Salah satu kekhawatiran terbesar saat menangani dan mengelola database adalah kompleksitas data dan ukurannya. Seringkali, organisasi khawatir tentang bagaimana menangani pertumbuhan dan mengelola dampak pertumbuhan karena manajemen basis data gagal. Kompleksitas datang dengan kekhawatiran yang tidak ditangani pada awalnya dan tidak terlihat, atau dapat diabaikan karena teknologi yang digunakan saat ini harus dapat menangani dengan sendirinya. Mengelola database yang kompleks dan besar harus direncanakan dengan tepat terutama ketika jenis data yang Anda kelola atau tangani diperkirakan akan tumbuh secara besar-besaran baik yang diantisipasi atau secara tidak terduga. Tujuan utama dari perencanaan adalah untuk menghindari bencana yang tidak diinginkan, atau haruskah kita katakan jauhkan diri dari asap! Di blog ini kita akan membahas bagaimana mengelola database besar secara efisien.
Ukuran Data Penting
Ukuran basis data penting karena berdampak pada kinerja dan metodologi pengelolaannya. Bagaimana data diproses dan disimpan akan berkontribusi pada bagaimana database akan dikelola, yang berlaku untuk data transit dan data tidak aktif. Bagi banyak organisasi besar, data adalah emas, dan pertumbuhan data dapat memiliki perubahan drastis dalam prosesnya. Oleh karena itu, sangat penting untuk memiliki rencana sebelumnya untuk menangani pertumbuhan data dalam database.
Dalam pengalaman saya bekerja dengan database, saya telah menyaksikan pelanggan mengalami masalah dalam menangani penalti kinerja dan mengelola pertumbuhan data yang ekstrem. Muncul pertanyaan apakah akan menormalkan tabel vs mendenormalisasi tabel.
Menormalkan Tabel
Menormalkan tabel mempertahankan integritas data, mengurangi redundansi, dan memudahkan pengorganisasian data menjadi cara yang lebih efisien untuk mengelola, menganalisis, dan mengekstrak. Bekerja dengan tabel yang dinormalisasi menghasilkan efisiensi, terutama saat menganalisis aliran data dan mengambil data baik dengan pernyataan SQL atau bekerja dengan bahasa pemrograman seperti antarmuka C/C++, Java, Go, Ruby, PHP, atau Python dengan Konektor MySQL.
Meskipun masalah dengan tabel yang dinormalisasi memiliki penalti kinerja dan dapat memperlambat kueri karena serangkaian gabungan saat mengambil data. Sedangkan tabel yang didenormalisasi, semua yang harus Anda pertimbangkan untuk pengoptimalan bergantung pada indeks atau kunci utama untuk menyimpan data ke dalam buffer untuk pengambilan yang lebih cepat daripada melakukan pencarian beberapa disk. Tabel yang didenormalisasi tidak memerlukan penggabungan, tetapi mengorbankan integritas data, dan ukuran database cenderung semakin besar.
Bila database Anda besar, pertimbangkan untuk memiliki DDL (Data Definition Language) untuk tabel database Anda di MySQL/MariaDB. Menambahkan kunci utama atau unik untuk tabel Anda memerlukan pembuatan ulang tabel. Mengubah tipe data kolom juga memerlukan pembuatan ulang tabel karena algoritme yang dapat diterapkan hanya ALGORITHM=COPY.
Jika Anda melakukan ini di lingkungan produksi Anda, itu bisa jadi menantang. Gandakan tantangan jika meja Anda besar. Bayangkan satu juta atau satu miliar jumlah baris. Anda tidak dapat menerapkan pernyataan ALTER TABLE langsung ke tabel Anda. Itu dapat memblokir semua lalu lintas masuk yang perlu mengakses tabel saat Anda menerapkan DDL. Namun, ini dapat dikurangi dengan menggunakan pt-online-schema-change atau gh-ost yang hebat. Namun demikian, hal tersebut membutuhkan pemantauan dan pemeliharaan saat melakukan proses DDL.
Sharding dan Partisi
Dengan sharding dan partisi, ini membantu memisahkan atau mengelompokkan data menurut identitas logisnya. Misalnya, dengan memisahkan berdasarkan tanggal, urutan abjad, negara, negara bagian, atau kunci utama berdasarkan rentang yang diberikan. Ini membantu ukuran database Anda agar dapat dikelola. Pertahankan ukuran database Anda hingga batasnya sehingga dapat dikelola oleh organisasi dan tim Anda. Mudah untuk diukur jika perlu atau mudah dikelola, terutama saat terjadi bencana.
Saat kami mengatakan dapat dikelola, pertimbangkan juga sumber daya kapasitas server Anda dan juga tim teknik Anda. Anda tidak dapat bekerja dengan data besar dan besar dengan sedikit insinyur. Bekerja dengan data besar seperti 1000 database dengan kumpulan data dalam jumlah besar membutuhkan banyak waktu. Keterampilan bijaksana dan keahlian adalah suatu keharusan. Jika biaya menjadi masalah, itulah saatnya Anda dapat memanfaatkan layanan pihak ketiga yang menawarkan layanan terkelola atau konsultasi atau dukungan berbayar agar pekerjaan teknik semacam itu dapat dipenuhi.
Kumpulan dan Kumpulan Karakter
Set karakter dan susunan memengaruhi penyimpanan dan kinerja data, terutama pada kumpulan karakter dan susunan yang dipilih. Setiap rangkaian karakter dan susunan memiliki tujuannya dan sebagian besar membutuhkan panjang yang berbeda. Jika Anda memiliki tabel yang memerlukan kumpulan karakter dan susunan lainnya karena pengkodean karakter, data akan disimpan dan diproses untuk database dan tabel Anda atau bahkan dengan kolom.
Ini memengaruhi cara mengelola database Anda secara efektif. Ini memengaruhi penyimpanan data Anda dan juga kinerja seperti yang dinyatakan sebelumnya. Jika Anda telah memahami jenis karakter yang akan diproses oleh aplikasi Anda, perhatikan set karakter dan susunan yang akan digunakan. Jenis set karakter LATIN sebagian besar akan cukup untuk jenis karakter alfanumerik yang akan disimpan dan diproses.
Jika tidak dapat dihindari, sharding dan partisi membantu setidaknya mengurangi dan membatasi data untuk menghindari terlalu banyak data di server database Anda. Mengelola data yang sangat besar pada satu server database dapat memengaruhi efisiensi, terutama untuk tujuan pencadangan, bencana dan pemulihan, atau pemulihan data juga jika terjadi kerusakan data atau kehilangan data.
Kompleksitas Basis Data Mempengaruhi Kinerja
Basis data yang besar dan kompleks cenderung memiliki faktor dalam hal penalti kinerja. Kompleks, dalam hal ini, berarti konten database Anda terdiri dari persamaan matematika, koordinat, atau catatan numerik dan keuangan. Sekarang campur catatan ini dengan kueri yang secara agresif menggunakan fungsi matematika asli dari databasenya. Lihat contoh kueri SQL (kompatibel dengan MySQL/MariaDB) di bawah ini,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Pertimbangkan bahwa kueri ini diterapkan pada tabel mulai dari satu juta baris. Ada kemungkinan besar bahwa ini dapat menghentikan server, dan ini bisa memakan banyak sumber daya yang menyebabkan bahaya bagi stabilitas cluster basis data produksi Anda. Kolom yang terlibat cenderung diindeks untuk mengoptimalkan dan membuat kueri ini berkinerja. Namun, menambahkan indeks ke kolom yang direferensikan untuk kinerja yang optimal tidak menjamin efisiensi pengelolaan database besar Anda.
