Pemeliharaan adalah sesuatu yang tidak dapat dihindari oleh tim operasi. Server harus mengikuti perangkat lunak, perangkat keras, dan teknologi terbaru untuk memastikan sistem stabil dan berjalan dengan risiko serendah mungkin, sambil memanfaatkan fitur yang lebih baru untuk meningkatkan kinerja secara keseluruhan.
Tidak diragukan lagi, ada daftar panjang tugas pemeliharaan yang harus dilakukan oleh administrator sistem, terutama jika menyangkut sistem kritis. Beberapa tugas harus dilakukan secara berkala, seperti harian, mingguan, bulanan, dan tahunan. Beberapa harus dilakukan segera, mendesak. Namun demikian, setiap operasi pemeliharaan tidak boleh menyebabkan masalah lain yang lebih besar, dan pemeliharaan apa pun harus ditangani dengan sangat hati-hati untuk menghindari gangguan apa pun pada bisnis.
Mendapatkan status yang dipertanyakan dan alarm palsu adalah hal biasa saat pemeliharaan sedang berlangsung. Hal ini diharapkan karena selama masa pemeliharaan, server tidak akan beroperasi sebagaimana mestinya sampai tugas pemeliharaan selesai. ClusterControl, platform pengelolaan dan pemantauan lengkap untuk database open-source Anda, dapat dikonfigurasi untuk memahami keadaan ini guna menyederhanakan rutinitas pemeliharaan Anda, tanpa mengorbankan fitur pemantauan dan otomatisasi yang ditawarkannya.
Mode Pemeliharaan
ClusterControl memperkenalkan mode pemeliharaan di versi 1.4.0, di mana Anda dapat menempatkan satu node ke dalam pemeliharaan yang mencegah ClusterControl untuk membunyikan alarm dan mengirim pemberitahuan untuk durasi yang ditentukan. Mode pemeliharaan dapat dikonfigurasi dari ClusterControl UI dan juga menggunakan alat ClusterControl CLI yang disebut "s9s". Dari UI, cukup buka Node -> pilih node -> Node Actions -> Schedule Maintenance Mode :
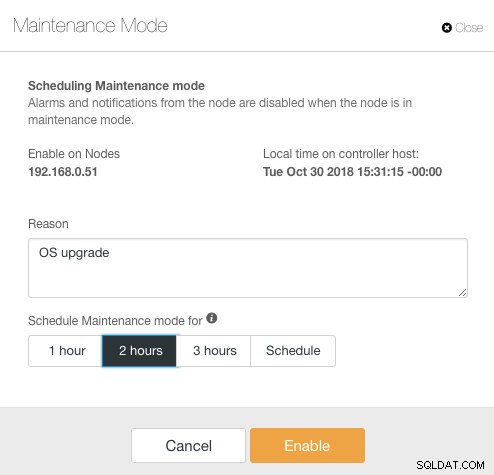
Di sini, seseorang dapat mengatur periode pemeliharaan untuk waktu yang telah ditentukan sebelumnya atau menjadwalkannya sesuai. Anda juga dapat menuliskan alasan untuk menjadwalkan peningkatan, berguna untuk tujuan audit. Anda akan melihat pemberitahuan berikut saat mode pemeliharaan aktif:
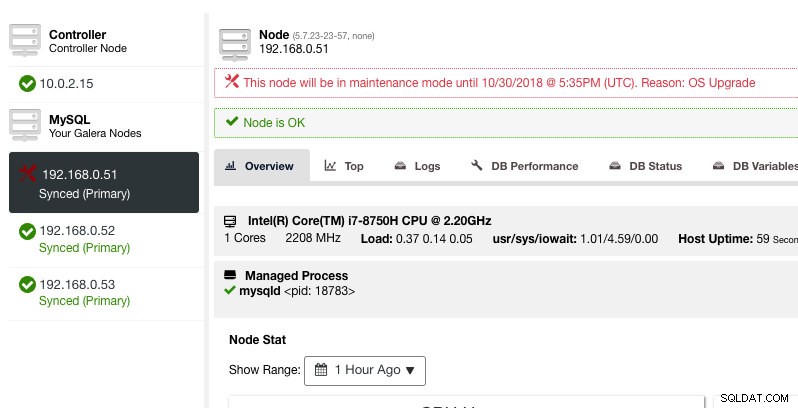
ClusterControl tidak akan menurunkan node, oleh karena itu status node tetap seperti apa adanya kecuali jika Anda melakukan tindakan apa pun yang mengubah status tersebut. Alarm dan notifikasi untuk node ini akan diaktifkan kembali setelah masa pemeliharaan berakhir, atau operator secara eksplisit menonaktifkannya dengan membuka Tindakan Node -> Nonaktifkan Mode Pemeliharaan .
Perhatikan bahwa jika pemulihan simpul otomatis diaktifkan, ClusterControl akan selalu memulihkan simpul terlepas dari status mode pemeliharaan. Jangan lupa untuk menonaktifkan pemulihan simpul untuk menghindari ClusterControl mengganggu tugas pemeliharaan Anda, ini dapat dilakukan dari bilah ringkasan atas.
