Bersemangat untuk mempelajari setiap dan segala sesuatu tentang Kluster Hadoop?
Hadoop adalah kerangka kerja perangkat lunak untuk menganalisis dan menyimpan sejumlah besar data di seluruh kelompok perangkat keras komoditas. Pada artikel ini, kita akan mempelajari sebuah Hadoop Cluster.
Mari kita mulai dengan pengenalan Cluster.
Apa itu Cluster?
Cluster adalah kumpulan node. Node tidak lain adalah titik koneksi/persimpangan dalam jaringan.
Cluster komputer adalah kumpulan komputer yang terhubung dengan jaringan, dapat berkomunikasi satu sama lain, dan bekerja sebagai satu sistem.
Apa itu Hadoop Cluster?
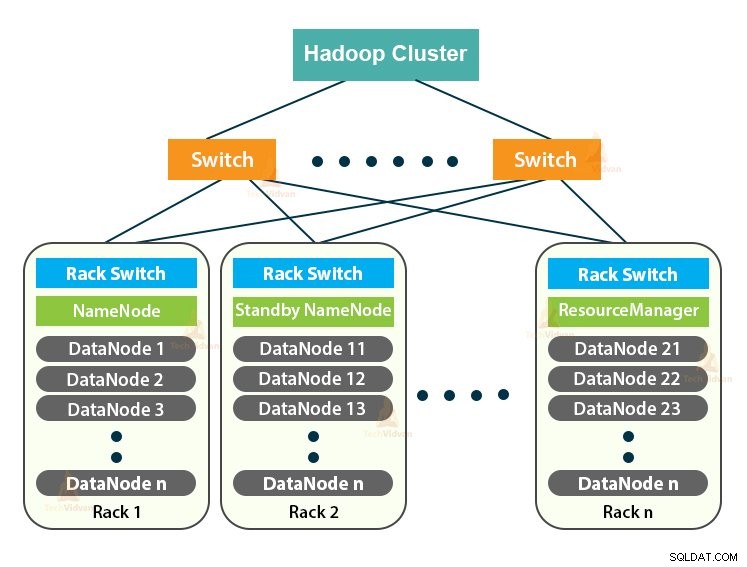
Hadoop Cluster hanyalah sebuah cluster komputer yang digunakan untuk menangani sejumlah besar data secara terdistribusi.
Ini adalah cluster komputasi yang dirancang untuk menyimpan serta menganalisis sejumlah besar data tidak terstruktur atau terstruktur dalam lingkungan komputasi terdistribusi.
Cluster Hadoop juga dikenal sebagai Sistem berbagi-tidak ada karena tidak ada yang dibagi antara node dalam cluster kecuali bandwidth jaringan. Ini mengurangi latensi pemrosesan.
Jadi, ketika ada kebutuhan untuk memproses kueri pada sejumlah besar data, latensi seluruh cluster diminimalkan.
Sekarang mari kita pelajari Arsitektur Cluster Hadoop.
Arsitektur Klaster Hadoop
Hadoop Cluster mengikuti arsitektur master-slave. Ini terdiri dari node master, node slave, dan node klien.
1. Master di Hadoop Cluster
Master di Hadoop Cluster adalah mesin berdaya tinggi dengan konfigurasi memori dan CPU yang tinggi. Dua daemon yaitu NameNode dan ResourceManager berjalan di master node.
a. Fungsi NameNode
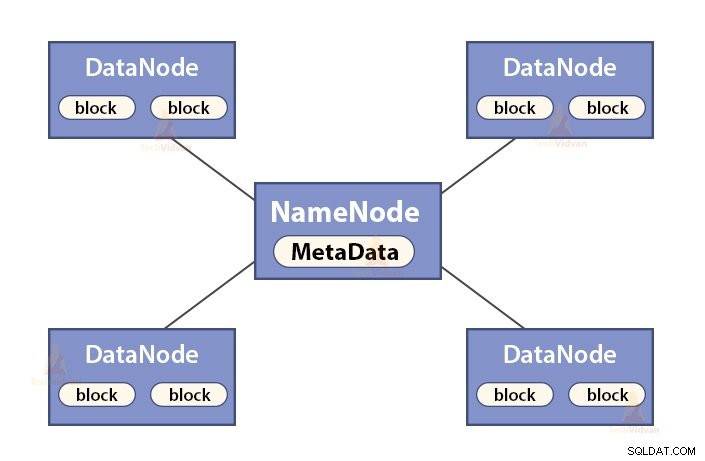
NameNode adalah master node di Hadoop HDFS . NameNode mengelola namespace sistem file. Ini menyimpan meta-data sistem file dalam memori untuk pengambilan cepat. Oleh karena itu, ini harus dikonfigurasi pada mesin kelas atas.
