Jika Anda perlu menghitung kesamaan teks pada about salah satu cara untuk mencapainya adalah dengan menggunakan indeks teks
.
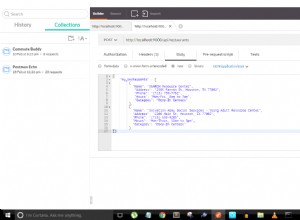
Misalnya (dalam mongo shell), jika Anda membuat indeks teks pada about bidang:
db.collection.createIndex({about: 'text'})
anda dapat menjalankan kueri seperti (contoh diambil dari https://docs.mongodb.com/manual/reference/operator/query/text/#sort-by-text-search-score ):
db.collection.find({$text: {$search: 'similarity in comparison'}}, {score: {$meta: 'textScore'}}).sort({score: {$meta: 'textScore'}})
Dengan dokumen contoh Anda, kueri akan mengembalikan sesuatu seperti:
{
"_id": "foobar1",
"about": "similarity in comparison",
"score": 1.5
}
{
"_id": "foobar2",
"about": "perfect similarity in comparison",
"score": 1.3333333333333333
}
{
"_id": "foobar3",
"about": "partial similarity",
"score": 0.75
}
yang diurutkan berdasarkan penurunan skor kesamaan. Harap perhatikan bahwa tidak seperti hasil contoh Anda, dokumen foobar4 tidak dikembalikan karena tidak ada kata tanya yang ada di foobar4 .
Indeks teks dianggap sebagai jenis indeks khusus di MongoDB, dan karenanya dilengkapi dengan beberapa aturan khusus tentang penggunaannya. Untuk lebih jelasnya, silakan lihat: