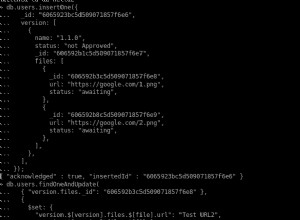
Catat perintah beberapa baris di bawah dokumentasi yang Anda tautkan:
Ini memberi tahu Anda bahwa bidang yang tidak ada dan bidang yang disetel ke nol diperlakukan secara khusus.
Agar dokumen {} dan {a: null} agar setara dalam urutan pengurutan, algoritme pengurutan harus mempertimbangkan bidang pengurutan yang hilang untuk ada, dan memiliki nilai null .
Jika Anda secara eksplisit menambahkan bidang yang hilang, hanya untuk melihat tampilannya, pengurutannya lebih masuk akal.
Filter {tag: { $gte: { baz: MinKey() }}} diterapkan ke {_id: 1, tag: {bar: "BAR"}} pada dasarnya membandingkan {baz: MinKey()} dengan {baz: null, bar: "BAR"} .
Di dekat bagian atas dokumen yang Anda tautkan, tertulis bahwa MinKey kurang dari null , jadi itu urutan yang benar.
EDIT
Secara umum, kueri paling efisien ketika nama bidang bukan data itu sendiri. Dalam hal database tabular, kolom mana yang akan berisi "baz"?
Sedikit perubahan dalam skema akan menyederhanakan jenis kueri ini. Alih-alih {tagname: tagvalue} , gunakan {k:tagname, v:tagvalue} . Anda kemudian dapat mengindeks tag.k dan/atau tag.v , dan kueri di tag.k untuk menemukan semua dokumen dengan tag "baz", kueri tag dengan operasi ketidaksetaraan akan bekerja lebih intuitif.
db.collection.find({"tag.k":{$gte:"baz"}})
Pencocokan persis dapat dilakukan dengan elemMatch seperti
db.collection.find({tag: {$elemMatch:{k:"baz",v:"BAZ"}}})
Jika Anda benar-benar membutuhkan dokumen yang dikembalikan berisi {tagname: tagvalue} , $arrayToObject operator agregasi dapat melakukannya:
db.collection.aggregate([
{$match: {
"tag.k": {$gte: "baz"}
}},
{
$addFields: {
tag: {$arrayToObject: [["$tag"]]}
}}
])