Kematian produksi hampir dipastikan akan terjadi di beberapa titik. Menerima fakta ini dan menganalisis garis waktu dan skenario kegagalan pemadaman database Anda dapat membantu mempersiapkan, mendiagnosis, dan memulihkan dengan lebih baik dari yang berikutnya. Untuk mengurangi dampak waktu henti, organisasi memerlukan rencana pemulihan bencana (DR) yang tepat. Perencanaan DR adalah tugas penting bagi banyak SysOps/DevOps, tetapi meskipun sudah diperkirakan sebelumnya; seringkali tidak ada.
Dalam posting blog ini, kami akan menganalisis skenario pencadangan dan kegagalan yang berbeda dalam sistem basis data MongoDB. Kami juga akan memandu Anda melalui prosedur pemulihan dan failover untuk setiap skenario masing-masing. Kasus penggunaan ini akan bervariasi dari memulihkan satu node, memulihkan node di replicaSet yang ada, dan seeding node baru di replicaSet. Semoga ini akan memberi Anda pemahaman yang baik tentang risiko yang mungkin Anda hadapi dan apa yang harus dipertimbangkan saat merancang infrastruktur Anda.
Sebelum kita mulai membahas kemungkinan skenario kegagalan, mari kita lihat bagaimana MongoDB menyimpan data dan jenis cadangan apa yang tersedia.
Bagaimana MongoDB Menyimpan Data
MongoDB adalah database berorientasi dokumen. Alih-alih menyimpan data Anda dalam tabel yang terbuat dari baris individual (seperti halnya database relasional), ia menyimpan data dalam koleksi yang terbuat dari dokumen individual. Di MongoDB, dokumen adalah gumpalan JSON besar tanpa format atau skema tertentu. Selain itu, data dapat disebarkan ke node cluster yang berbeda dengan berbagi atau direplikasi ke server slave dengan replicaSet.
MongoDB memungkinkan penulisan dan pembaruan yang sangat cepat secara default. Imbalannya adalah sering kali Anda tidak diberitahu secara eksplisit tentang kegagalan. Secara default, sebagian besar driver melakukan penulisan yang tidak sinkron dan tidak aman. Ini berarti bahwa driver tidak mengembalikan kesalahan secara langsung, mirip dengan INSERT DELAYED dengan MySQL. Jika Anda ingin tahu apakah sesuatu berhasil, Anda harus memeriksa kesalahan secara manual menggunakan getLastError.
Untuk kinerja yang optimal, sebaiknya gunakan SSD daripada HDD untuk penyimpanan. Penting untuk menjaga apakah penyimpanan Anda lokal atau jauh dan mengambil tindakan yang sesuai. Lebih baik menggunakan RAID untuk perlindungan cacat perangkat keras dan skema pemulihan, tetapi jangan mengandalkan sepenuhnya karena tidak menawarkan perlindungan terhadap kegagalan yang merugikan. Perangkat keras yang tepat adalah landasan bagi aplikasi Anda untuk mengoptimalkan kinerja dan menghindari bencana besar.
Korupsi data tingkat disk atau file data yang hilang dapat mencegah instance mongod dimulai, dan file jurnal mungkin tidak cukup untuk dipulihkan secara otomatis.
Jika Anda menjalankan dengan penjurnalan diaktifkan, hampir tidak ada kebutuhan untuk menjalankan perbaikan karena server dapat menggunakan file jurnal untuk memulihkan file data ke status bersih secara otomatis. Namun, Anda mungkin masih perlu menjalankan perbaikan jika Anda perlu memulihkan dari kerusakan data tingkat disk.
Jika penjurnalan tidak diaktifkan, satu-satunya pilihan Anda mungkin adalah menjalankan perintah perbaikan. mongod --repair harus digunakan hanya jika Anda tidak memiliki opsi lain karena operasi menghapus (dan tidak menyimpan) data yang rusak selama proses perbaikan. Jenis operasi ini harus selalu didahului dengan pencadangan.
Skenario Pemulihan Bencana MongoDB
Dalam rencana pemulihan kegagalan, Tujuan Titik Pemulihan (RPO) Anda adalah parameter pemulihan utama yang menentukan berapa banyak data yang dapat Anda hilangkan. RPO terdaftar dalam waktu, dari milidetik hingga hari dan secara langsung bergantung pada sistem cadangan Anda. Ini mempertimbangkan usia data cadangan Anda yang harus Anda pulihkan untuk melanjutkan operasi normal.
