Efisiensi database tidak hanya bergantung pada penyetelan parameter yang paling penting, tetapi juga lebih jauh ke penyajian data yang sesuai dalam koleksi terkait. Baru-baru ini, saya mengerjakan sebuah proyek yang mengembangkan aplikasi obrolan sosial, dan setelah beberapa hari pengujian, kami melihat beberapa kelambatan saat mengambil data dari database. Kami tidak memiliki begitu banyak pengguna, jadi kami mengesampingkan penyetelan parameter database dan fokus pada kueri kami untuk sampai ke akar masalah.
Yang mengejutkan kami, kami menyadari bahwa penataan data kami tidak sepenuhnya sesuai karena kami memiliki lebih dari 1 permintaan baca untuk mengambil beberapa informasi tertentu.
Model konseptual tentang bagaimana bagian aplikasi ditempatkan sangat tergantung pada struktur koleksi database. Misalnya, jika Anda masuk ke aplikasi sosial, data dimasukkan ke bagian yang berbeda sesuai dengan desain aplikasi seperti yang digambarkan dari presentasi basis data.
Singkatnya, untuk database yang dirancang dengan baik, struktur skema dan hubungan koleksi adalah hal utama menuju peningkatan kecepatan dan integritasnya seperti yang akan kita lihat di bagian berikut.
Kami akan membahas faktor-faktor yang harus Anda pertimbangkan saat memodelkan data Anda.
Apa itu Pemodelan Data
Pemodelan data umumnya merupakan analisis item data dalam database dan bagaimana keterkaitannya dengan objek lain dalam database tersebut.
Di MongoDB misalnya, kita dapat memiliki koleksi pengguna dan koleksi profil. Koleksi pengguna mencantumkan nama pengguna untuk aplikasi tertentu sedangkan koleksi profil menangkap pengaturan profil untuk setiap pengguna.
Dalam pemodelan data, kita perlu merancang hubungan untuk menghubungkan setiap pengguna ke profil koresponden. Singkatnya, pemodelan data adalah langkah mendasar dalam desain database selain membentuk dasar arsitektur untuk pemrograman berorientasi objek. Ini juga memberikan petunjuk tentang bagaimana aplikasi fisik akan terlihat selama kemajuan pengembangan. Arsitektur integrasi database-aplikasi dapat diilustrasikan seperti di bawah ini.
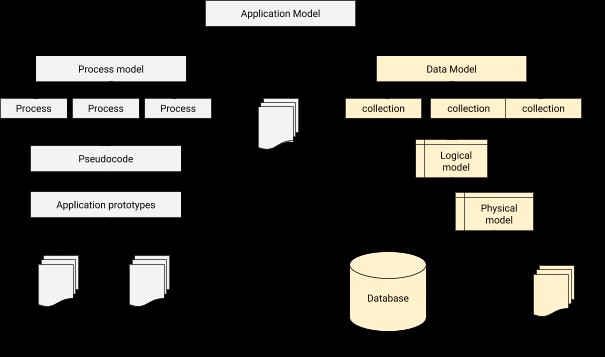
Proses Pemodelan Data di MongoDB
Pemodelan data dilengkapi dengan peningkatan kinerja basis data, tetapi dengan mengorbankan beberapa pertimbangan yang meliputi:
- Pola pengambilan data
- Menyeimbangkan kebutuhan aplikasi seperti:kueri, pembaruan, dan pemrosesan data
- Fitur kinerja mesin database yang dipilih
- Struktur bawaan dari data itu sendiri
Struktur Dokumen MongoDB
Dokumen di MongoDB memainkan peran utama dalam pengambilan keputusan tentang teknik mana yang akan diterapkan untuk kumpulan data tertentu. Secara umum ada dua hubungan antar data, yaitu:
- Data Tersemat
- Data Referensi
Data Tersemat
Dalam hal ini, data terkait disimpan dalam satu dokumen baik sebagai nilai bidang atau larik di dalam dokumen itu sendiri. Keuntungan utama dari pendekatan ini adalah bahwa data didenormalisasi dan oleh karena itu memberikan kesempatan untuk memanipulasi data terkait dalam operasi database tunggal. Akibatnya, ini meningkatkan tingkat di mana operasi CRUD dilakukan, maka lebih sedikit kueri yang diperlukan. Mari kita perhatikan contoh dokumen di bawah ini:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}Dalam kumpulan data ini, kami memiliki seorang siswa dengan namanya dan beberapa informasi tambahan lainnya. Bidang Pengaturan telah disematkan dengan objek dan selanjutnya bidang tempatLokasi juga disematkan dengan objek dengan konfigurasi garis lintang dan garis bujur. Semua data untuk siswa ini telah dimuat dalam satu dokumen. Jika kami perlu mengambil semua informasi untuk siswa ini, kami hanya menjalankan:
db.students.findOne({StudentName : "George Beckonn"})Kekuatan Penyematan
- Peningkatan kecepatan akses data:Untuk tingkat akses yang lebih baik ke data, penyematan adalah opsi terbaik karena satu operasi kueri dapat memanipulasi data dalam dokumen yang ditentukan hanya dengan satu pencarian basis data.