Saat menangani kompleksitas, cara yang lebih efisien adalah dengan menghindari penggunaan persamaan matematika kompleks yang ketat dan penggunaan agresif dari kemampuan komputasi kompleks bawaan ini. Ini dapat dioperasikan dan diangkut melalui perhitungan kompleks menggunakan bahasa pemrograman backend daripada menggunakan database. Jika Anda memiliki perhitungan yang kompleks, maka mengapa tidak menyimpan persamaan ini dalam database, mengambil kueri, mengaturnya menjadi lebih mudah untuk dianalisis atau di-debug saat dibutuhkan.
Apakah Anda Menggunakan Mesin Database yang Tepat?
Struktur data memengaruhi kinerja server database berdasarkan kombinasi kueri yang diberikan dan catatan yang dibaca atau diambil dari tabel. Mesin basis data dalam MySQL/MariaDB mendukung InnoDB dan MyISAM yang menggunakan B-Trees, sedangkan mesin basis data NDB atau Memori menggunakan Pemetaan Hash. Struktur data ini memiliki notasi asimtotiknya yang terakhir mengekspresikan kinerja algoritma yang digunakan oleh struktur data ini. Kami menyebutnya dalam Ilmu Komputer sebagai notasi Big O yang menggambarkan kinerja atau kompleksitas suatu algoritma. Mengingat bahwa InnoDB dan MyISAM menggunakan B-Trees, ia menggunakan O(log n) untuk pencarian. Sedangkan Hash Tables atau Hash Maps menggunakan O(n). Keduanya berbagi kasus rata-rata dan terburuk untuk kinerjanya dengan notasinya.
Sekarang kembali ke mesin tertentu, mengingat struktur data mesin, query yang akan diterapkan berdasarkan data target yang akan diambil tentu saja mempengaruhi kinerja server database Anda. Tabel hash tidak dapat melakukan pencarian rentang, sedangkan B-Trees sangat efisien untuk melakukan jenis pencarian ini dan juga dapat menangani data dalam jumlah besar.
Dengan menggunakan mesin yang tepat untuk data yang Anda simpan, Anda perlu mengidentifikasi jenis kueri yang Anda terapkan untuk data spesifik yang Anda simpan ini. Jenis logika apa yang harus dirumuskan oleh data ini saat diubah menjadi logika bisnis.
Berurusan dengan 1000 atau ribuan basis data, menggunakan mesin yang tepat dalam kombinasi kueri dan data yang ingin Anda ambil dan simpan akan memberikan kinerja yang baik. Mengingat bahwa Anda telah menentukan dan menganalisis persyaratan Anda untuk tujuan lingkungan database yang tepat.
Alat yang Tepat untuk Mengelola Database Besar
Sangat sulit dan sulit untuk mengelola database yang sangat besar tanpa platform yang solid yang dapat Anda andalkan. Bahkan dengan insinyur database yang baik dan terampil, secara teknis server database yang Anda gunakan rentan terhadap kesalahan manusia. Satu kesalahan dari perubahan apa pun pada parameter dan variabel konfigurasi Anda dapat mengakibatkan perubahan drastis yang menyebabkan penurunan kinerja server.
Melakukan pencadangan ke basis data Anda pada basis data yang sangat besar terkadang bisa menjadi tantangan. Ada kejadian bahwa pencadangan mungkin gagal karena beberapa alasan aneh. Biasanya, kueri yang dapat menghentikan server tempat pencadangan berjalan menyebabkan kegagalan. Jika tidak, Anda harus menyelidiki penyebabnya.
Menggunakan otomatisasi seperti Chef, Puppet, Ansible, Terraform, atau SaltStack dapat digunakan sebagai IaC Anda untuk memberikan tugas yang lebih cepat untuk dilakukan. Saat menggunakan alat pihak ketiga lainnya juga untuk membantu Anda memantau dan menyediakan gambar grafik berkualitas tinggi. Sistem pemberitahuan peringatan dan alarm juga sangat penting untuk memberi tahu Anda dari masalah yang dapat terjadi mulai dari peringatan hingga tingkat status kritis. Di sinilah ClusterControl sangat berguna dalam situasi seperti ini.