Fungsi NameNode adalah:
- Mengelola ruang nama sistem file
- Menyimpan meta-data tentang blok file, lokasi blok, izin, dll.
- Ini menjalankan operasi ruang nama sistem file seperti membuka, menutup, mengganti nama file dan direktori, dll.
- Ini memelihara dan mengelola DataNode.
b. Fungsi Manajer Sumber Daya
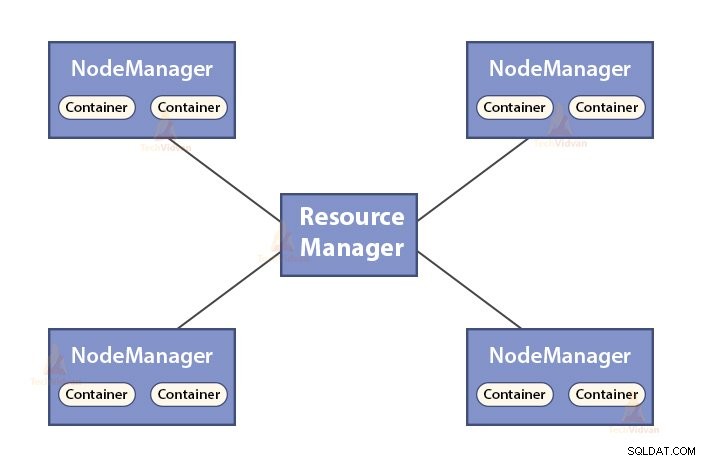
- ResourceManager adalah daemon master YARN.
- ResourceManager menengahi sumber daya di antara semua aplikasi dalam sistem.
- Ini melacak node hidup dan mati di cluster.
2. Budak di Kelompok Hadoop
Budak di Hadoop Cluster adalah perangkat keras komoditas yang murah. Dua daemon yaitu DataNodes dan YARN NodeManager berjalan pada node slave.
a. Fungsi DataNodes
- DataNodes menyimpan data bisnis yang sebenarnya. Ini menyimpan blok file.
- Ini melakukan pembuatan blok, penghapusan, replikasi berdasarkan instruksi dari NameNode.
- DataNode bertanggung jawab untuk melayani operasi baca/tulis klien.
b. Fungsi NodeManager
- NodeManager adalah daemon budak dari YARN.
- Ini bertanggung jawab atas container, memantau penggunaan sumber dayanya (seperti CPU, disk, memori, jaringan) dan melaporkan hal yang sama ke ResourceManager.
- NodeManager juga memeriksa kondisi node yang dijalankannya.
3. Node Klien di Hadoop Cluster
Node Klien di Hadoop bukan node master atau node budak. Mereka telah menginstal Hadoop dengan semua pengaturan cluster.
Fungsi node Klien
- Node klien memuat data ke dalam Hadoop Cluster.
- Ini mengirimkan pekerjaan MapReduce, menjelaskan bagaimana data itu harus diproses.
- Ambil hasil pekerjaan setelah pemrosesan selesai.
Kita dapat memperbesar Cluster Hadoop dengan menambahkan lebih banyak node. Hal ini membuat Hadoop skala linier . Dengan setiap penambahan node, kami mendapatkan peningkatan throughput yang sesuai. Jika kita memiliki 'n' node, maka menambahkan 1 node memberikan (1/n) daya komputasi tambahan.