- Mengurangi inkonsistensi data:Selama pengoperasian, jika terjadi kesalahan (misalnya pemutusan jaringan atau kegagalan daya) hanya beberapa dokumen yang mungkin terpengaruh karena kriteria sering kali memilih satu dokumen.
- Mengurangi operasi CRUD. Artinya, operasi baca sebenarnya akan melebihi jumlah penulisan. Selain itu, dimungkinkan untuk memperbarui data terkait dalam satu operasi penulisan atom. Yaitu untuk data di atas, kita dapat memperbarui nomor telepon dan juga meningkatkan jarak dengan operasi tunggal ini:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Kelemahan Penyematan
- Ukuran dokumen terbatas. Semua dokumen di MongoDB dibatasi ke ukuran BSON 16 megabyte. Oleh karena itu, ukuran dokumen keseluruhan bersama dengan data yang disematkan tidak boleh melebihi batas ini. Jika tidak, untuk beberapa mesin penyimpanan seperti MMAPv1, data dapat bertambah banyak dan mengakibatkan fragmentasi data sebagai akibat dari penurunan kinerja penulisan.
- Duplikasi data:banyak salinan dari data yang sama mempersulit kueri data yang direplikasi dan mungkin memerlukan waktu lebih lama untuk memfilter dokumen yang disematkan, sehingga mengalahkan keuntungan inti dari penyematan.
Notasi Titik
Notasi titik adalah fitur pengidentifikasi untuk data yang disematkan di bagian pemrograman. Ini digunakan untuk mengakses elemen bidang yang disematkan atau larik. Pada contoh data di atas, kita dapat mengembalikan informasi siswa yang lokasinya “Kedutaan” dengan query ini menggunakan notasi titik.
db.users.find({'Settings.location': 'Embassy'})Data Referensi
Hubungan data dalam hal ini adalah data terkait disimpan dalam dokumen yang berbeda, tetapi beberapa tautan referensi dikeluarkan untuk dokumen terkait ini. Untuk contoh data di atas kita dapat merekonstruksinya sedemikian rupa sehingga:
Dokumen pengguna
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Dokumen pengaturan
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Ada 2 dokumen yang berbeda, tetapi mereka ditautkan dengan nilai yang sama untuk bidang _id dan id. Model data dengan demikian dinormalisasi. Namun, bagi kami untuk mengakses informasi dari dokumen terkait, kami perlu mengeluarkan kueri tambahan dan akibatnya ini menghasilkan peningkatan waktu eksekusi. Misalnya, jika kami ingin memperbarui ParentPhone dan pengaturan jarak terkait, kami akan memiliki setidaknya 3 kueri yaitu
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Kekuatan Referensi
- Konsistensi data. Untuk setiap dokumen, formulir kanonik dipertahankan sehingga kemungkinan ketidakkonsistenan data cukup kecil.
- Integritas data yang ditingkatkan. Karena normalisasi, mudah untuk memperbarui data terlepas dari panjang durasi operasi dan oleh karena itu memastikan data yang benar untuk setiap dokumen tanpa menimbulkan kebingungan.
- Peningkatan pemanfaatan cache. Dokumen kanonik yang sering diakses disimpan dalam cache daripada untuk dokumen tersemat yang diakses beberapa kali.