Untuk memperkirakan RPO, Anda perlu mengajukan beberapa pertanyaan kepada diri sendiri. Kapan data saya dicadangkan? Apa SLA yang terkait dengan pengambilan data? Apakah memulihkan cadangan data dapat diterima atau apakah data harus online dan siap untuk ditanyakan pada waktu tertentu?
Jawaban atas pertanyaan ini akan membantu mendorong jenis solusi pencadangan yang Anda butuhkan.
Solusi Pencadangan MongoDB
Teknik pencadangan memiliki dampak yang berbeda-beda pada kinerja database yang sedang berjalan. Beberapa solusi pencadangan menurunkan kinerja basis data sehingga Anda mungkin perlu menjadwalkan pencadangan untuk menghindari penggunaan puncak atau periode pemeliharaan. Anda dapat memutuskan untuk menggunakan server sekunder baru hanya untuk mendukung pencadangan.
Tiga solusi paling umum untuk mencadangkan server/cluster MongoDB Anda adalah...
- Mongodump/Mongorestore - pencadangan logis.
- Sistem Manajemen Mongo (Cloud) - Basis data produksi dapat dicadangkan menggunakan MongoDB Ops Manager atau jika menggunakan layanan MongoDB Atlas Anda dapat menggunakan solusi pencadangan yang terkelola sepenuhnya.
- Cuplikan Basis Data (pencadangan tingkat disk)
Mongodump/Mongorestore
Saat melakukan mongodump, semua koleksi dalam database yang ditentukan akan dibuang sebagai output BSON. Jika tidak ada database yang ditentukan, MongoDB akan membuang semua database kecuali database admin, pengujian, dan lokal karena dicadangkan untuk penggunaan internal.
Secara default, mongodump akan membuat direktori bernama dump, dengan direktori untuk setiap database yang berisi file BSON per koleksi dalam database tersebut. Atau, Anda dapat memberi tahu mongodump untuk menyimpan cadangan dalam satu file arsip tunggal. Parameter arsip akan menggabungkan output dari semua database dan koleksi menjadi satu aliran data biner. Selain itu, parameter gzip secara alami dapat mengompresi arsip ini, menggunakan gzip. Di ClusterControl kami mengalirkan semua cadangan kami, jadi kami mengaktifkan parameter arsip dan gzip.
Mirip dengan mysqldump dengan MySQL, jika Anda membuat cadangan di MongoDB itu akan membekukan koleksi saat membuang konten ke file cadangan. Karena MongoDB tidak mendukung transaksi (diubah pada 4.2), Anda tidak dapat membuat cadangan yang sepenuhnya konsisten 100% kecuali jika Anda membuat cadangan dengan parameter oplog. Mengaktifkan ini pada pencadangan mencakup transaksi dari oplog yang dijalankan saat membuat pencadangan.
Untuk otomatisasi yang lebih baik dan Anda dapat menjalankan MongoDB dari baris perintah atau menggunakan alat eksternal seperti ClusterControl. ClusterControl adalah opsi yang direkomendasikan untuk manajemen pencadangan dan otomatisasi pencadangan, karena memungkinkan pembuatan strategi pencadangan lanjutan untuk berbagai sistem basis data sumber terbuka.
ClusterControl memungkinkan Anda mengunggah cadangan ke awan. Ini mendukung cadangan penuh dan mengembalikan enkripsi mongodump. Jika Anda ingin melihat cara kerjanya, ada demo di situs web kami.