Kluster Hadoop Node Tunggal VS Kluster Hadoop Multi Node
1. Kluster Hadoop Node Tunggal
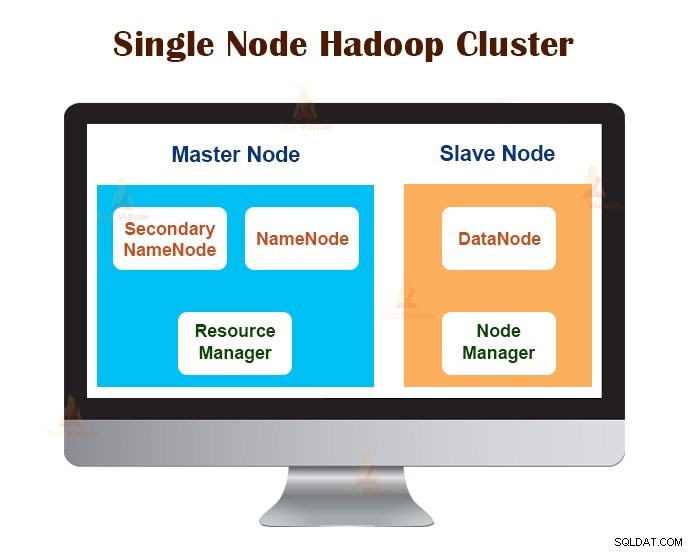
Cluster Hadoop Node Tunggal digunakan pada satu mesin. Semua daemon seperti NameNode, DataNode, ResourceManager, NodeManager berjalan di mesin/host yang sama.
Dalam pengaturan cluster node tunggal, semuanya berjalan pada satu instance JVM. Pengguna Hadoop tidak perlu membuat pengaturan konfigurasi apa pun kecuali untuk mengatur variabel JAVA_HOME.
Faktor replikasi default untuk kluster Hadoop node tunggal selalu 1.
2. Kluster Hadoop Multi-Node
Multi-Node Hadoop Cluster di-deploy di beberapa mesin. Semua daemon di cluster Hadoop multi-node aktif dan berjalan di mesin/host yang berbeda.
Sebuah cluster Hadoop multi-node mengikuti arsitektur master-slave. Namenode daemon dan ResourceManager berjalan di node master, yang merupakan mesin komputer kelas atas.
Daemon DataNodes dan NodeManager berjalan pada node slave (node pekerja), yang merupakan perangkat keras komoditas yang murah.
Dalam cluster Hadoop multi-node, mesin slave dapat hadir di lokasi mana pun terlepas dari lokasi lokasi fisik server master.
Protokol Komunikasi yang digunakan di Hadoop Cluster
Protokol komunikasi HDFS berlapis di atas protokol TCP/IP. Klien membuat koneksi dengan NameNode melalui port TCP yang dapat dikonfigurasi pada mesin NameNode.
Hadoop Cluster membuat koneksi ke klien melalui ClientProtocol. Selain itu, DataNode berbicara dengan NameNode menggunakan DataNode Protocol.
Abstraksi Remote Procedure Call (RPC) membungkus Protokol Klien dan protokol DataNode. Secara desain, NameNode tidak memulai RPC apa pun. Itu hanya menanggapi permintaan RPC yang dikeluarkan oleh klien atau DataNodes.
Praktik Terbaik untuk membangun Hadoop Cluster
Performa Hadoop Cluster bergantung pada berbagai faktor berdasarkan sumber daya perangkat keras berdimensi baik yang menggunakan CPU, memori, bandwidth jaringan, hard drive, dan lapisan perangkat lunak lain yang dikonfigurasi dengan baik.
Membangun Hadoop Cluster adalah pekerjaan yang tidak sepele. Hal ini memerlukan pertimbangan berbagai faktor seperti memilih perangkat keras yang tepat, menentukan ukuran Cluster Hadoop, dan mengonfigurasi Cluster Hadoop.
Sekarang mari kita lihat masing-masing secara detail.
1. Memilih Perangkat Keras yang Tepat untuk Hadoop Cluster
Banyak organisasi, saat menyiapkan infrastruktur Hadoop, berada dalam kesulitan karena mereka tidak mengetahui jenis mesin yang perlu mereka beli untuk menyiapkan lingkungan Hadoop yang dioptimalkan, dan konfigurasi ideal yang harus mereka gunakan.
