Jelajahi arsitektur Hadoop, yang merupakan kerangka kerja yang paling banyak diadopsi untuk menyimpan dan memproses data besar.
Pada artikel ini, kita akan mempelajari Arsitektur Hadoop. Artikel tersebut menjelaskan arsitektur Hadoop dan komponen arsitektur Hadoop yaitu HDFS, MapReduce, dan YARN. Dalam artikel ini, kita akan menjelajahi arsitektur Hadoop secara detail, bersama dengan diagram Arsitektur Hadoop.
Mari kita mulai dengan Arsitektur Hadoop.
Arsitektur Hadoop
Tujuan merancang Hadoop adalah untuk mengembangkan kerangka kerja yang murah, andal, dan skalabel yang menyimpan dan menganalisis data besar yang sedang naik daun.
Apache Hadoop adalah kerangka kerja perangkat lunak yang dirancang oleh Apache Software Foundation untuk menyimpan dan memproses kumpulan data besar dengan berbagai ukuran dan format.
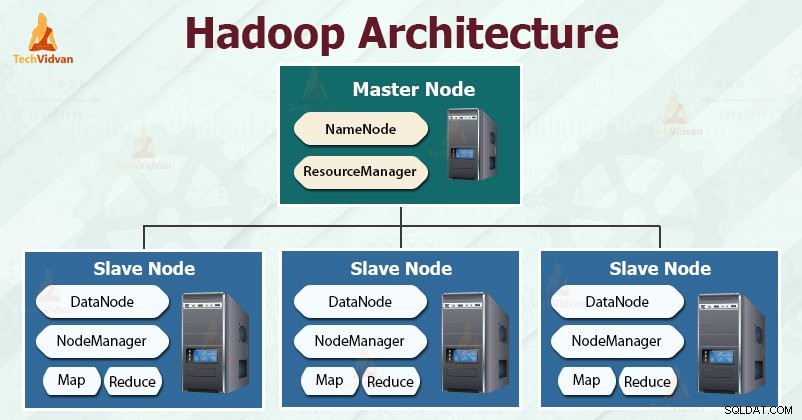
Hadoop mengikuti master-slave arsitektur untuk secara efektif menyimpan dan memproses sejumlah besar data. Node master memberikan tugas ke node slave.
Node budak bertanggung jawab untuk menyimpan data aktual dan melakukan komputasi/pemrosesan aktual. Node master bertanggung jawab untuk menyimpan metadata dan mengelola sumber daya di seluruh cluster.
Node budak menyimpan data bisnis yang sebenarnya, sedangkan master menyimpan metadata.
Arsitektur Hadoop terdiri dari tiga lapisan. Mereka adalah:
- Lapisan penyimpanan (HDFS)
- Lapisan Manajemen Sumber Daya (BENANG)
- Memproses lapisan (MapReduce)
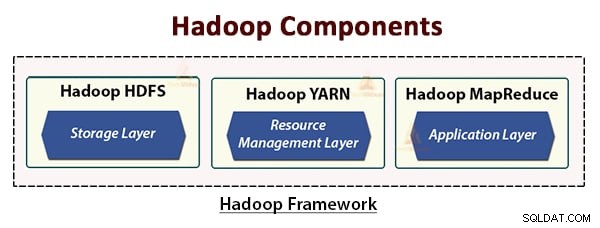
HDFS, YARN, dan MapReduce adalah komponen inti dari Hadoop Framework.
Mari kita pelajari ketiga komponen inti ini secara mendetail.
1. HDFS
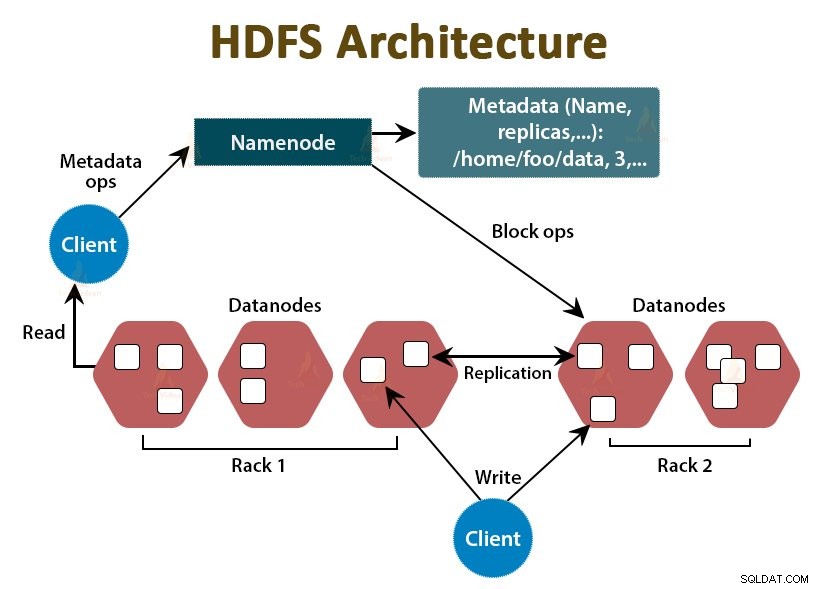
HDFS adalah Sistem File Terdistribusi Hadoop , yang berjalan pada perangkat keras komoditas murah. Ini adalah lapisan penyimpanan untuk Hadoop. File dalam HDFS dipecah menjadi potongan berukuran blok yang disebut blok data.
