasial yang lengkap. Namun cukup baik untuk melihat negara/wilayah yang terpengaruh (bergantung pada perincian dalam file sumber).
Jika Anda tertarik untuk mempelajari lebih lanjut tentang hana_ml …
… maka saya pasti akan merekomendasikan untuk memeriksa Tutorial Praktis:Machine Learning push-down ke SAP HANA dengan Python oleh Andreas Forster.
HANA ML adalah bagian dari topik "Analisis Lanjutan dengan SAP HANA" baru untuk acara CodeJam. Sayangnya karena situasi coronavirus, kami harus membatalkan yang pertama yang diselenggarakan oleh Jakob Flaman di Bern bulan ini. Satu lagi diselenggarakan oleh Ewelina Pękała pada 27 Mei di Katowice:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Mudah-mudahan, situasinya akan normal pada saat itu, dan kami tidak perlu membatalkan yang ini juga.