Cadangan - salah satu hal terpenting yang harus diperhatikan saat mengelola basis data. Dikatakan ada dua jenis orang - mereka yang membuat cadangan data mereka dan mereka yang akan membuat cadangan data mereka. Dalam posting blog ini, kita akan membahas praktik yang baik seputar pencadangan dan menunjukkan kepada Anda bagaimana Anda dapat membangun sistem pencadangan yang andal menggunakan ClusterControl.
Kami akan melihat bagaimana ClusterControl memberi Anda manajemen cadangan terpusat untuk MySQL, MariaDB, MongoDB, dan PostgreSQL. Ini memberi Anda cadangan panas dari kumpulan data besar, pemulihan titik waktu, enkripsi data saat istirahat dan dalam perjalanan, integritas data melalui verifikasi pemulihan otomatis, cadangan cloud (AWS, Google dan Azure) untuk Pemulihan Bencana, kebijakan penyimpanan untuk memastikan kepatuhan , dan lansiran serta pelaporan otomatis.
Jenis cadangan
Ada dua jenis pencadangan utama yang dapat kita lakukan di ClusterControl:
- Pencadangan logis - pencadangan data disimpan dalam format yang dapat dibaca manusia seperti SQL
- Cadangan fisik - cadangan berisi data biner
Keduanya saling melengkapi - pencadangan logis memungkinkan Anda (kurang lebih dengan mudah) mengambil hingga satu baris data. Pencadangan fisik memerlukan lebih banyak waktu untuk melakukannya, tetapi, di sisi lain, pencadangan memungkinkan Anda memulihkan seluruh host dengan sangat cepat (sesuatu yang mungkin memerlukan waktu berjam-jam atau bahkan berhari-hari bila menggunakan pencadangan logis).
ClusterControl mendukung pencadangan untuk Server MySQL/MariaDB/Percona, PostgreSQL, dan MongoDB.
Jadwalkan Pencadangan
Memulai pencadangan di ClusterControl sederhana dan efisien menggunakan wizard. Menjadwalkan pencadangan menawarkan kemudahan pengguna dan aksesibilitas ke fitur lain seperti enkripsi, pengujian/verifikasi pencadangan otomatis, atau pengarsipan awan.
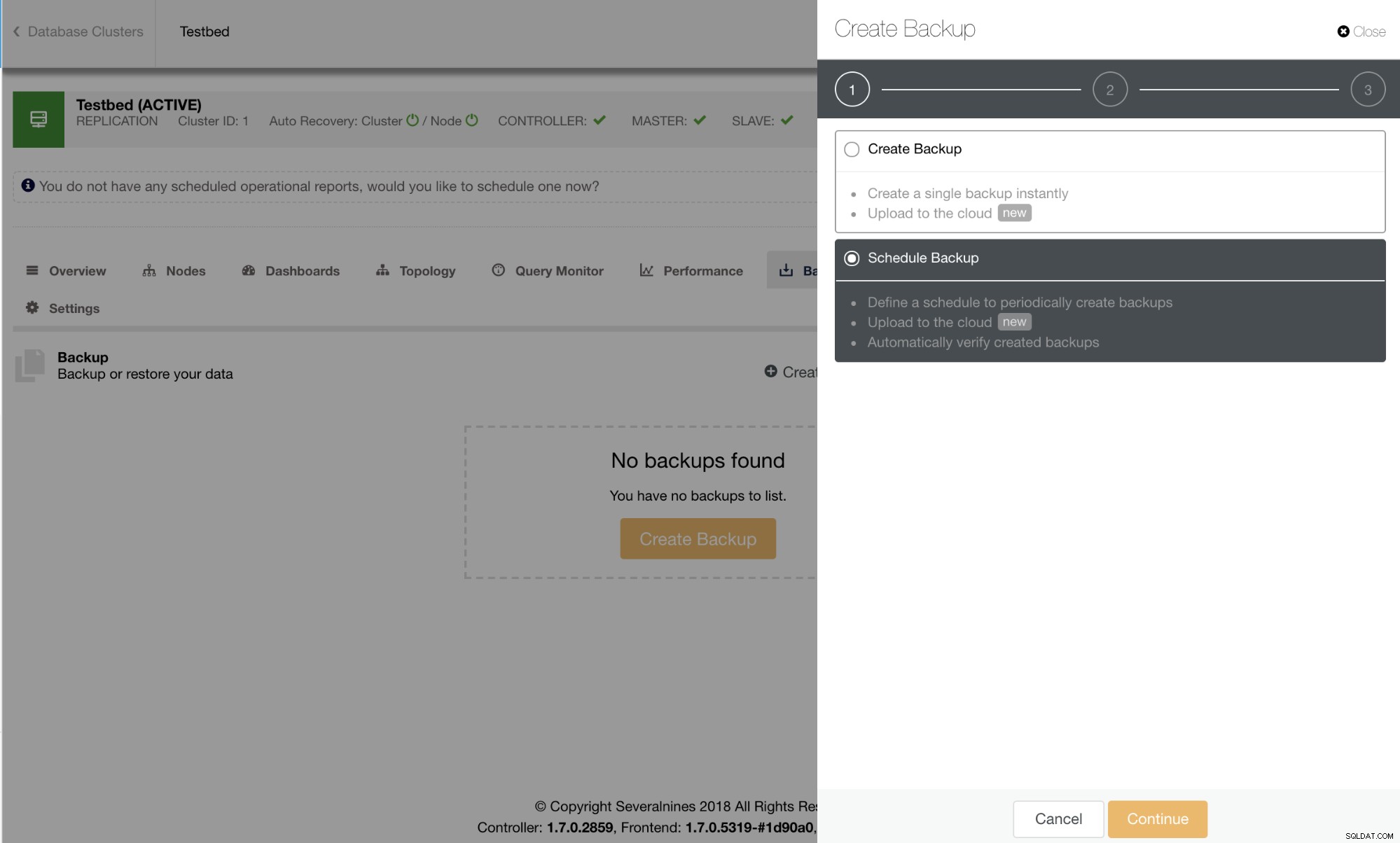
Pencadangan terjadwal yang tersedia akan dicantumkan di tab Pencadangan Terjadwal seperti yang terlihat pada gambar di bawah ini:
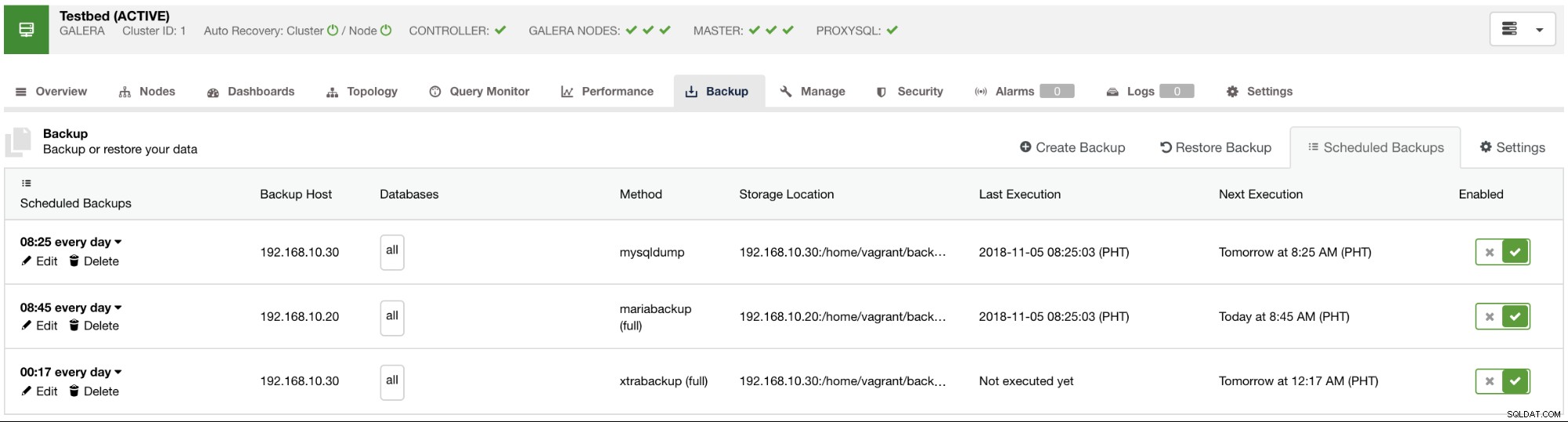
Sebagai praktik yang baik untuk menjadwalkan pencadangan, Anda harus sudah memiliki retensi cadangan yang ditentukan dan pencadangan harian direkomendasikan. Namun, itu juga tergantung pada data yang Anda butuhkan, lalu lintas yang mungkin Anda harapkan dan ketersediaan data kapan pun Anda membutuhkannya, terutama selama pemulihan data di mana data terhapus secara tidak sengaja atau kerusakan disk - yang tidak dapat dihindari. Ada juga situasi di mana kehilangan data dapat direproduksi atau dapat diduplikasi secara manual seperti misalnya, pembuatan laporan, gambar mini, atau data yang di-cache. Meskipun pertanyaannya bergantung pada seberapa cepat Anda membutuhkannya setiap kali terjadi bencana; jika memungkinkan, Anda ingin mengambil cadangan mysqldump dan xtrabackup setiap hari untuk MySQL dengan memanfaatkan ketersediaan cadangan logis dan fisik. Untuk mencakup lebih banyak basis, Anda mungkin ingin menjadwalkan beberapa operasi xtrabackup inkremental per hari. Ini dapat menghemat beberapa ruang disk, I/O disk, atau bahkan I/O CPU daripada mengambil cadangan penuh.
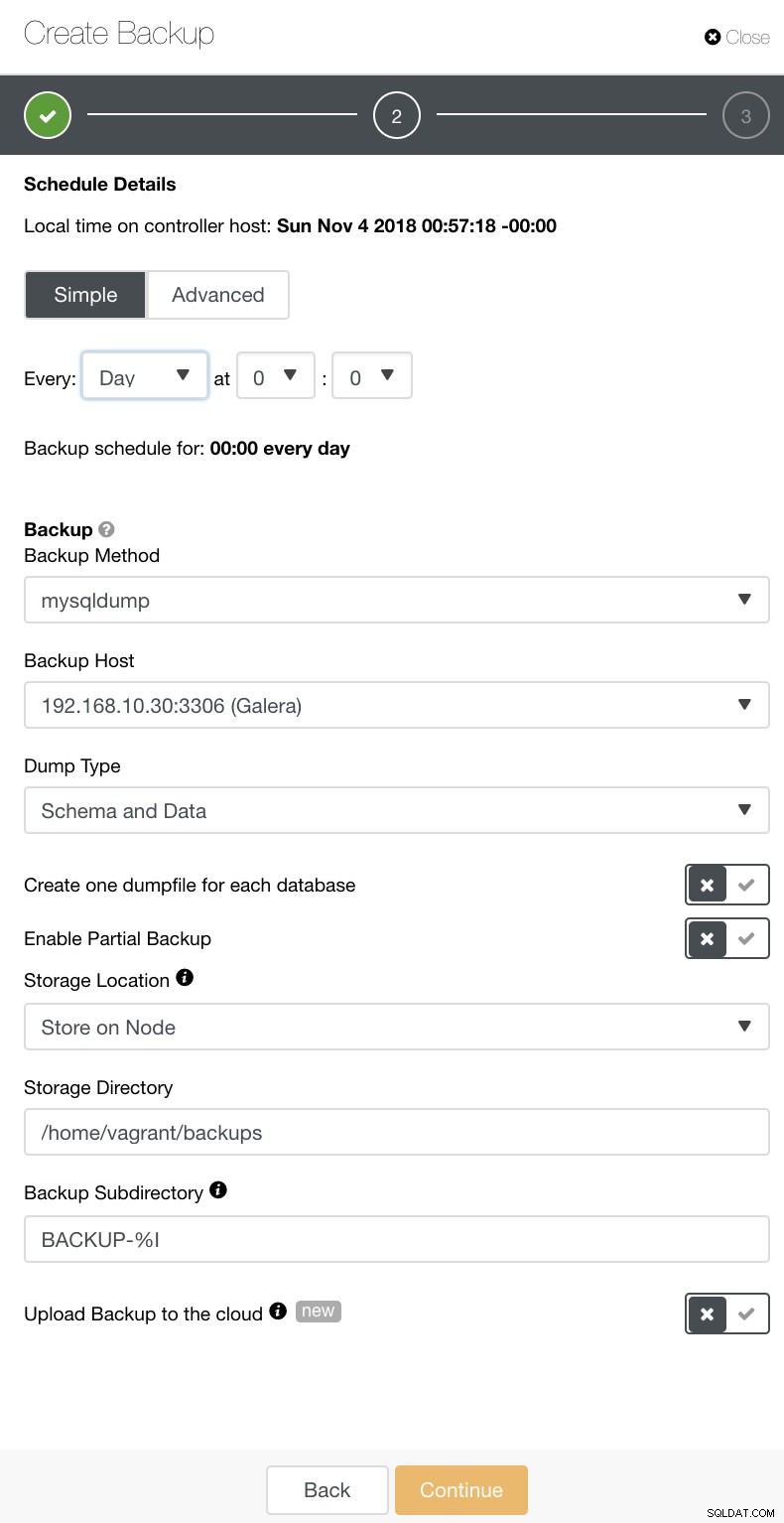
Di ClusterControl, Anda dapat dengan mudah menjadwalkan berbagai jenis pencadangan ini. Ada beberapa pengaturan untuk diputuskan. Anda dapat menyimpan cadangan di pengontrol atau secara lokal, di node basis data tempat cadangan diambil. Anda perlu memutuskan lokasi penyimpanan cadangan, dan basis data mana yang ingin Anda cadangkan--semua kumpulan data atau skema terpisah? Lihat gambar di bawah ini:
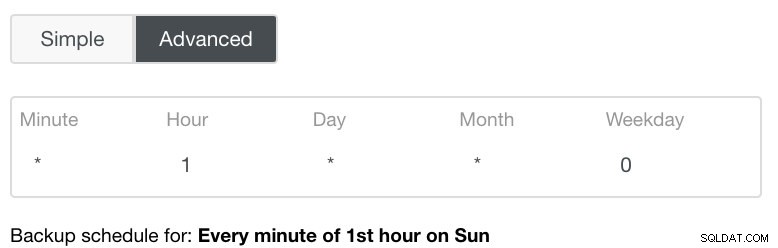
Pengaturan Lanjutan akan memanfaatkan konfigurasi seperti cron untuk perincian yang lebih banyak. Lihat gambar di bawah ini:
Setiap kali terjadi kegagalan, ClusterControl menangani masalah ini secara efisien dan menghasilkan log untuk diagnosis lebih lanjut dari kegagalan pencadangan.
Tergantung pada jenis cadangan yang Anda pilih, ada pengaturan terpisah untuk dikonfigurasi. Untuk Xtrabackup dan Galera Cluster, Anda mungkin memiliki opsi untuk memilih pengaturan yang akan diterapkan pada cadangan fisik Anda saat dijalankan. Lihat di bawah:
- Gunakan Kompresi
- Tingkat Kompresi
- Desinkronkan simpul selama pencadangan
- Kunci Cadangan
- Kunci DDL per Tabel
- Utas Salinan Paralel Xtrabackup
- Kecepatan Aliran Jaringan (MB/dtk)
- Gunakan PIGZ untuk gzip paralel
- Aktifkan Enkripsi
- Retensi
Anda dapat melihat, pada gambar di bawah, bagaimana Anda dapat menandai opsi yang sesuai dan ada ikon tooltip yang memberikan lebih banyak informasi tentang opsi yang ingin Anda manfaatkan untuk kebijakan pencadangan Anda.