- Penggunaan perangkat keras yang efisien. Berlawanan dengan penyematan, yang dapat menyebabkan dokumen terlalu besar, referensi tidak mendorong pertumbuhan dokumen sehingga mengurangi penggunaan disk dan RAM.
- Meningkatkan fleksibilitas terutama dengan sekumpulan besar subdokumen.
- Menulis lebih cepat.
Kelemahan Referensi
- Beberapa pencarian:Karena kita harus melihat sejumlah dokumen yang sesuai dengan kriteria, ada peningkatan waktu baca saat mengambil dari disk. Selain itu, hal ini dapat mengakibatkan hilangnya cache.
- Banyak kueri dikeluarkan untuk mencapai beberapa operasi sehingga model data yang dinormalisasi memerlukan lebih banyak perjalanan pulang pergi ke server untuk menyelesaikan operasi tertentu.
Normalisasi Data
Normalisasi data mengacu pada restrukturisasi database sesuai dengan beberapa bentuk normal untuk meningkatkan integritas data dan mengurangi kejadian redundansi data.
Pemodelan data berkisar pada 2 teknik normalisasi utama yaitu:
-
Model data yang dinormalisasi
Seperti yang diterapkan pada data referensi, normalisasi membagi data menjadi beberapa koleksi dengan referensi antar koleksi baru. Pembaruan dokumen tunggal akan dikeluarkan untuk koleksi lain dan diterapkan sesuai dengan dokumen yang cocok. Ini memberikan representasi pembaruan data yang efisien dan biasanya digunakan untuk data yang cukup sering berubah.
-
Model data yang didenormalisasi
Data berisi dokumen yang disematkan sehingga membuat operasi baca cukup efisien. Namun, ini terkait dengan penggunaan ruang disk yang lebih banyak dan juga kesulitan untuk tetap sinkron. Konsep denormalisasi dapat diterapkan dengan baik pada subdokumen yang datanya tidak terlalu sering berubah.
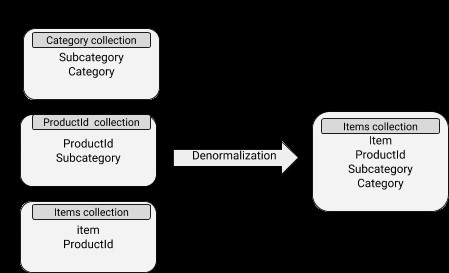
Skema MongoDB
Skema pada dasarnya adalah kerangka bidang yang diuraikan dan tipe data yang harus dimiliki setiap bidang untuk kumpulan data tertentu. Mempertimbangkan sudut pandang SQL, semua baris dirancang untuk memiliki kolom yang sama dan setiap kolom harus memiliki tipe data yang ditentukan. Namun, di MongoDB, kami memiliki Skema fleksibel secara default yang tidak memiliki kesesuaian yang sama untuk semua dokumen.
Skema Fleksibel
Skema fleksibel di MongoDB mendefinisikan bahwa dokumen tidak harus memiliki bidang atau tipe data yang sama, karena bidang dapat berbeda di seluruh dokumen dalam kumpulan. Keuntungan inti dengan konsep ini adalah bahwa seseorang dapat menambahkan bidang baru, menghapus yang sudah ada atau mengubah nilai bidang ke tipe baru dan karenanya memperbarui dokumen menjadi struktur baru.
Misalnya kita dapat memiliki 2 dokumen ini dalam koleksi yang sama:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}Di dokumen pertama, kami memiliki bidang usia sedangkan di dokumen kedua tidak ada bidang usia. Selanjutnya, tipe data untuk bidang ParentPhone adalah angka sedangkan pada dokumen kedua telah disetel ke false yang merupakan tipe boolean.
Fleksibilitas skema memfasilitasi pemetaan dokumen ke objek dan setiap dokumen dapat mencocokkan bidang data entitas yang diwakili.
Skema Kaku
Meskipun kami telah mengatakan bahwa dokumen-dokumen ini mungkin berbeda satu sama lain, terkadang Anda mungkin memutuskan untuk membuat skema yang kaku. Skema kaku akan menentukan bahwa semua dokumen dalam kumpulan akan berbagi struktur yang sama dan ini akan memberi Anda kesempatan yang lebih baik untuk menetapkan beberapa aturan validasi dokumen sebagai cara untuk meningkatkan integritas data selama operasi penyisipan dan pembaruan.