Untuk memilih perangkat keras yang tepat untuk Hadoop Cluster, kita harus mempertimbangkan poin-poin berikut:
- Volume Data yang akan ditangani cluster.
- Jenis beban kerja yang akan ditangani cluster ( CPU terikat, I/O terikat).
- Metodologi penyimpanan data seperti wadah data, teknik kompresi data yang digunakan, jika ada.
- Kebijakan penyimpanan data, yaitu berapa lama kami ingin menyimpan data sebelum menghapusnya.
2. Mengukur Cluster Hadoop
Untuk menentukan ukuran Hadoop Cluster, volume data yang akan diproses oleh pengguna Hadoop di Hadoop Cluster harus menjadi pertimbangan utama.
Dengan mengetahui volume data yang akan diproses, membantu dalam memutuskan berapa banyak node yang akan dibutuhkan dalam memproses data secara efisien dan kapasitas memori yang dibutuhkan untuk setiap node. Harus ada keseimbangan antara kinerja dan biaya perangkat keras yang disetujui.
3. Mengonfigurasi Kluster Hadoop
Menemukan konfigurasi ideal untuk Hadoop Cluster bukanlah pekerjaan mudah. Kerangka kerja Hadoop harus disesuaikan dengan cluster yang dijalankannya dan juga dengan pekerjaannya.
Cara terbaik untuk memutuskan konfigurasi ideal untuk Hadoop Cluster adalah dengan menjalankan pekerjaan Hadoop dengan konfigurasi default yang tersedia untuk mendapatkan baseline. Setelah itu, kami dapat menganalisis file log riwayat pekerjaan untuk melihat apakah ada kelemahan sumber daya atau waktu yang dibutuhkan untuk menjalankan pekerjaan lebih tinggi dari yang diharapkan.
Jika sudah, maka ubah konfigurasinya. Mengulangi proses yang sama dapat menyesuaikan konfigurasi Hadoop Cluster yang paling sesuai dengan kebutuhan bisnis.
Kinerja Hadoop Cluster sangat bergantung pada sumber daya yang dialokasikan untuk daemon. Untuk konteks data kecil hingga menengah, Hadoop mencadangkan satu inti CPU pada setiap DataNode, sedangkan, untuk kumpulan data yang panjang, Hadoop mengalokasikan 2 inti CPU pada setiap DataNode untuk daemon HDFS dan MapReduce.
Pengelolaan Kluster Hadoop
Saat menerapkan Kluster Hadoop dalam produksi, terlihat bahwa Kluster Hadoop harus diskalakan di sepanjang semua dimensi yaitu volume, variasi, dan kecepatan.
Berbagai fitur yang harus dimiliki agar siap produksi adalah – ketersediaan sepanjang waktu, kuat, mudah dikelola, dan kinerja. Manajemen Hadoop Cluster adalah aspek utama dari inisiatif big data.
Alat terbaik untuk manajemen Hadoop Cluster harus memiliki fitur berikut:-
- Ini harus memastikan ketersediaan tinggi 24×7, penyediaan sumber daya, keamanan yang beragam, manajemen beban kerja, pemantauan kesehatan, pengoptimalan kinerja. Selain itu, perlu menyediakan penjadwalan tugas, manajemen kebijakan, pencadangan, dan pemulihan di satu atau beberapa node.
- Terapkan HDFS NameNode yang redundan dengan ketersediaan tinggi dengan penyeimbangan beban, hot standby, sinkronisasi ulang, dan auto-failover.
- Menegakkan kontrol berbasis kebijakan yang mencegah aplikasi apa pun mengambil bagian sumber daya yang tidak proporsional pada Cluster Hadoop yang sudah maksimal.
- Melakukan pengujian regresi untuk mengelola penerapan lapisan perangkat lunak apa pun di atas klaster Hadoop. Hal ini untuk memastikan bahwa pekerjaan atau data apa pun tidak akan mogok atau mengalami kemacetan dalam operasi sehari-hari.