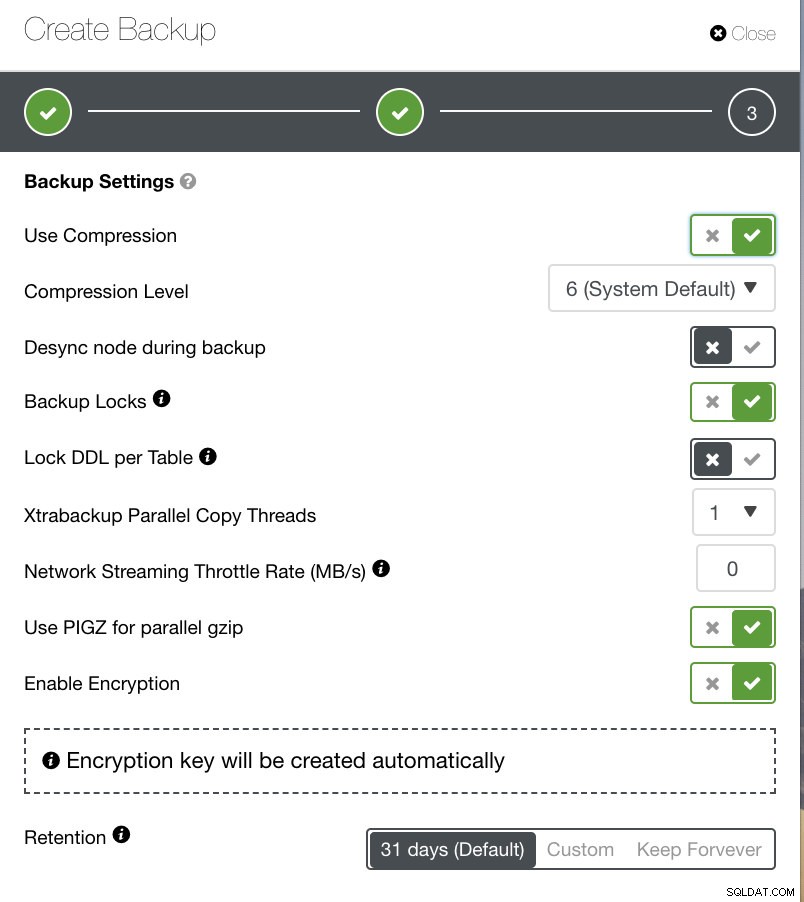
Bergantung pada kebijakan pencadangan Anda, ClusterControl dapat disesuaikan sesuai dengan praktik terbaik untuk mengambil cadangan Anda yang tersedia terkini. Setelah menentukan kebijakan pencadangan, Anda harus menyiapkan penyiapan yang diperlukan dari perangkat keras hingga perangkat lunak hingga cloud, daya tahan, ketersediaan tinggi, atau skalabilitas.
Saat mengambil cadangan di Galera Cluster, praktik yang baik adalah menyetel simpul Galera wsrep_desync=ON saat pencadangan sedang berjalan. Ini akan membuat node tidak berpartisipasi dalam Flow Control dan akan melindungi seluruh cluster dari jeda replikasi, terutama jika data Anda yang akan dicadangkan berukuran besar. Di ClusterControl, harap diingat bahwa ini juga dapat menghapus node cadangan target Anda dari set penyeimbangan beban. Ini terutama benar