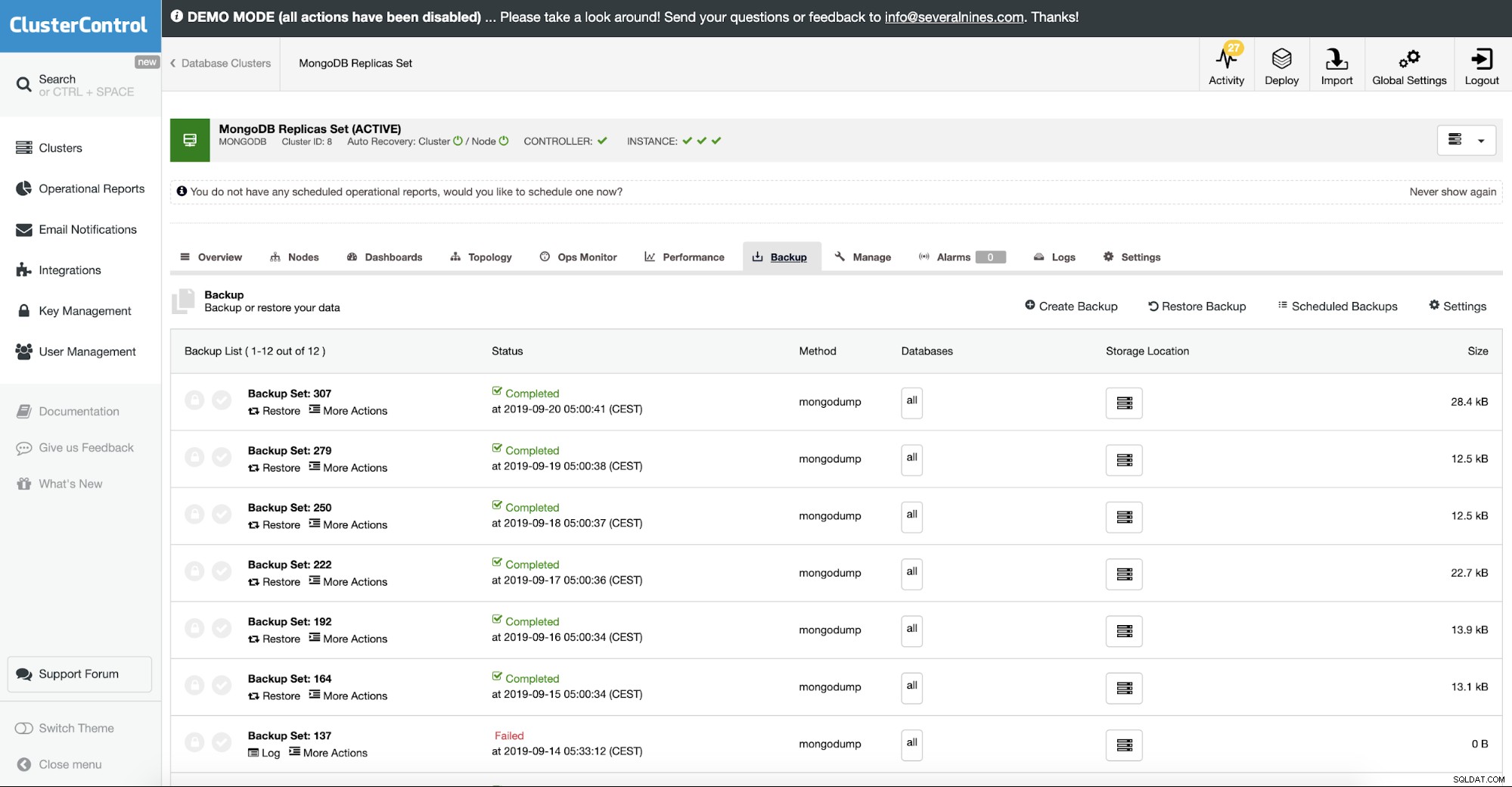
Memulihkan MongoDB Dari Cadangan
Pada dasarnya ada dua cara Anda dapat menggunakan dump format BSON:
- Jalankan mongod langsung dari direktori cadangan
- Jalankan mongorestore dan pulihkan cadangan
Jalankan mongod Langsung Dari Cadangan
Prasyarat untuk menjalankan mongod langsung dari cadangan adalah bahwa target pencadangan adalah dump standar, dan tidak di-gzip.
Daemon MongoDB kemudian akan memeriksa integritas direktori data, menambahkan database admin, jurnal, katalog koleksi dan indeks, dan beberapa file lain yang diperlukan untuk menjalankan MongoDB. Jika Anda menjalankan WiredTiger sebagai mesin penyimpanan sebelumnya, sekarang akan menjalankan koleksi yang ada sebagai MMAP. Untuk dump data sederhana atau pemeriksaan integritas, ini berfungsi dengan baik.