Blok-blok ini kemudian disimpan pada node slave di cluster. Ukuran blok adalah 128 MB secara default, yang dapat kami konfigurasikan sesuai kebutuhan kami.
Seperti Hadoop, HDFS juga mengikuti arsitektur master-slave. Ini terdiri dari dua daemon- NameNode dan DataNode. NameNode adalah daemon master yang berjalan di node master. DataNodes adalah daemon slave yang berjalan pada node slave.
NameNode
NameNode menyimpan metadata sistem file, yaitu, nama file, informasi tentang blok file, lokasi blok, izin, dll. NameNode mengelola Datanode.
DataNode
DataNodes adalah node budak yang menyimpan data bisnis yang sebenarnya. Ini melayani permintaan baca/tulis klien berdasarkan instruksi NameNode.
DataNodes menyimpan blok file, dan NameNode menyimpan metadata seperti lokasi blok, izin, dll.
2. Pengurangan Peta
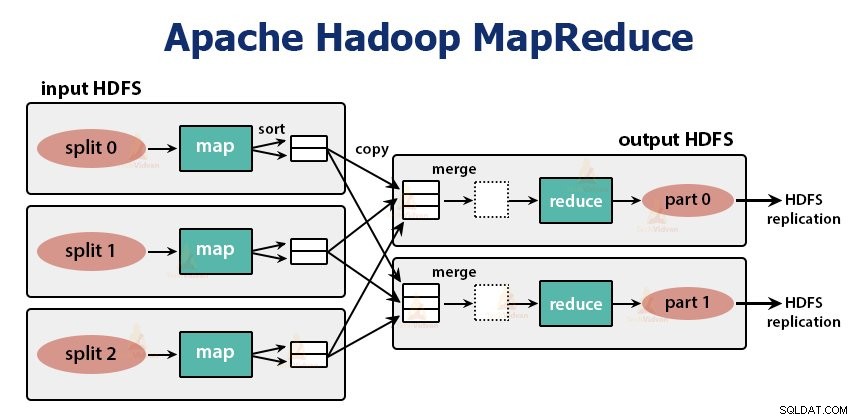
Ini adalah lapisan pemrosesan data Hadoop. Ini adalah kerangka kerja perangkat lunak untuk menulis aplikasi yang memproses data dalam jumlah besar (dalam jangkauan terabyte hingga petabyte) secara paralel pada klaster perangkat keras komoditas.
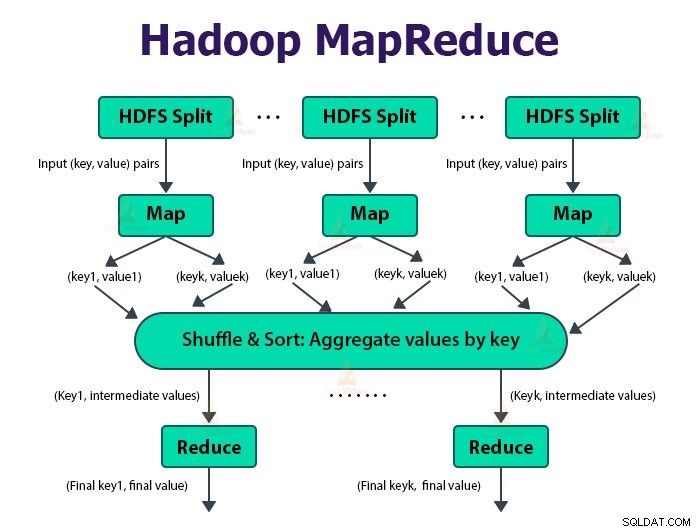
Kerangka kerja MapReduce bekerja pada pasangan
Pekerjaan MapReduce adalah unit pekerjaan yang ingin dilakukan klien. Pekerjaan MapReduce terutama terdiri dari data input, program MapReduce, dan informasi konfigurasi. Hadoop menjalankan tugas MapReduce dengan membaginya menjadi dua jenis tugas yaitu tugas peta dan mengurangi tugas . Hadoop YARN menjadwalkan tugas-tugas ini dan dijalankan pada node dalam cluster.