jika Anda menggunakan proxy HAProxy, ProxySQL, atauMaxScale. Jika Anda telah menyiapkan pengelola peringatan jika node tidak disinkronkan, Anda dapat menonaktifkannya selama periode tersebut saat pencadangan telah dipicu.
Cara populer lainnya untuk meminimalkan dampak pencadangan pada Galera Cluster atau master replikasi adalah dengan menyebarkan slave replikasi dan kemudian menggunakannya sebagai sumber cadangan - dengan cara ini Galera Cluster tidak akan terpengaruh pada titik mana pun karena cadangan pada slave dipisahkan dari cluster.
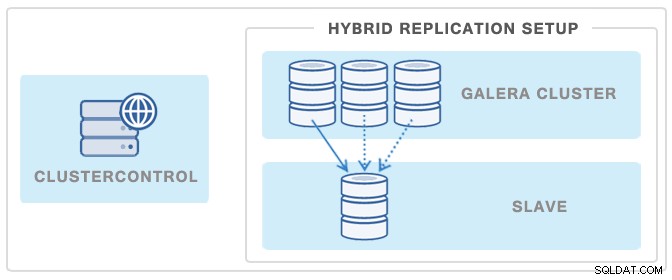
Anda dapat menyebarkan budak seperti itu hanya dalam beberapa klik menggunakan ClusterControl. Lihat gambar di bawah ini:
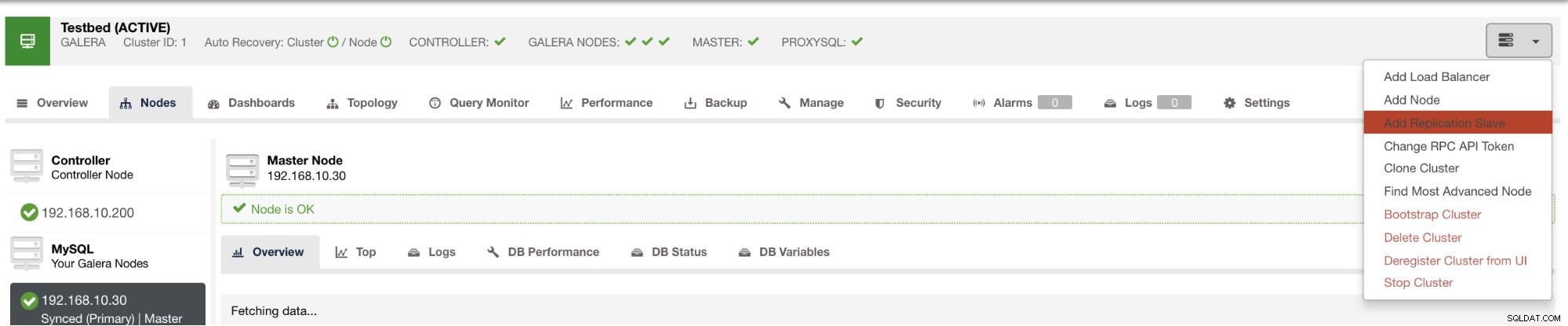