Manfaat Hadoop Cluster
Berbagai manfaat yang diberikan oleh Hadoop Cluster adalah:
1. Dapat diskalakan
Cluster Hadoop dapat diskalakan. Kami dapat menambahkan sejumlah node ke Hadoop Cluster tanpa downtime dan tanpa usaha ekstra. Dengan setiap penambahan node, kami mendapatkan peningkatan throughput yang sesuai.
2. Kekokohan
Cluster Hadoop terkenal karena penyimpanannya yang andal. Itu dapat menyimpan data dengan andal, bahkan dalam kasus seperti kegagalan DataNode, kegagalan NameNode, dan partisi jaringan. DataNode secara berkala mengirimkan sinyal detak jantung ke NameNode.
Di partisi jaringan, satu set DataNodes akan terlepas dari NameNode karena NameNode tidak menerima detak jantung dari DataNodes ini. NameNode kemudian menganggap DataNode ini sebagai mati dan tidak meneruskan permintaan I/O apa pun kepada mereka.
Juga, faktor replikasi dari blok yang disimpan dalam DataNodes ini berada di bawah nilai yang ditentukan. Akibatnya, NameNode kemudian memulai replikasi blok-blok ini dan pulih dari kegagalan.
3. Penyeimbangan Kembali Klaster
Arsitektur Hadoop HDFS secara otomatis melakukan rebalancing cluster. Jika ruang kosong di DataNode berada di bawah tingkat ambang batas, arsitektur HDFS secara otomatis memindahkan beberapa data ke DataNode lain yang menyediakan cukup ruang.
4. Hemat biaya
Menyiapkan Hadoop Cluster hemat biaya karena terdiri dari perangkat keras komoditas yang murah. Setiap organisasi dapat dengan mudah menyiapkan Hadoop Cluster yang kuat tanpa menghabiskan banyak biaya untuk perangkat keras server yang mahal.
Juga, Hadoop Cluster dengan topologi penyimpanan terdistribusi mengatasi keterbatasan sistem tradisional. Penyimpanan terbatas dapat diperpanjang hanya dengan menambahkan unit penyimpanan tambahan yang murah ke sistem.
5. Fleksibel
Cluster Hadoop sangat fleksibel karena mereka dapat memproses data jenis apa pun, baik terstruktur, semi-terstruktur, atau tidak terstruktur dan dari berbagai ukuran mulai dari Gigabytes hingga Petabytes.
6. Pemrosesan Cepat
Di Hadoop Cluster, data dapat diproses secara paralel dalam lingkungan terdistribusi. Ini memberikan kemampuan pemrosesan data yang cepat ke Hadoop. Cluster Hadoop dapat memproses data Terabyte atau Petabyte dalam sepersekian detik.
7. Integritas Data
Untuk memeriksa kerusakan pada blok data karena perangkat lunak buggy, kesalahan pada perangkat penyimpanan, dll. Hadoop Cluster mengimplementasikan checksum pada setiap blok file. Jika menemukan blok yang rusak, ia mencarinya dari DataNode lain yang berisi replika dari blok yang sama. Dengan demikian, Hadoop Cluster menjaga integritas data.
Ringkasan
Setelah membaca artikel ini, kita dapat mengatakan bahwa Hadoop Cluster adalah cluster komputasi khusus yang dirancang untuk menganalisis dan menyimpan data besar. Hadoop Cluster mengikuti arsitektur master-slave.
Node master adalah mesin komputer kelas atas, dan node slave adalah mesin dengan konfigurasi CPU dan memori normal. Kita juga telah melihat bahwa Hadoop Cluster dapat diatur pada satu mesin yang disebut single-node Hadoop Cluster atau pada beberapa mesin yang disebut multi-node Hadoop Cluster.
Dalam artikel ini, kami juga telah membahas praktik terbaik yang harus diikuti saat membangun Cluster Hadoop. Kami juga telah melihat banyak keuntungan dari Hadoop Cluster, termasuk skalabilitas, fleksibilitas, efektivitas biaya, dll.