Karena beberapa kondisi yang tidak menguntungkan, jika tugas gagal, tugas tersebut akan dijadwalkan ulang secara otomatis pada node yang berbeda.
Pengguna mendefinisikan fungsi peta dan fungsi pengurangan untuk melakukan pekerjaan MapReduce.
Input ke fungsi peta dan output dari fungsi reduksi adalah pasangan kunci, nilai.
Fungsi tugas peta adalah memuat, mengurai, memfilter, dan mengubah data. Output dari tugas peta adalah input ke tugas pengurangan. Kurangi tugas kemudian lakukan pengelompokan dan agregasi pada output tugas peta.
Tugas MapReduce dilakukan dalam dua fase-
1. Fase peta
a. Pembaca Rekam
Hadoop membagi input ke pekerjaan MapReduce ke dalam pembagian ukuran tetap yang disebut pembagian input atau perpecahan. RecordReader mengubah pemisahan ini menjadi catatan dan mem-parsing data menjadi catatan tetapi tidak menguraikan catatan itu sendiri. Pembaca Rekaman menyediakan data ke fungsi mapper dalam pasangan nilai kunci.
b. Peta
Pada fase peta, Hadoop membuat satu tugas peta yang menjalankan fungsi yang ditentukan pengguna yang disebut fungsi peta untuk setiap catatan dalam pemisahan input. Ini menghasilkan nol atau beberapa pasangan nilai kunci perantara sebagai keluaran tugas peta.
Tugas peta menulis outputnya ke disk lokal. Output antara ini kemudian diproses oleh tugas reduksi yang menjalankan fungsi reduksi yang ditentukan pengguna untuk menghasilkan output akhir. Setelah pekerjaan selesai, output peta akan dihapus.
c. Penggabung
Input ke tugas pengurangan tunggal adalah output dari semua Pemeta yang merupakan output dari semua tugas peta. Hadoop memungkinkan pengguna untuk menentukan fungsi penggabung yang berjalan pada output peta.
Penggabung mengelompokkan data dalam fase peta sebelum meneruskannya ke Peredam. Ini menggabungkan output dari fungsi peta yang kemudian diteruskan sebagai input ke fungsi reduksi.
d. Pemisah
Ketika ada beberapa reduksi maka tugas peta mempartisi outputnya, masing-masing membuat satu partisi untuk setiap tugas reduksi. Di setiap partisi, mungkin ada banyak kunci dan nilai terkaitnya, tetapi catatan untuk setiap kunci yang diberikan semuanya berada dalam satu partisi.
Hadoop memungkinkan pengguna untuk mengontrol partisi dengan menentukan fungsi partisi yang ditentukan pengguna. Umumnya, ada Partitioner default yang memasukkan kunci menggunakan fungsi hash.
2. Kurangi fase:
Berbagai fase dalam mengurangi tugas adalah sebagai berikut:
a. Urutkan dan Acak:
Tugas Reducer dimulai dengan langkah acak dan sortir. Tujuan utama dari fase ini adalah untuk mengumpulkan kunci yang setara bersama-sama. Fase Sort and Shuffle mendownload data yang ditulis oleh partisi ke node tempat Reducer berjalan.
Ini mengurutkan setiap bagian data ke dalam daftar data yang besar. Kerangka kerja MapReduce melakukan pengurutan dan pengacakan ini sehingga kita dapat mengulanginya dengan mudah dalam tugas pengurangan.
mengurutkan dan mengacak dilakukan oleh framework secara otomatis. Pengembang melalui objek pembanding dapat memiliki kendali atas bagaimana kunci diurutkan dan dikelompokkan.
b. Kurangi:
Peredam yang merupakan fungsi pengurangan yang ditentukan pengguna bekerja sekali per pengelompokan kunci. Peredam menyaring, mengagregasi, dan menggabungkan data dalam beberapa cara berbeda. Setelah tugas pengurangan selesai, ini memberikan nol atau lebih pasangan nilai kunci ke OutputFormat. Output pengurangan tugas disimpan di Hadoop HDFS.
c. Format Keluaran
Dibutuhkan output peredam dan menulisnya ke file HDFS oleh RecordWriter. Secara default, ini memisahkan kunci, nilai dengan tab dan setiap record dengan karakter baris baru.