dan setelah Anda mengklik tombol itu, Anda dapat memilih node mana yang akan dipasangi budak. Pastikan logging biner node diaktifkan. Mengaktifkan log biner juga dapat dilakukan melalui ClusterControl yang menambahkan lebih banyak kelayakan untuk mengelola master yang Anda inginkan. Lihat gambar di bawah ini:
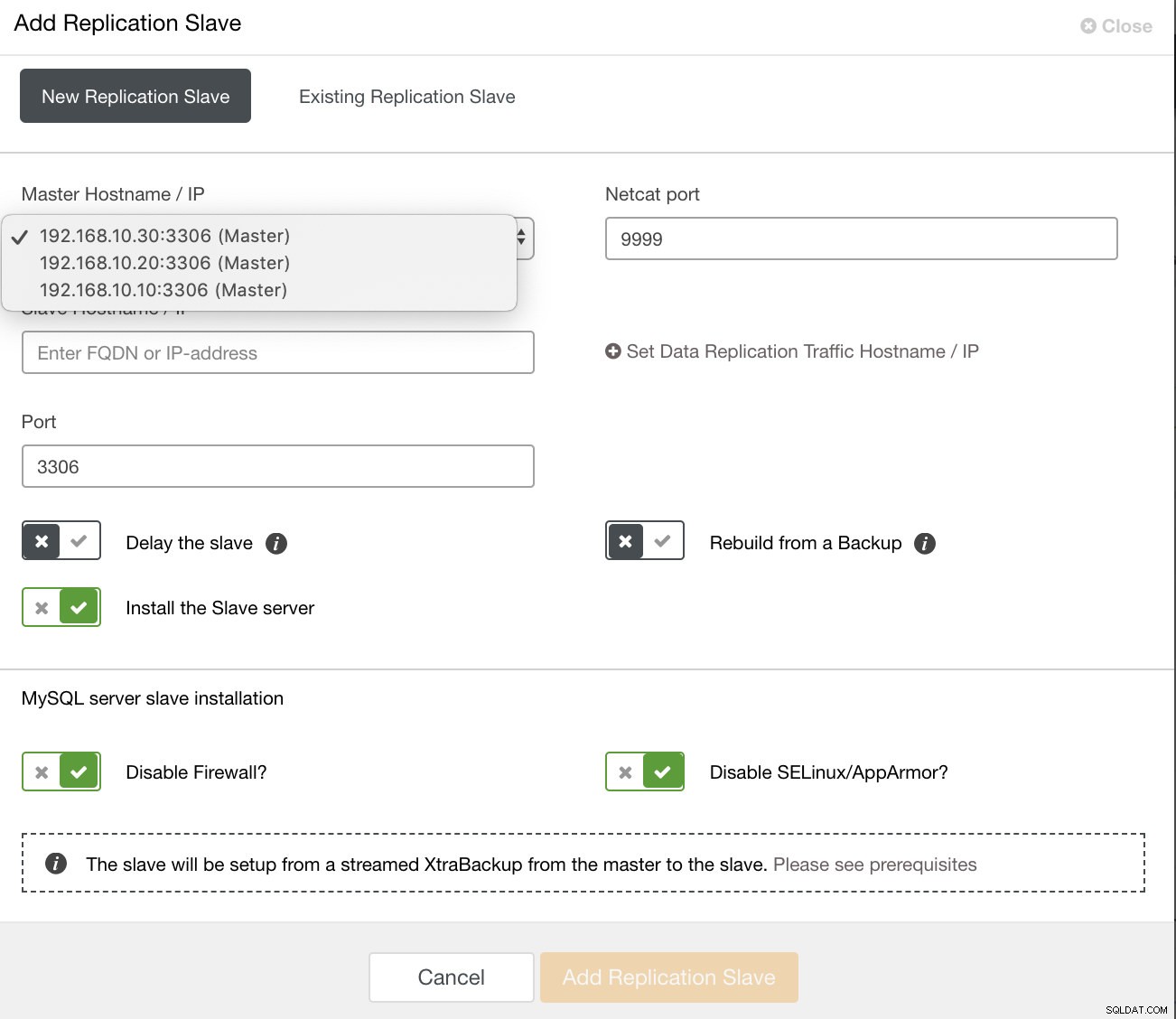
dan Anda juga dapat mengatur budak replikasi yang ada,
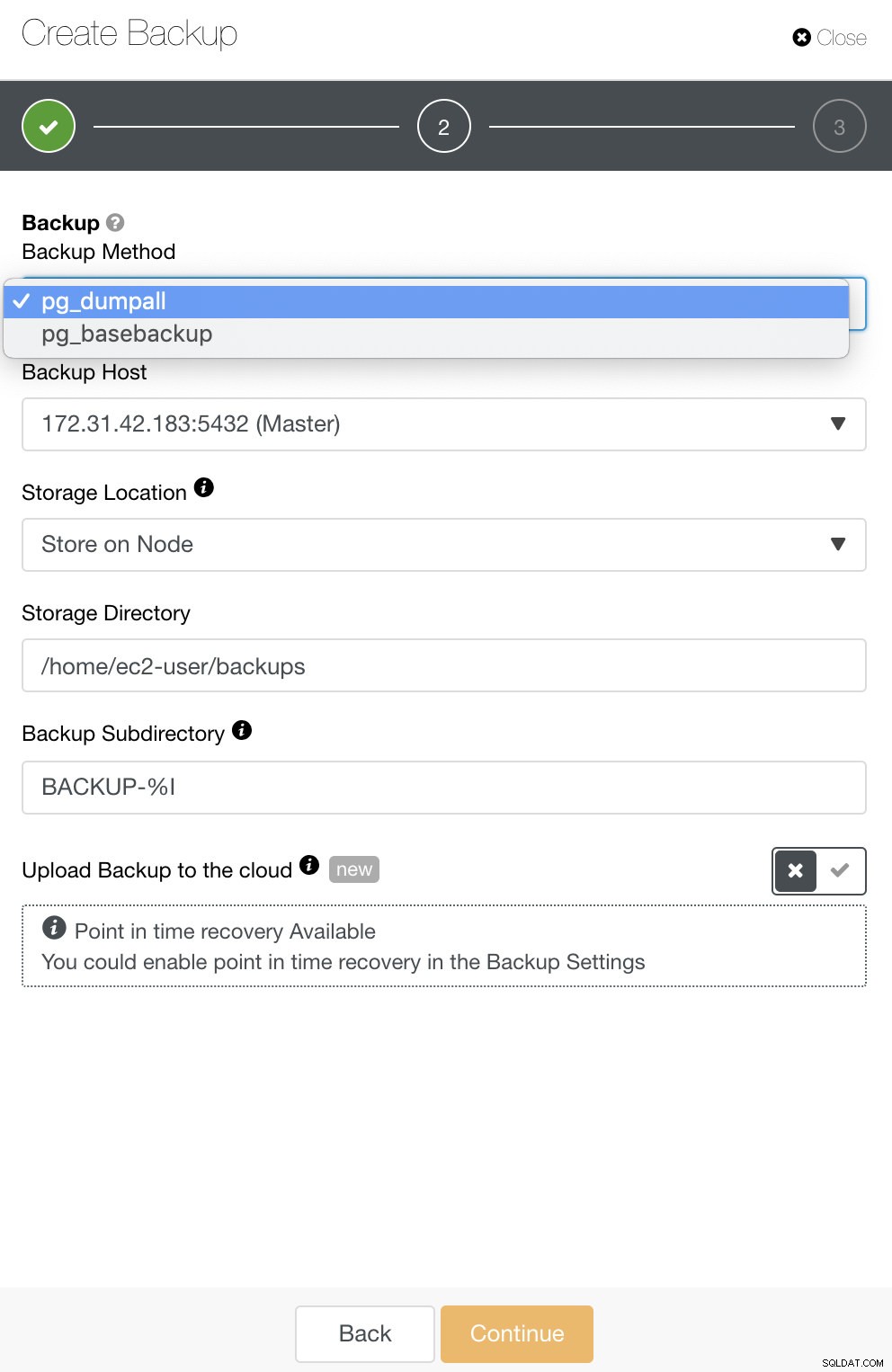
Untuk PostgreSQL, Anda memiliki opsi untuk mencadangkan cadangan logis atau fisik. Di ClusterControl, Anda dapat memanfaatkan cadangan PostgreSQL Anda dengan memilih pg_dump atau pg_basebackup. pg_basebackup tidak akan berfungsi untuk versi yang lebih lama dari 9.3.
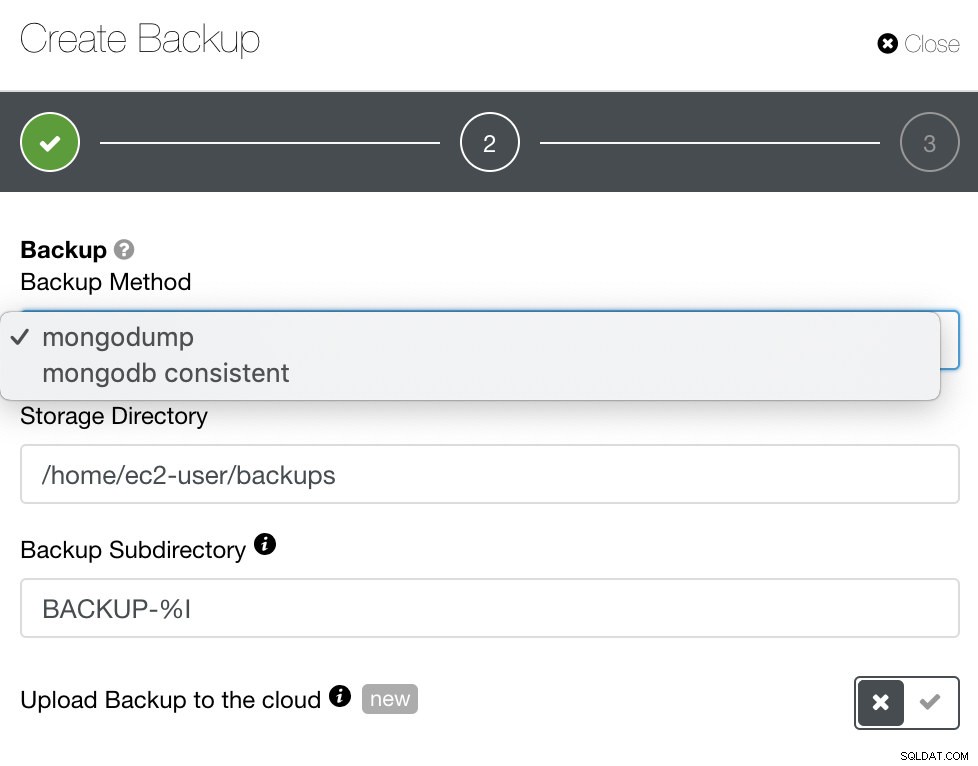
Untuk MongoDB, ClusterControl menawarkan mongodump atau mongodb yang konsisten. Anda mungkin harus memperhatikan bahwa mongodb konsisten tidak mendukung RHEL 7 tetapi Anda mungkin dapat menginstalnya secara manual.