ClusterControl menawarkan kemudahan untuk mengelola database dalam jumlah besar atau bahkan dengan tipe lingkungan yang di-shard. Ini telah diuji dan dipasang ribuan kali dan telah memasuki produksi yang menyediakan alarm dan pemberitahuan kepada DBA, insinyur, atau DevOps yang mengoperasikan lingkungan database. Mulai dari pementasan atau pengembangan, QA, hingga lingkungan produksi.
ClusterControl juga dapat melakukan pencadangan dan pemulihan. Bahkan dengan database besar, ini bisa efisien dan mudah dikelola karena UI menyediakan penjadwalan dan juga memiliki opsi untuk mengunggahnya ke cloud (AWS, Google Cloud, dan Azure).
Ada juga verifikasi cadangan dan banyak opsi seperti enkripsi dan kompresi. Lihat screenshot di bawah ini misalnya (membuat Backup untuk MySQL menggunakan Xtrabackup):
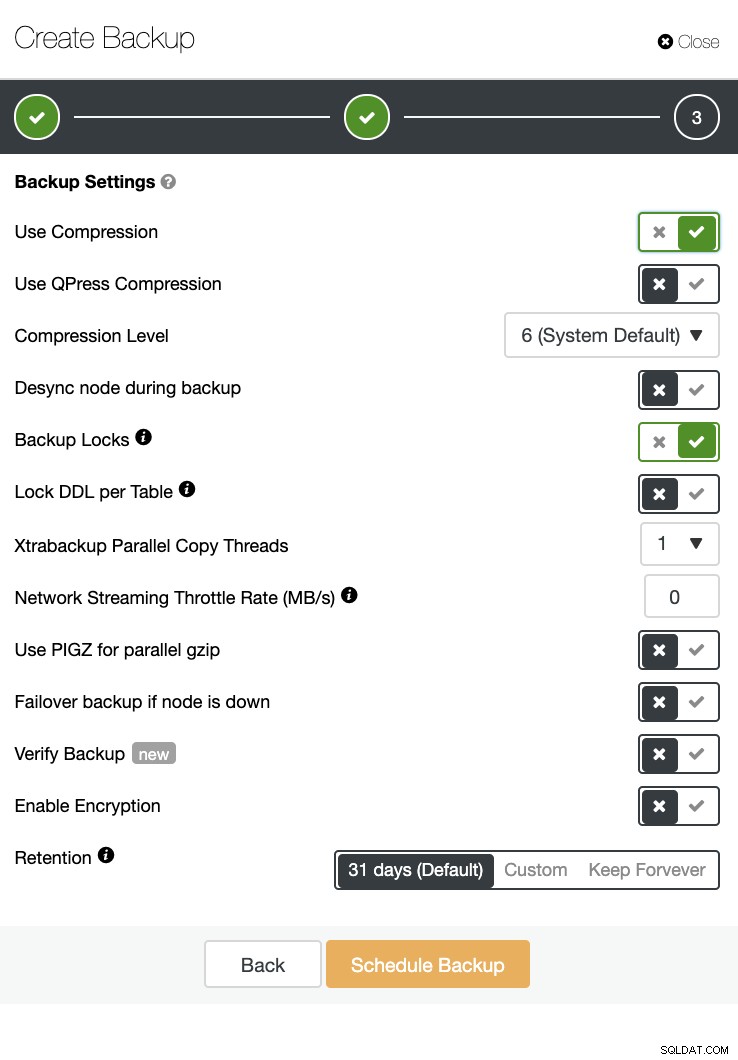
Kesimpulan
Mengelola database besar seperti seribu atau lebih dapat dilakukan secara efisien, tetapi harus ditentukan dan dipersiapkan sebelumnya. Menggunakan alat yang tepat seperti otomatisasi atau bahkan berlangganan layanan terkelola sangat membantu. Meskipun menimbulkan biaya, perputaran layanan dan anggaran yang harus dikeluarkan untuk memperoleh insinyur yang terampil dapat dikurangi selama alat yang tepat tersedia.