3. BENANG
YARN adalah singkatan dari Yet Another Resource Negotiator . Ini adalah lapisan manajemen sumber daya Hadoop. Itu diperkenalkan di Hadoop 2.
YARN dirancang dengan ide untuk membagi fungsionalitas penjadwalan pekerjaan dan manajemen sumber daya menjadi daemon yang terpisah. Ide dasarnya adalah memiliki ResourceManager global dan Master aplikasi per aplikasi di mana aplikasi dapat berupa satu pekerjaan atau DAG pekerjaan.
YARN terdiri dari ResourceManager, NodeManager, dan ApplicationMaster per aplikasi.
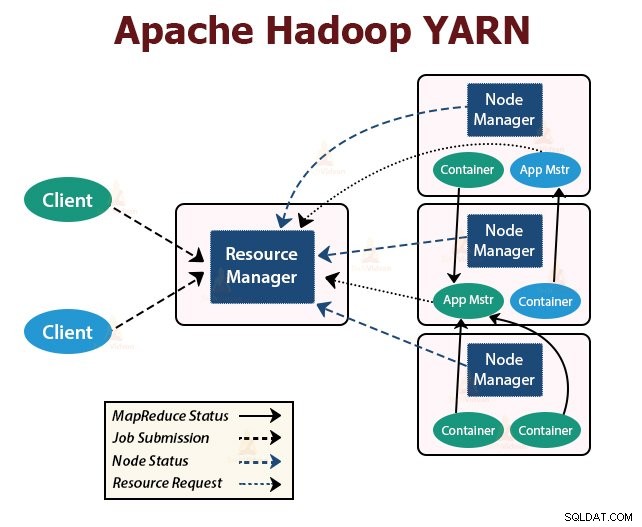
1. Manajer Sumber Daya
Ini menengahi sumber daya di antara semua aplikasi di cluster.
Ini memiliki dua komponen utama yaitu Scheduler dan ApplicationManager.
a. Penjadwal
- Penjadwal mengalokasikan sumber daya ke berbagai aplikasi yang berjalan di cluster, dengan mempertimbangkan kapasitas, antrian, dll.
- Ini adalah Penjadwal murni. Itu tidak memantau atau melacak status aplikasi.
- Scheduler tidak menjamin restart dari tugas yang gagal baik karena kegagalan aplikasi atau kegagalan perangkat keras.
- Ini melakukan penjadwalan berdasarkan kebutuhan sumber daya aplikasi.
b. Manajer Aplikasi
- Mereka bertanggung jawab untuk menerima kiriman pekerjaan.
- ApplicationManager menegosiasikan container pertama untuk mengeksekusi ApplicationMaster khusus aplikasi.
- Mereka menyediakan layanan untuk memulai ulang wadah ApplicationMaster jika gagal.
- ApplicationMaster per aplikasi bertanggung jawab untuk menegosiasikan container dari Scheduler. Ini melacak dan memantau status dan kemajuan mereka.
2. NodeManager:
NodeManager berjalan pada node slave. Ia bertanggung jawab atas container, memantau penggunaan resource mesin yaitu CPU, memori, disk, penggunaan jaringan, dan melaporkan hal yang sama ke ResourceManager atau Scheduler.
3. ApplicationMaster:
ApplicationMaster per-aplikasi adalah perpustakaan khusus kerangka kerja. Ini bertanggung jawab untuk menegosiasikan sumber daya dari ResourceManager. Ia bekerja dengan NodeManager untuk mengeksekusi dan memantau tugas.
Ringkasan
Pada artikel ini, kita telah mempelajari Arsitektur Hadoop. Hadoop mengikuti topologi master-slave. Node master memberikan tugas ke node slave. Arsitekturnya terdiri dari tiga lapisan yaitu HDFS, YARN, dan MapReduce.
HDFS adalah sistem file terdistribusi di Hadoop untuk menyimpan data besar. MapReduce adalah kerangka kerja pemrosesan untuk memproses data yang sangat besar di cluster Hadoop secara terdistribusi. YARN bertanggung jawab untuk mengelola sumber daya di antara aplikasi dalam cluster.
Daemon NameNode HDFS dan daemon YARN ResourceManager berjalan di master node di kluster Hadoop. Daemon HDFS DataNode dan YARN NodeManager berjalan pada node slave.
Kerangka kerja HDFS dan MapReduce berjalan pada kumpulan node yang sama, yang menghasilkan bandwidth agregat yang sangat tinggi di seluruh cluster.
Terus Belajar!!