Secara default, ClusterControl akan mencantumkan laporan untuk semua cadangan yang telah diambil, yang berhasil atau yang gagal. Lihat di bawah:
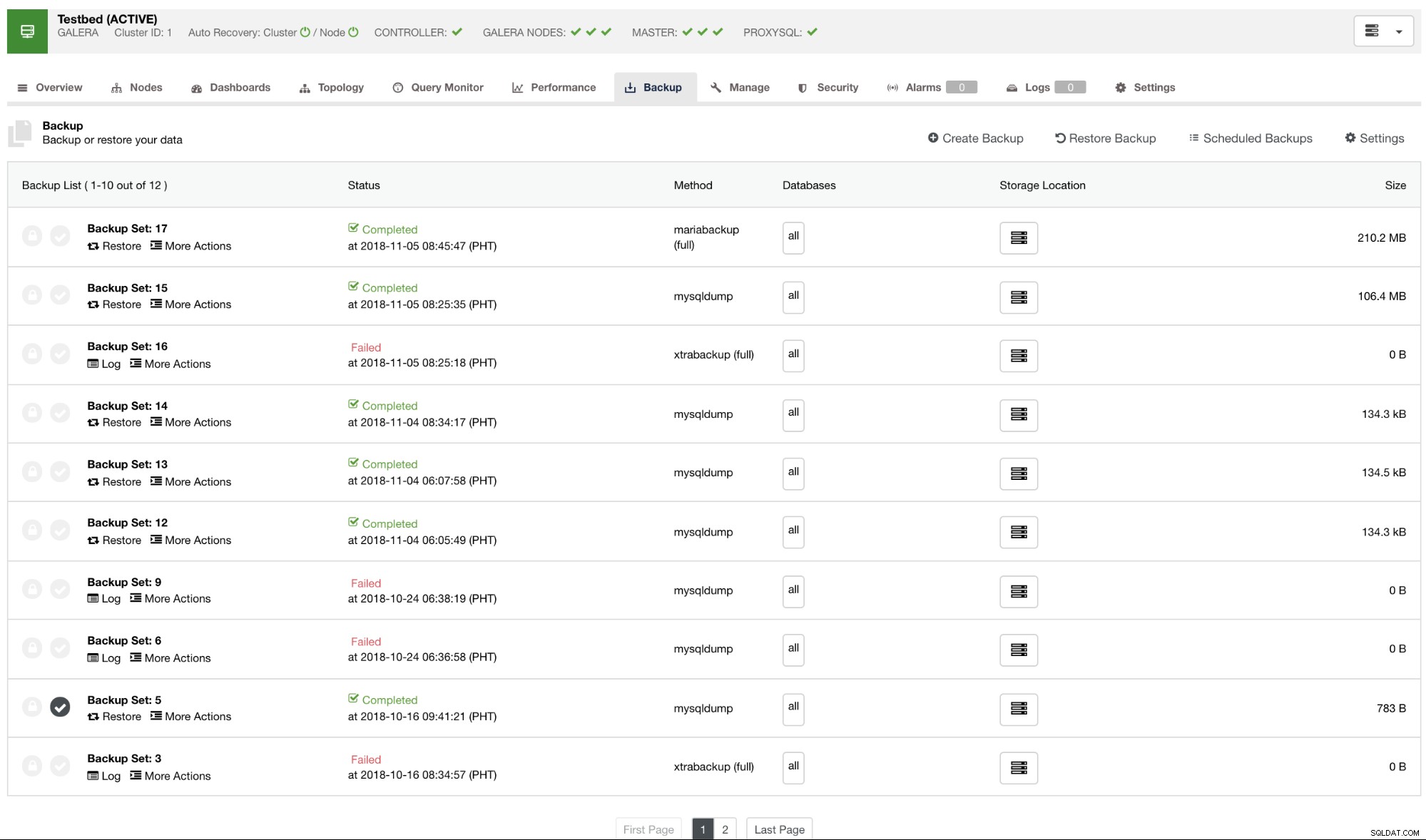
Anda dapat memeriksa daftar laporan cadangan yang telah dibuat atau dijadwalkan menggunakan ClusterControl. Dalam daftar, Anda dapat melihat log untuk penyelidikan dan diagnosis lebih lanjut. Misalnya, jika pencadangan selesai dengan benar sesuai dengan kebijakan pencadangan yang Anda inginkan, apakah kompresi dan enkripsi diatur dengan benar, atau jika ukuran data cadangan yang diinginkan sudah benar. Ini adalah cara yang baik untuk melakukan pemeriksaan kewarasan dengan cepat - jika kumpulan data Anda berukuran sekitar 1 GB, tidak mungkin cadangan penuh dapat sekecil 100 KB - pasti ada yang salah di beberapa titik.
Pemulihan Bencana
Menyimpan cadangan di dalam cluster (baik secara langsung pada node database atau di host ClusterControl) sangat berguna ketika Anda ingin memulihkan data dengan cepat:semua file cadangan sudah ada dan dapat didekompresi dan dipulihkan segera. Ketika datang ke Disaster Recovery (DR), ini mungkin bukan pilihan terbaik. Masalah yang berbeda mungkin terjadi - server mungkin macet, jaringan mungkin tidak berfungsi dengan baik, bahkan seluruh pusat data mungkin tidak dapat diakses karena beberapa jenis pemadaman. Ini mungkin terjadi baik Anda bekerja dengan penyedia layanan yang lebih kecil dengan satu pusat data, atau vendor global seperti Amazon Web Services. Oleh karena itu, tidak aman untuk menyimpan semua telur Anda dalam satu keranjang - Anda harus memastikan bahwa Anda memiliki salinan cadangan yang disimpan di beberapa lokasi eksternal. ClusterControl mendukung Amazon S3, Google Storage, dan Azure Cloud Storage .