Menjalankan mongorestore
Cara yang lebih baik untuk memulihkan tentu saja dengan memulihkan simpul menggunakan mongorestore.
mongorestore dump/Ini akan memulihkan cadangan ke pengaturan server default (localhost, port 27717) dan menimpa basis data apa pun dalam cadangan yang berada di server ini. Sekarang ada banyak parameter untuk memanipulasi proses pemulihan, dan kami akan membahas beberapa yang penting.
Dalam ClusterControl ini dilakukan dalam opsi restore backup. Anda dapat memilih mesin kapan cadangan akan dipulihkan dan memproses dengan mengurus sisanya. Ini termasuk cadangan terenkripsi di mana biasanya Anda juga perlu mendekripsi cadangan Anda.
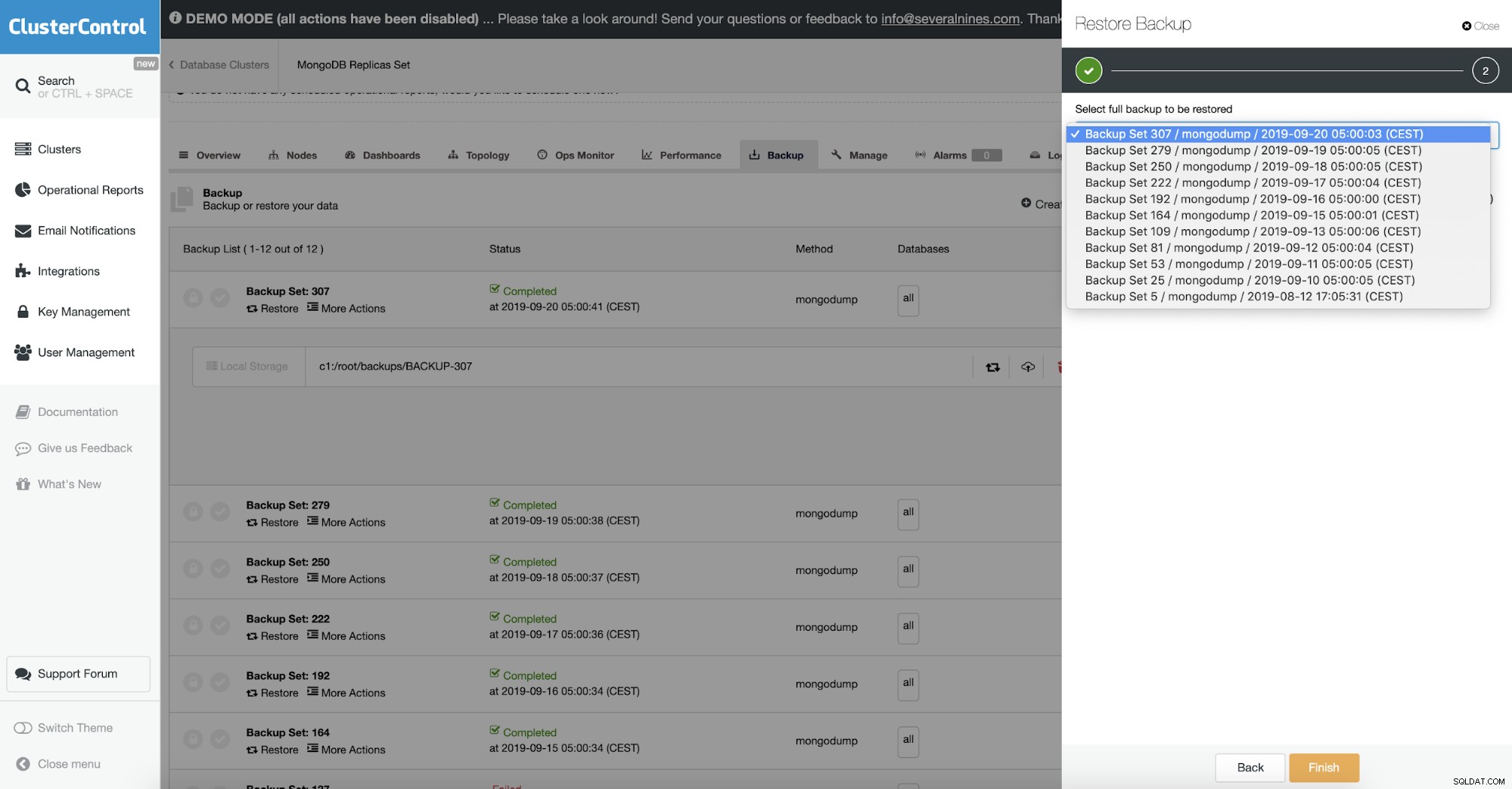
Validasi Objek
Karena cadangan berisi data BSON, Anda akan mengharapkan konten cadangan benar. Namun, bisa jadi dokumen yang dibuang itu salah format, sejak awal. Mongodump tidak memeriksa integritas data yang dibuangnya.