Tipe data skema
Saat menggunakan beberapa driver server untuk MongoDB seperti luwak, ada beberapa tipe data yang disediakan yang memungkinkan Anda untuk melakukan validasi data. Tipe data dasar adalah:
- Tali
- Nomor
- Boolean
- Tanggal
- Penyangga
- Id Objek
- Array
- Campur
- Desimal128
- Peta
Perhatikan contoh skema di bawah ini
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Contoh kasus penggunaan
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Validasi Skema
Sebanyak yang Anda dapat melakukan validasi data dari sisi aplikasi, selalu praktik yang baik untuk melakukan validasi dari ujung server juga. Kami mencapai ini dengan menggunakan aturan validasi skema.
Aturan-aturan ini diterapkan selama operasi penyisipan dan pembaruan. Mereka dideklarasikan berdasarkan koleksi selama proses pembuatan secara normal. Namun, Anda juga dapat menambahkan aturan validasi dokumen ke koleksi yang ada menggunakan perintah colMod dengan opsi validator, tetapi aturan ini tidak diterapkan ke dokumen yang ada hingga pembaruan diterapkan padanya.
Demikian juga, saat membuat koleksi baru menggunakan perintah db.createCollection() Anda dapat mengeluarkan opsi validator. Lihatlah contoh ini saat membuat koleksi untuk siswa. Dari versi 3.6, MongoDB mendukung validasi Skema JSON sehingga yang Anda butuhkan hanyalah menggunakan operator $jsonSchema.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})Dalam desain skema ini, jika kita mencoba memasukkan dokumen baru seperti:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})Fungsi callback akan mengembalikan kesalahan di bawah ini, karena beberapa aturan validasi yang dilanggar seperti nilai tahun yang diberikan tidak dalam batas yang ditentukan.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Selanjutnya, Anda dapat menambahkan ekspresi kueri ke opsi validasi menggunakan operator kueri kecuali $where, $text, near dan $nearSphere, yaitu:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Tingkat Validasi Skema
Seperti disebutkan sebelumnya, validasi dikeluarkan untuk operasi tulis, secara normal.
Namun, validasi juga dapat diterapkan pada dokumen yang sudah ada.
Ada 3 tingkat validasi:
- Ketat:ini adalah tingkat validasi MongoDB default dan menerapkan aturan validasi untuk semua sisipan dan pembaruan.
- Sedang:Aturan validasi diterapkan selama penyisipan, pembaruan, dan dokumen yang sudah ada yang memenuhi kriteria validasi saja.
- Nonaktif:level ini menetapkan aturan validasi untuk skema yang diberikan ke nol sehingga tidak ada validasi yang akan dilakukan pada dokumen.
Contoh:
Mari masukkan data di bawah ini ke dalam koleksi klien.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Jika kita menerapkan tingkat validasi sedang menggunakan:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Aturan validasi hanya akan diterapkan pada dokumen dengan _id 1 karena akan cocok dengan semua kriteria.
Untuk dokumen kedua, karena aturan validasi tidak memenuhi kriteria yang dikeluarkan, dokumen tersebut tidak akan divalidasi.
Tindakan Validasi Skema
Setelah melakukan validasi pada dokumen, mungkin ada beberapa yang melanggar aturan validasi. Selalu ada kebutuhan untuk memberikan tindakan saat ini terjadi.
MongoDB menyediakan dua tindakan yang dapat dikeluarkan untuk dokumen yang gagal dalam aturan validasi:
- Kesalahan:ini adalah tindakan MongoDB default, yang menolak penyisipan atau pembaruan apa pun jika melanggar kriteria validasi.
-
Peringatkan:Tindakan ini akan mencatat pelanggaran di log MongoDB, tetapi memungkinkan operasi penyisipan atau pembaruan diselesaikan. Misalnya:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Jika kita mencoba memasukkan dokumen seperti ini:
db.students.insert( { name: "Amanda", status: "Updated" } );Gpa hilang terlepas dari fakta bahwa itu adalah bidang yang diperlukan dalam desain skema, tetapi karena tindakan validasi telah diatur untuk memperingatkan, dokumen akan disimpan dan pesan kesalahan akan dicatat di log MongoDB.