Bagi mereka yang ingin menerapkan kebijakan DR mereka sendiri, cadangan ClusterControl disimpan dalam direktori yang terstruktur dengan baik. Anda juga memiliki opsi untuk mengunggah cadangan Anda ke cloud. Lihat gambar di bawah ini:
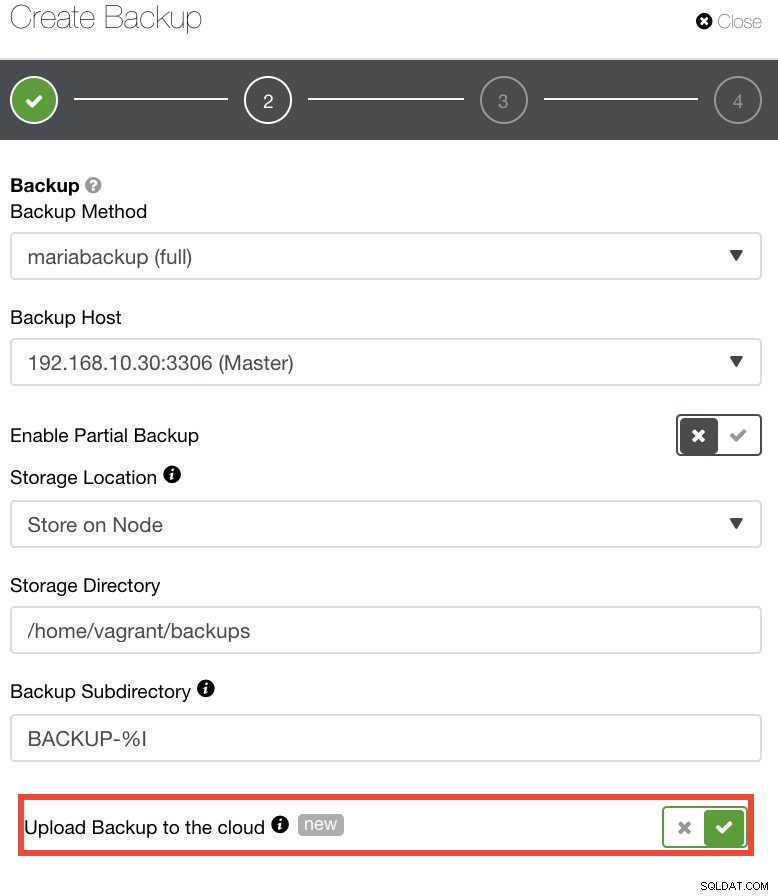
Anda dapat memilih dan mengunggah ke Amazon Web Services, Google Cloud, dan Microsoft Azure. Lihat gambar di bawah ini:
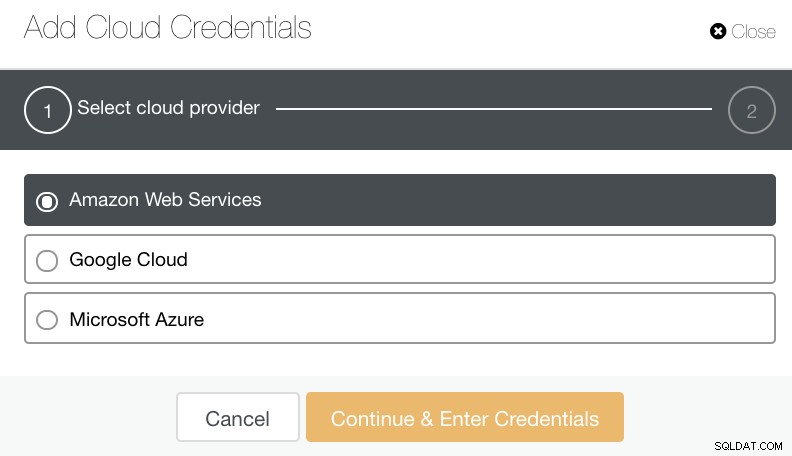
Sebagai praktik yang baik saat mengarsipkan cadangan basis data Anda, pastikan bahwa tujuan cloud target Anda didasarkan pada wilayah yang sama dengan server basis data Anda, atau setidaknya yang terdekat. Pastikan bahwa ia menawarkan ketersediaan tinggi, daya tahan, dan skalabilitas; karena Anda harus mempertimbangkan seberapa sering dan segera apakah Anda memerlukan data Anda.
Selain membuat cadangan logis atau fisik untuk DR Anda, membuat snapshot lengkap dari data Anda (misalnya menggunakan LVM Snapshot, Amazon EBS Snapshots, atau Volume Snapshots jika menggunakan sistem file Veritas) pada node tertentu dapat meningkatkan pemulihan cadangan Anda. Anda juga dapat menggunakan WAL (untuk Postgres) untuk Point In Time Recovery (PITR) atau log biner MySQL untuk PITR Anda. Jadi, Anda harus mempertimbangkan bahwa Anda mungkin perlu membuat pengarsipan sendiri untuk PITR Anda. Jadi, tidak masalah untuk membuat dan menerapkan kumpulan skrip Anda sendiri dan menangani DR sesuai dengan kebutuhan Anda.
Cara hebat lainnya untuk menerapkan kebijakan Pemulihan Bencana adalah dengan menggunakan budak replikasi asinkron - sesuatu yang kami sebutkan sebelumnya di posting blog ini. Anda dapat menyebarkan budak asinkron seperti itu di lokasi yang jauh, beberapa pusat data lain mungkin, dan kemudian menggunakannya untuk melakukan pencadangan dan menyimpannya secara lokal di budak itu. Tentu saja, Anda ingin mengambil cadangan lokal kluster Anda untuk memilikinya secara lokal jika Anda perlu memulihkan kluster. Memindahkan data antar pusat data mungkin memakan waktu lama, sehingga memiliki file cadangan yang tersedia secara lokal dapat menghemat waktu Anda. Jika Anda kehilangan akses ke cluster produksi utama, Anda mungkin masih memiliki akses ke slave. Pengaturan ini sangat fleksibel - pertama, Anda memiliki host MySQL yang sedang berjalan dengan data produksi Anda sehingga tidak akan terlalu sulit untuk menerapkan aplikasi lengkap Anda di situs DR. Anda juga akan memiliki cadangan data produksi yang dapat digunakan untuk meningkatkan skala lingkungan DR Anda.
Terakhir dan yang terpenting, backup yang belum dicoba tetaplah backup yang belum terverifikasi alias Schroedinger Backup. Untuk memastikan Anda memiliki cadangan yang berfungsi, Anda perlu melakukan tes pemulihan. ClusterControl menawarkan cara untuk memverifikasi dan menguji cadangan Anda secara otomatis.
Kami harap ini memberi Anda informasi yang cukup untuk membangun prosedur pencadangan yang aman dan andal untuk basis data sumber terbuka Anda.