Mode pemeliharaan juga dapat dikonfigurasi melalui ClusterControl CLI atau "s9s". Anda dapat menggunakan perintah "s9s maintenance" untuk membuat daftar dan memanipulasi periode pemeliharaan. Baris perintah berikut menjadwalkan jendela pemeliharaan satu jam untuk node 192.168.1.121 besok:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Untuk detail dan contoh selengkapnya, lihat dokumentasi pemeliharaan s9s.
Mode Pemeliharaan Seluruh Cluster
Pada saat penulisan ini, konfigurasi mode pemeliharaan harus dikonfigurasi per node yang dikelola. Untuk pemeliharaan cluster-lebar, kita harus mengulang proses penjadwalan untuk setiap node yang dikelola cluster. Ini bisa menjadi tidak praktis jika Anda memiliki jumlah node yang tinggi di cluster Anda, atau jika interval pemeliharaan sangat pendek antara dua tugas.
Untungnya, ClusterControl CLI (alias s9s) dapat digunakan sebagai solusi untuk mengatasi keterbatasan ini. Anda dapat menggunakan "s9s node" untuk membuat daftar dan memanipulasi node yang dikelola dalam sebuah cluster. Daftar ini dapat diulang untuk menjadwalkan mode pemeliharaan seluruh cluster pada satu waktu tertentu menggunakan perintah "s9s maintenance".
Mari kita lihat contoh untuk memahami ini lebih baik. Perhatikan Cluster Percona XtraDB tiga node berikut yang kita miliki:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Cluster memiliki total 4 node - 3 node database dengan satu node ClusterControl. Kolom pertama, STAT menunjukkan peran dan status node. Karakter pertama adalah peran simpul - "c" berarti pengontrol dan "g" berarti simpul basis data Galera. Misalkan kita ingin menjadwalkan hanya node database untuk pemeliharaan, kita dapat memfilter output untuk mendapatkan nama host atau alamat IP di mana STAT yang dilaporkan memiliki "g" di awal:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Dengan iterasi sederhana, kami kemudian dapat menjadwalkan jendela pemeliharaan di seluruh klaster untuk setiap node dalam klaster. Perintah berikut mengulangi pembuatan pemeliharaan berdasarkan semua alamat IP yang ditemukan di cluster menggunakan for loop, di mana kami berencana untuk memulai operasi pemeliharaan pada waktu yang sama besok dan selesai satu jam kemudian:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bAnda akan melihat cetakan 3 UUID, string unik yang mengidentifikasi setiap periode pemeliharaan. Kami kemudian dapat memverifikasi dengan perintah berikut:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Dari output di atas, kami mendapatkan daftar waktu pemeliharaan terjadwal untuk setiap node database. Selama waktu yang dijadwalkan, ClusterControl tidak akan membunyikan alarm atau mengirimkan pemberitahuan jika menemukan ketidakberesan pada cluster.
Iterasi Mode Pemeliharaan
Beberapa rutinitas pemeliharaan harus dilakukan secara berkala, misalnya, tugas pencadangan, pembersihan, dan pembersihan. Selama waktu pemeliharaan, kami mengharapkan server berperilaku berbeda. Namun, kegagalan layanan apa pun, tidak dapat diaksesnya sementara, atau beban tinggi pasti akan menyebabkan kerusakan pada sistem pemantauan kami. Untuk slot perawatan interval yang sering dan pendek, ini bisa menjadi sangat mengganggu dan melewatkan alarm palsu yang dimunculkan dapat membuat Anda tidur lebih nyenyak di malam hari.
Namun, mengaktifkan mode pemeliharaan juga dapat membuat server menghadapi risiko yang lebih besar karena pemantauan ketat diabaikan untuk jangka waktu tertentu. Oleh karena itu, mungkin ada baiknya untuk memahami sifat operasi pemeliharaan yang ingin kita lakukan sebelum mengaktifkan mode pemeliharaan. Daftar periksa berikut akan membantu kami menentukan kebijakan mode pemeliharaan kami:
- Node yang terpengaruh - Node mana yang terlibat dalam pemeliharaan?
- Konsekuensi - Apa yang terjadi pada node saat operasi pemeliharaan sedang berlangsung? Apakah tidak dapat diakses, dimuat tinggi, atau dimulai ulang?
- Durasi - Berapa lama waktu yang dibutuhkan untuk menyelesaikan operasi pemeliharaan?
- Frekuensi - Seberapa sering operasi pemeliharaan harus dijalankan?
Mari kita masukkan ke dalam use case. Pertimbangkan kita memiliki Cluster Percona XtraDB tiga node dengan node ClusterControl. Seharusnya server kami semua berjalan di mesin virtual dan kebijakan pencadangan VM mengharuskan semua VM dicadangkan setiap hari mulai dari pukul 1:00 pagi, satu node pada satu waktu. Selama operasi pencadangan ini, node akan dibekukan selama maksimal sekitar 10 menit dan node yang dikelola dan dipantau oleh ClusterControl tidak akan dapat diakses hingga pencadangan selesai. Dari perspektif Galera Cluster, operasi ini tidak menurunkan seluruh cluster karena cluster tetap dalam kuorum dan komponen utama tidak terpengaruh.