Untuk mengatasi penggunaan itu -- objcheck yang memaksa mongorestore untuk memvalidasi semua permintaan dari klien setelah diterima untuk memastikan bahwa klien tidak pernah memasukkan dokumen yang tidak valid ke dalam database. Ini dapat berdampak kecil pada kinerja.
Putar Ulang Oplog
Oplog ke pencadangan Anda akan memungkinkan Anda melakukan pencadangan yang konsisten dan melakukan pemulihan tepat waktu. Aktifkan parameter oplogReplay untuk menerapkan oplog selama proses pemulihan. Untuk mengontrol seberapa jauh memutar ulang oplog, Anda dapat menentukan cap waktu di parameter oplogLimit. Hanya transaksi hingga stempel waktu yang akan diterapkan.
Memulihkan ReplicaSet Penuh Dari Cadangan
Memulihkan replicaSet tidak jauh berbeda dengan memulihkan satu node. Entah Anda harus mengatur replikaSet terlebih dahulu dan memulihkan langsung ke dalam replikaSet. Atau Anda memulihkan satu simpul terlebih dahulu, lalu menggunakan simpul yang dipulihkan ini untuk membuat replikaSet.
Kembalikan node terlebih dahulu, lalu buat replicaSet
Sekarang node kedua dan ketiga akan menyinkronkan data mereka dari node pertama. Setelah sinkronisasi selesai, replicaSet kami telah dipulihkan.
Buat ReplicaSet terlebih dahulu, lalu pulihkan
Berbeda dengan proses sebelumnya, Anda bisa membuat replicaSet terlebih dahulu. Pertama-tama konfigurasikan ketiga host dengan replikaSet diaktifkan, mulai ketiga daemon dan mulai replikaSet pada simpul pertama:
Sekarang setelah kita membuat replicaSet, kita dapat langsung mengembalikan cadangan kita ke dalamnya:
Menurut kami, memulihkan replikaSet dengan cara ini jauh lebih elegan. Ini lebih dekat dengan cara Anda biasanya menyiapkan replikaSet baru dari awal, lalu mengisinya dengan data (produksi).
Menyemai Node Baru dalam ReplicaSet
Saat menskalakan cluster dengan menambahkan node baru di MongoDB, sinkronisasi awal set data harus terjadi. Dengan replikasi MySQL dan Galera, kami sangat terbiasa menggunakan cadangan untuk menyemai sinkronisasi awal. Dengan MongoDB ini dimungkinkan, tetapi hanya dengan membuat salinan biner dari direktori data. Jika Anda tidak memiliki sarana untuk membuat snapshot sistem file, Anda harus menghadapi waktu henti di salah satu node yang ada. Prosesnya, dengan waktu henti, dijelaskan di bawah ini.
Menyemai Dengan Cadangan
Jadi apa yang akan terjadi jika Anda mengembalikan node baru dari cadangan mongodump, dan kemudian bergabung dengan replicaSet? Memulihkan dari cadangan seharusnya, secara teori, memberikan kumpulan data yang sama. Karena simpul baru ini telah dipulihkan dari cadangan, ia akan kekurangan replikaSetId dan MongoDB akan melihatnya. Karena MongoDB tidak melihat node ini sebagai bagian dari replicaSet, maka perintah rs.add() akan selalu memicu sinkronisasi awal MongoDB. Sinkronisasi awal akan selalu memicu penghapusan data yang ada di node MongoDB.
ReplikaSetId dihasilkan saat memulai replicaSet, dan sayangnya tidak dapat disetel secara manual. Sayang sekali karena memulihkan dari cadangan (termasuk memutar ulang oplog) secara teoritis akan memberi kita kumpulan data yang 100% identik. Akan lebih baik jika sinkronisasi awal adalah opsional di MongoDB untuk memenuhi kasus penggunaan ini.