Berdasarkan sifat tugas pemeliharaan, kami dapat meringkasnya sebagai berikut:
- Node yang terpengaruh - Semua node untuk ID cluster 1 (3 node database dan 1 node ClusterControl).
- Konsekuensi - VM yang dicadangkan tidak dapat diakses hingga selesai.
- Durasi - Setiap operasi pencadangan VM membutuhkan waktu sekitar 5 hingga 10 menit untuk diselesaikan.
- Frekuensi - Pencadangan VM dijadwalkan untuk berjalan setiap hari, mulai dari pukul 01:00 pada node pertama.
Kami kemudian dapat membuat rencana eksekusi untuk menjadwalkan mode pemeliharaan kami:
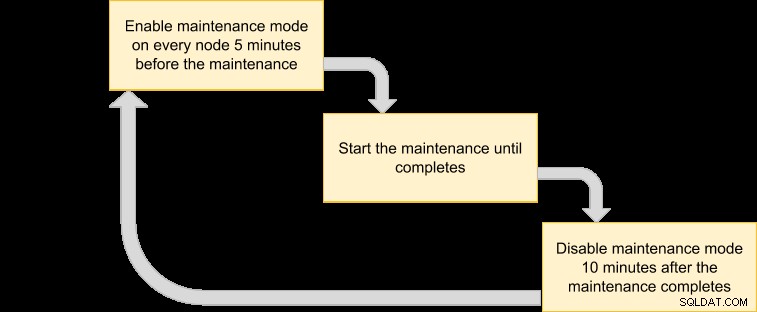
Karena kami ingin semua node dalam cluster dicadangkan oleh manajer VM, cukup cantumkan node untuk ID cluster yang sesuai:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53Output di atas dapat digunakan untuk menjadwalkan pemeliharaan di seluruh cluster. Misalnya, jika Anda menjalankan perintah berikut, ClusterControl akan mengaktifkan mode pemeliharaan untuk semua node di bawah ID cluster 1 mulai sekarang hingga 50 menit berikutnya:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneMenggunakan perintah di atas, kita dapat mengubahnya menjadi file eksekusi dengan memasukkannya ke dalam skrip. Buat file:
$ vim /usr/local/bin/enable_maintenance_modeDan tambahkan baris berikut:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneSimpan dan pastikan izin file dapat dieksekusi:
$ chmod 755 /usr/local/bin/enable_maintenance_modeKemudian gunakan cron untuk menjadwalkan skrip agar berjalan pada 5 menit hingga 01:00 setiap hari, tepat sebelum operasi pencadangan VM dimulai pada 01:00:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeMuat ulang daemon cron untuk memastikan skrip kita sedang diantrekan:
$ systemctl reload crond # or service crond reloadItu dia. Kami sekarang dapat melakukan operasi pemeliharaan harian tanpa disadap oleh alarm palsu dan pemberitahuan email hingga pemeliharaan selesai.
Fitur Pemeliharaan Bonus - Melewatkan Pemulihan Node
Dengan pemulihan otomatis diaktifkan, ClusterControl cukup pintar untuk mendeteksi kegagalan node dan akan mencoba memulihkan node yang gagal setelah masa tenggang 30 detik, terlepas dari status mode pemeliharaan. Tahukah Anda bahwa ClusterControl dapat dikonfigurasi untuk secara sengaja melewatkan pemulihan node untuk node tertentu? Ini bisa sangat membantu saat Anda harus melakukan perawatan darurat tanpa mengetahui rentang waktu dan hasil perawatan.
Misalnya, bayangkan korupsi sistem file terjadi dan pemeriksaan dan perbaikan sistem file diperlukan setelah hard reboot. Sulit untuk menentukan sebelumnya berapa banyak waktu yang dibutuhkan untuk menyelesaikan operasi ini. Jadi, kita cukup menggunakan file flag untuk memberi sinyal kepada ClusterControl agar melewati pemulihan untuk node.
Pertama, tambahkan baris berikut di dalam /etc/cmon.d/cmon_X.cnf (di mana X adalah ID cluster) pada node ClusterControl:
node_recovery_lock_file=/root/do_not_recoverKemudian, restart layanan cmon untuk memuat perubahan:
$ systemctl restart cmon # service cmon restartTerakhir, pastikan file yang ditentukan ada di node yang ingin kita lewati untuk pemulihan ClusterControl:
$ touch /root/do_not_recoverTerlepas dari status mode pemulihan dan pemeliharaan otomatis, ClusterControl hanya akan memulihkan node ketika file flag ini tidak ada. Administrator kemudian bertanggung jawab untuk membuat dan menghapus file pada node database.
Itu saja, orang-orang. Selamat memelihara!



